 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePosition: Ensuring mutual privacy is necessary for effective external evaluation of proprietary AI systems
Mar 03, 2025The external evaluation of AI systems is increasingly recognised as a crucial approach for understanding their potential risks. However, facilitating external evaluation in practice faces significant challenges in balancing evaluators' need for system access with AI developers' privacy and security concerns. Additionally, evaluators have reason to protect their own privacy - for example, in order to maintain the integrity of held-out test sets. We refer to the challenge of ensuring both developers' and evaluators' privacy as one of providing mutual privacy. In this position paper, we argue that (i) addressing this mutual privacy challenge is essential for effective external evaluation of AI systems, and (ii) current methods for facilitating external evaluation inadequately address this challenge, particularly when it comes to preserving evaluators' privacy. In making these arguments, we formalise the mutual privacy problem; examine the privacy and access requirements of both model owners and evaluators; and explore potential solutions to this challenge, including through the application of cryptographic and hardware-based approaches.
Open Problems in Machine Unlearning for AI Safety
Jan 09, 2025As AI systems become more capable, widely deployed, and increasingly autonomous in critical areas such as cybersecurity, biological research, and healthcare, ensuring their safety and alignment with human values is paramount. Machine unlearning -- the ability to selectively forget or suppress specific types of knowledge -- has shown promise for privacy and data removal tasks, which has been the primary focus of existing research. More recently, its potential application to AI safety has gained attention. In this paper, we identify key limitations that prevent unlearning from serving as a comprehensive solution for AI safety, particularly in managing dual-use knowledge in sensitive domains like cybersecurity and chemical, biological, radiological, and nuclear (CBRN) safety. In these contexts, information can be both beneficial and harmful, and models may combine seemingly harmless information for harmful purposes -- unlearning this information could strongly affect beneficial uses. We provide an overview of inherent constraints and open problems, including the broader side effects of unlearning dangerous knowledge, as well as previously unexplored tensions between unlearning and existing safety mechanisms. Finally, we investigate challenges related to evaluation, robustness, and the preservation of safety features during unlearning. By mapping these limitations and open challenges, we aim to guide future research toward realistic applications of unlearning within a broader AI safety framework, acknowledging its limitations and highlighting areas where alternative approaches may be required.
Hazards from Increasingly Accessible Fine-Tuning of Downloadable Foundation Models
Dec 22, 2023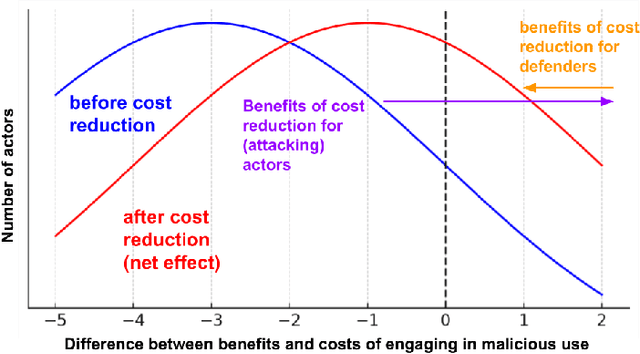
Public release of the weights of pretrained foundation models, otherwise known as downloadable access \citep{solaiman_gradient_2023}, enables fine-tuning without the prohibitive expense of pretraining. Our work argues that increasingly accessible fine-tuning of downloadable models may increase hazards. First, we highlight research to improve the accessibility of fine-tuning. We split our discussion into research that A) reduces the computational cost of fine-tuning and B) improves the ability to share that cost across more actors. Second, we argue that increasingly accessible fine-tuning methods may increase hazard through facilitating malicious use and making oversight of models with potentially dangerous capabilities more difficult. Third, we discuss potential mitigatory measures, as well as benefits of more accessible fine-tuning. Given substantial remaining uncertainty about hazards, we conclude by emphasizing the urgent need for the development of mitigations.