 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Evolutionary Search meets Probabilistic Numerics
Jul 09, 2025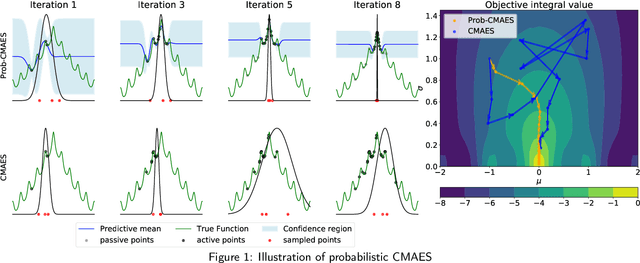
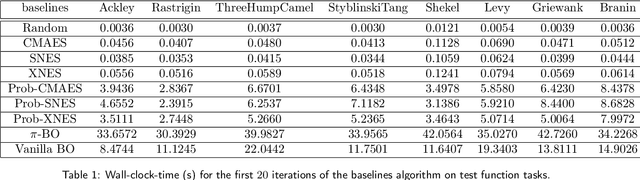
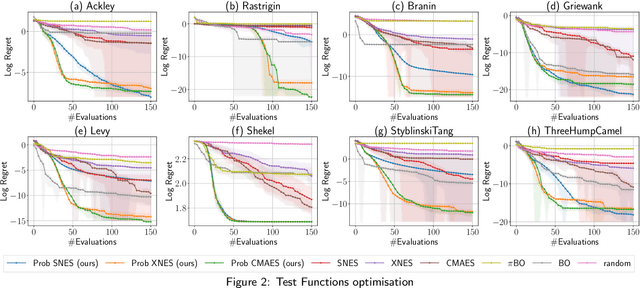
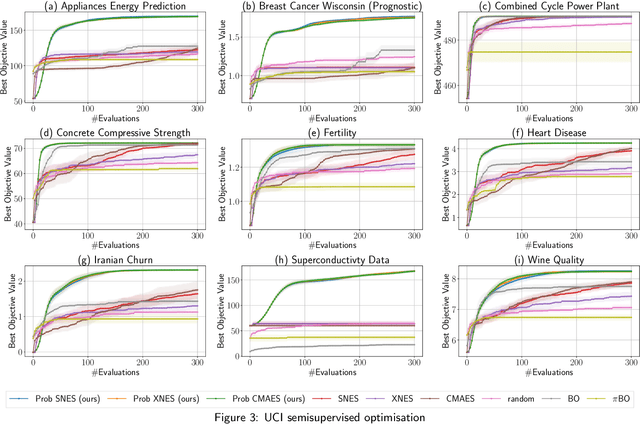
Zeroth-order local optimisation algorithms are essential for solving real-valued black-box optimisation problems. Among these, Natural Evolution Strategies (NES) represent a prominent class, particularly well-suited for scenarios where prior distributions are available. By optimising the objective function in the space of search distributions, NES algorithms naturally integrate prior knowledge during initialisation, making them effective in settings such as semi-supervised learning and user-prior belief frameworks. However, due to their reliance on random sampling and Monte Carlo estimates, NES algorithms can suffer from limited sample efficiency. In this paper, we introduce a novel class of algorithms, termed Probabilistic Natural Evolutionary Strategy Algorithms (ProbNES), which enhance the NES framework with Bayesian quadrature. We show that ProbNES algorithms consistently outperforms their non-probabilistic counterparts as well as global sample efficient methods such as Bayesian Optimisation (BO) or $\pi$BO across a wide range of tasks, including benchmark test functions, data-driven optimisation tasks, user-informed hyperparameter tuning tasks and locomotion tasks.
SOReL and TOReL: Two Methods for Fully Offline Reinforcement Learning
May 28, 2025Sample efficiency remains a major obstacle for real world adoption of reinforcement learning (RL): success has been limited to settings where simulators provide access to essentially unlimited environment interactions, which in reality are typically costly or dangerous to obtain. Offline RL in principle offers a solution by exploiting offline data to learn a near-optimal policy before deployment. In practice, however, current offline RL methods rely on extensive online interactions for hyperparameter tuning, and have no reliable bound on their initial online performance. To address these two issues, we introduce two algorithms. Firstly, SOReL: an algorithm for safe offline reinforcement learning. Using only offline data, our Bayesian approach infers a posterior over environment dynamics to obtain a reliable estimate of the online performance via the posterior predictive uncertainty. Crucially, all hyperparameters are also tuned fully offline. Secondly, we introduce TOReL: a tuning for offline reinforcement learning algorithm that extends our information rate based offline hyperparameter tuning methods to general offline RL approaches. Our empirical evaluation confirms SOReL's ability to accurately estimate regret in the Bayesian setting whilst TOReL's offline hyperparameter tuning achieves competitive performance with the best online hyperparameter tuning methods using only offline data. Thus, SOReL and TOReL make a significant step towards safe and reliable offline RL, unlocking the potential for RL in the real world. Our implementations are publicly available: https://github.com/CWibault/sorel\_torel.
Scalable Valuation of Human Feedback through Provably Robust Model Alignment
May 23, 2025Despite the importance of aligning language models with human preferences, crowd-sourced human feedback is often noisy -- for example, preferring less desirable responses -- posing a fundamental challenge to alignment. A truly robust alignment objective should yield identical model parameters even under severe label noise, a property known as redescending. We prove that no existing alignment methods satisfy this property. To address this, we propose H\"older-DPO, the first principled alignment loss with a provable redescending property, enabling estimation of the clean data distribution from noisy feedback. The aligned model estimates the likelihood of clean data, providing a theoretically grounded metric for dataset valuation that identifies the location and fraction of mislabels. This metric is gradient-free, enabling scalable and automated human feedback valuation without costly manual verification or clean validation dataset. H\"older-DPO achieves state-of-the-art robust alignment performance while accurately detecting mislabels in controlled datasets. Finally, we apply H\"older-DPO to widely used alignment datasets, revealing substantial noise levels and demonstrating that removing these mislabels significantly improves alignment performance across methods.
Just One Layer Norm Guarantees Stable Extrapolation
May 20, 2025In spite of their prevalence, the behaviour of Neural Networks when extrapolating far from the training distribution remains poorly understood, with existing results limited to specific cases. In this work, we prove general results -- the first of their kind -- by applying Neural Tangent Kernel (NTK) theory to analyse infinitely-wide neural networks trained until convergence and prove that the inclusion of just one Layer Norm (LN) fundamentally alters the induced NTK, transforming it into a bounded-variance kernel. As a result, the output of an infinitely wide network with at least one LN remains bounded, even on inputs far from the training data. In contrast, we show that a broad class of networks without LN can produce pathologically large outputs for certain inputs. We support these theoretical findings with empirical experiments on finite-width networks, demonstrating that while standard NNs often exhibit uncontrolled growth outside the training domain, a single LN layer effectively mitigates this instability. Finally, we explore real-world implications of this extrapolatory stability, including applications to predicting residue sizes in proteins larger than those seen during training and estimating age from facial images of underrepresented ethnicities absent from the training set.
A Physics-Inspired Optimizer: Velocity Regularized Adam
May 19, 2025We introduce Velocity-Regularized Adam (VRAdam), a physics-inspired optimizer for training deep neural networks that draws on ideas from quartic terms for kinetic energy with its stabilizing effects on various system dynamics. Previous algorithms, including the ubiquitous Adam, operate at the so called adaptive edge of stability regime during training leading to rapid oscillations and slowed convergence of loss. However, VRAdam adds a higher order penalty on the learning rate based on the velocity such that the algorithm automatically slows down whenever weight updates become large. In practice, we observe that the effective dynamic learning rate shrinks in high-velocity regimes, damping oscillations and allowing for a more aggressive base step size when necessary without divergence. By combining this velocity-based regularizer for global damping with per-parameter scaling of Adam to create a hybrid optimizer, we demonstrate that VRAdam consistently exceeds the performance against standard optimizers including AdamW. We benchmark various tasks such as image classification, language modeling, image generation and generative modeling using diverse architectures and training methodologies including Convolutional Neural Networks (CNNs), Transformers, and GFlowNets.
Meta-learning characteristics and dynamics of quantum systems
Mar 13, 2025While machine learning holds great promise for quantum technologies, most current methods focus on predicting or controlling a specific quantum system. Meta-learning approaches, however, can adapt to new systems for which little data is available, by leveraging knowledge obtained from previous data associated with similar systems. In this paper, we meta-learn dynamics and characteristics of closed and open two-level systems, as well as the Heisenberg model. Based on experimental data of a Loss-DiVincenzo spin-qubit hosted in a Ge/Si core/shell nanowire for different gate voltage configurations, we predict qubit characteristics i.e. $g$-factor and Rabi frequency using meta-learning. The algorithm we introduce improves upon previous state-of-the-art meta-learning methods for physics-based systems by introducing novel techniques such as adaptive learning rates and a global optimizer for improved robustness and increased computational efficiency. We benchmark our method against other meta-learning methods, a vanilla transformer, and a multilayer perceptron, and demonstrate improved performance.
Position: Ensuring mutual privacy is necessary for effective external evaluation of proprietary AI systems
Mar 03, 2025The external evaluation of AI systems is increasingly recognised as a crucial approach for understanding their potential risks. However, facilitating external evaluation in practice faces significant challenges in balancing evaluators' need for system access with AI developers' privacy and security concerns. Additionally, evaluators have reason to protect their own privacy - for example, in order to maintain the integrity of held-out test sets. We refer to the challenge of ensuring both developers' and evaluators' privacy as one of providing mutual privacy. In this position paper, we argue that (i) addressing this mutual privacy challenge is essential for effective external evaluation of AI systems, and (ii) current methods for facilitating external evaluation inadequately address this challenge, particularly when it comes to preserving evaluators' privacy. In making these arguments, we formalise the mutual privacy problem; examine the privacy and access requirements of both model owners and evaluators; and explore potential solutions to this challenge, including through the application of cryptographic and hardware-based approaches.
Bayesian Optimization for Building Social-Influence-Free Consensus
Feb 11, 2025We introduce Social Bayesian Optimization (SBO), a vote-efficient algorithm for consensus-building in collective decision-making. In contrast to single-agent scenarios, collective decision-making encompasses group dynamics that may distort agents' preference feedback, thereby impeding their capacity to achieve a social-influence-free consensus -- the most preferable decision based on the aggregated agent utilities. We demonstrate that under mild rationality axioms, reaching social-influence-free consensus using noisy feedback alone is impossible. To address this, SBO employs a dual voting system: cheap but noisy public votes (e.g., show of hands in a meeting), and more accurate, though expensive, private votes (e.g., one-to-one interview). We model social influence using an unknown social graph and leverage the dual voting system to efficiently learn this graph. Our theoretical findigns show that social graph estimation converges faster than the black-box estimation of agents' utilities, allowing us to reduce reliance on costly private votes early in the process. This enables efficient consensus-building primarily through noisy public votes, which are debiased based on the estimated social graph to infer social-influence-free feedback. We validate the efficacy of SBO across multiple real-world applications, including thermal comfort, team building, travel negotiation, and energy trading collaboration.
Learning to Forget: Bayesian Time Series Forecasting using Recurrent Sparse Spectrum Signature Gaussian Processes
Dec 27, 2024



The signature kernel is a kernel between time series of arbitrary length and comes with strong theoretical guarantees from stochastic analysis. It has found applications in machine learning such as covariance functions for Gaussian processes. A strength of the underlying signature features is that they provide a structured global description of a time series. However, this property can quickly become a curse when local information is essential and forgetting is required; so far this has only been addressed with ad-hoc methods such as slicing the time series into subsegments. To overcome this, we propose a principled, data-driven approach by introducing a novel forgetting mechanism for signatures. This allows the model to dynamically adapt its context length to focus on more recent information. To achieve this, we revisit the recently introduced Random Fourier Signature Features, and develop Random Fourier Decayed Signature Features (RFDSF) with Gaussian processes (GPs). This results in a Bayesian time series forecasting algorithm with variational inference, that offers a scalable probabilistic algorithm that processes and transforms a time series into a joint predictive distribution over time steps in one pass using recurrence. For example, processing a sequence of length $10^4$ steps in $\approx 10^{-2}$ seconds and in $< 1\text{GB}$ of GPU memory. We demonstrate that it outperforms other GP-based alternatives and competes with state-of-the-art probabilistic time series forecasting algorithms.
Bayesian Optimisation with Unknown Hyperparameters: Regret Bounds Logarithmically Closer to Optimal
Oct 14, 2024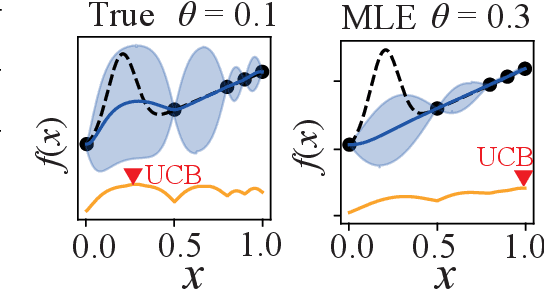

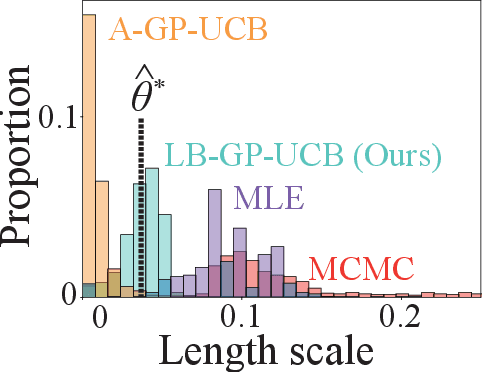
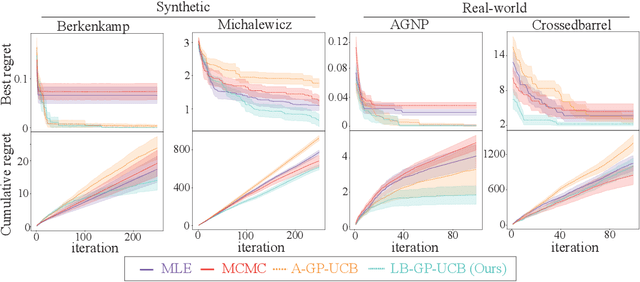
Bayesian Optimization (BO) is widely used for optimising black-box functions but requires us to specify the length scale hyperparameter, which defines the smoothness of the functions the optimizer will consider. Most current BO algorithms choose this hyperparameter by maximizing the marginal likelihood of the observed data, albeit risking misspecification if the objective function is less smooth in regions we have not yet explored. The only prior solution addressing this problem with theoretical guarantees was A-GP-UCB, proposed by Berkenkamp et al. (2019). This algorithm progressively decreases the length scale, expanding the class of functions considered by the optimizer. However, A-GP-UCB lacks a stopping mechanism, leading to over-exploration and slow convergence. To overcome this, we introduce Length scale Balancing (LB) - a novel approach, aggregating multiple base surrogate models with varying length scales. LB intermittently adds smaller length scale candidate values while retaining longer scales, balancing exploration and exploitation. We formally derive a cumulative regret bound of LB and compare it with the regret of an oracle BO algorithm using the optimal length scale. Denoting the factor by which the regret bound of A-GP-UCB was away from oracle as $g(T)$, we show that LB is only $\log g(T)$ away from oracle regret. We also empirically evaluate our algorithm on synthetic and real-world benchmarks and show it outperforms A-GP-UCB, maximum likelihood estimation and MCMC.