 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDependence of Equilibrium Propagation Training Success on Network Architecture
Jan 29, 2026The rapid rise of artificial intelligence has led to an unsustainable growth in energy consumption. This has motivated progress in neuromorphic computing and physics-based training of learning machines as alternatives to digital neural networks. Many theoretical studies focus on simple architectures like all-to-all or densely connected layered networks. However, these may be challenging to realize experimentally, e.g. due to connectivity constraints. In this work, we investigate the performance of the widespread physics-based training method of equilibrium propagation for more realistic architectural choices, specifically, locally connected lattices. We train an XY model and explore the influence of architecture on various benchmark tasks, tracking the evolution of spatially distributed responses and couplings during training. Our results show that sparse networks with only local connections can achieve performance comparable to dense networks. Our findings provide guidelines for further scaling up architectures based on equilibrium propagation in realistic settings.
Reinforcement Learning for Quantum Technology
Jan 26, 2026Many challenges arising in Quantum Technology can be successfully addressed using a set of machine learning algorithms collectively known as reinforcement learning (RL), based on adaptive decision-making through interaction with the quantum device. After a concise and intuitive introduction to RL aimed at a broad physics readership, we discuss the key ideas and core concepts in reinforcement learning with a particular focus on quantum systems. We then survey recent progress in RL in all relevant areas. We discuss state preparation in few- and many-body quantum systems, the design and optimization of high-fidelity quantum gates, and the automated construction of quantum circuits, including applications to variational quantum eigensolvers and architecture search. We further highlight the interactive capabilities of RL agents, emphasizing recent progress in quantum feedback control and quantum error correction, and briefly discuss quantum reinforcement learning as well as applications to quantum metrology. The review concludes with a discussion of open challenges -- such as scalability, interpretability, and integration with experimental platforms -- and outlines promising directions for future research. Throughout, we highlight experimental implementations that exemplify the increasing role of reinforcement learning in shaping the development of quantum technologies.
Quantum computing and artificial intelligence: status and perspectives
May 29, 2025


This white paper discusses and explores the various points of intersection between quantum computing and artificial intelligence (AI). It describes how quantum computing could support the development of innovative AI solutions. It also examines use cases of classical AI that can empower research and development in quantum technologies, with a focus on quantum computing and quantum sensing. The purpose of this white paper is to provide a long-term research agenda aimed at addressing foundational questions about how AI and quantum computing interact and benefit one another. It concludes with a set of recommendations and challenges, including how to orchestrate the proposed theoretical work, align quantum AI developments with quantum hardware roadmaps, estimate both classical and quantum resources - especially with the goal of mitigating and optimizing energy consumption - advance this emerging hybrid software engineering discipline, and enhance European industrial competitiveness while considering societal implications.
Meta-learning characteristics and dynamics of quantum systems
Mar 13, 2025While machine learning holds great promise for quantum technologies, most current methods focus on predicting or controlling a specific quantum system. Meta-learning approaches, however, can adapt to new systems for which little data is available, by leveraging knowledge obtained from previous data associated with similar systems. In this paper, we meta-learn dynamics and characteristics of closed and open two-level systems, as well as the Heisenberg model. Based on experimental data of a Loss-DiVincenzo spin-qubit hosted in a Ge/Si core/shell nanowire for different gate voltage configurations, we predict qubit characteristics i.e. $g$-factor and Rabi frequency using meta-learning. The algorithm we introduce improves upon previous state-of-the-art meta-learning methods for physics-based systems by introducing novel techniques such as adaptive learning rates and a global optimizer for improved robustness and increased computational efficiency. We benchmark our method against other meta-learning methods, a vanilla transformer, and a multilayer perceptron, and demonstrate improved performance.
Quantum feedback control with a transformer neural network architecture
Nov 28, 2024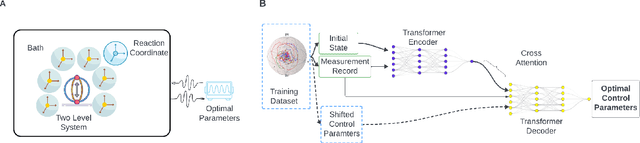



Attention-based neural networks such as transformers have revolutionized various fields such as natural language processing, genomics, and vision. Here, we demonstrate the use of transformers for quantum feedback control through a supervised learning approach. In particular, due to the transformer's ability to capture long-range temporal correlations and training efficiency, we show that it can surpass some of the limitations of previous control approaches, e.g.~those based on recurrent neural networks trained using a similar approach or reinforcement learning. We numerically show, for the example of state stabilization of a two-level system, that our bespoke transformer architecture can achieve unit fidelity to a target state in a short time even in the presence of inefficient measurement and Hamiltonian perturbations that were not included in the training set. We also demonstrate that this approach generalizes well to the control of non-Markovian systems. Our approach can be used for quantum error correction, fast control of quantum states in the presence of colored noise, as well as real-time tuning, and characterization of quantum devices.
Quantum Equilibrium Propagation for efficient training of quantum systems based on Onsager reciprocity
Jun 10, 2024


The widespread adoption of machine learning and artificial intelligence in all branches of science and technology has created a need for energy-efficient, alternative hardware platforms. While such neuromorphic approaches have been proposed and realised for a wide range of platforms, physically extracting the gradients required for training remains challenging as generic approaches only exist in certain cases. Equilibrium propagation (EP) is such a procedure that has been introduced and applied to classical energy-based models which relax to an equilibrium. Here, we show a direct connection between EP and Onsager reciprocity and exploit this to derive a quantum version of EP. This can be used to optimize loss functions that depend on the expectation values of observables of an arbitrary quantum system. Specifically, we illustrate this new concept with supervised and unsupervised learning examples in which the input or the solvable task is of quantum mechanical nature, e.g., the recognition of quantum many-body ground states, quantum phase exploration, sensing and phase boundary exploration. We propose that in the future quantum EP may be used to solve tasks such as quantum phase discovery with a quantum simulator even for Hamiltonians which are numerically hard to simulate or even partially unknown. Our scheme is relevant for a variety of quantum simulation platforms such as ion chains, superconducting qubit arrays, neutral atom Rydberg tweezer arrays and strongly interacting atoms in optical lattices.
Training of Physical Neural Networks
Jun 05, 2024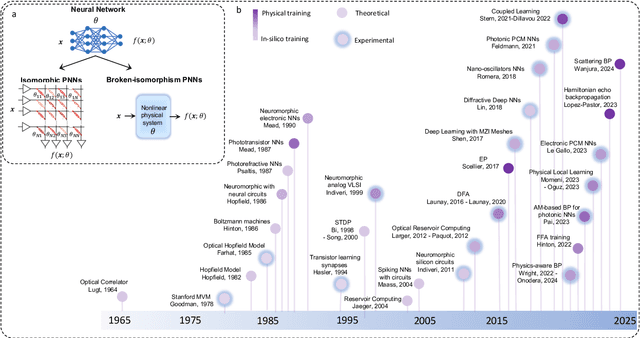
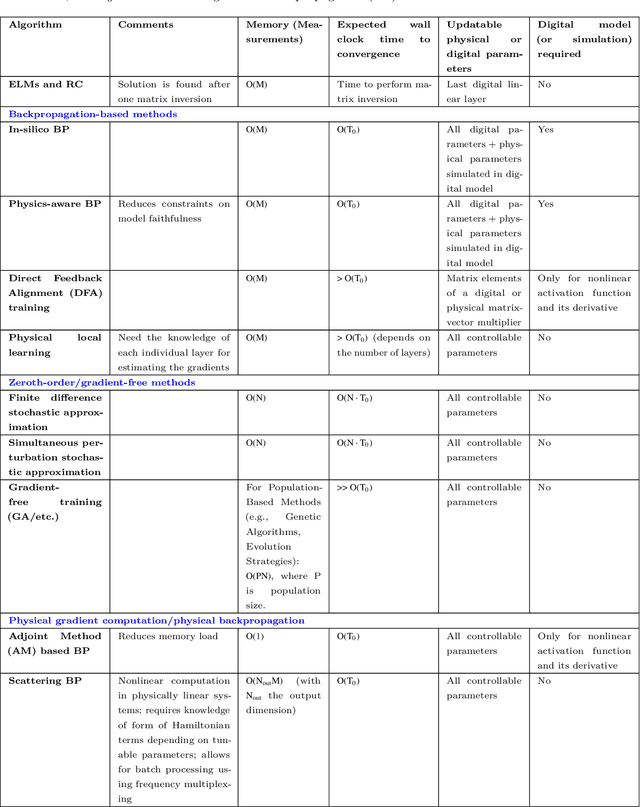
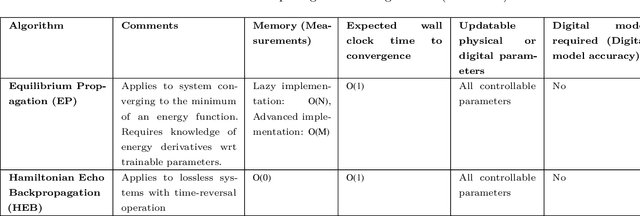
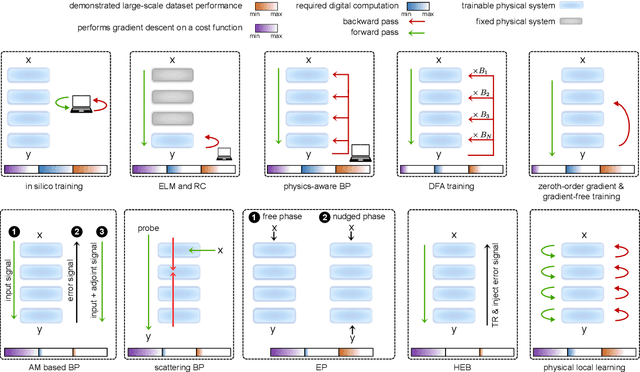
Physical neural networks (PNNs) are a class of neural-like networks that leverage the properties of physical systems to perform computation. While PNNs are so far a niche research area with small-scale laboratory demonstrations, they are arguably one of the most underappreciated important opportunities in modern AI. Could we train AI models 1000x larger than current ones? Could we do this and also have them perform inference locally and privately on edge devices, such as smartphones or sensors? Research over the past few years has shown that the answer to all these questions is likely "yes, with enough research": PNNs could one day radically change what is possible and practical for AI systems. To do this will however require rethinking both how AI models work, and how they are trained - primarily by considering the problems through the constraints of the underlying hardware physics. To train PNNs at large scale, many methods including backpropagation-based and backpropagation-free approaches are now being explored. These methods have various trade-offs, and so far no method has been shown to scale to the same scale and performance as the backpropagation algorithm widely used in deep learning today. However, this is rapidly changing, and a diverse ecosystem of training techniques provides clues for how PNNs may one day be utilized to create both more efficient realizations of current-scale AI models, and to enable unprecedented-scale models.
Tackling Decision Processes with Non-Cumulative Objectives using Reinforcement Learning
May 22, 2024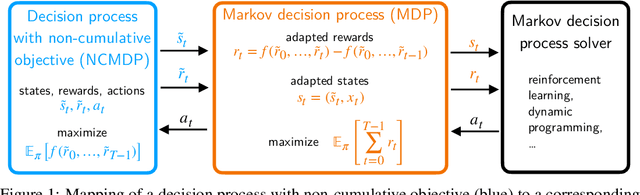

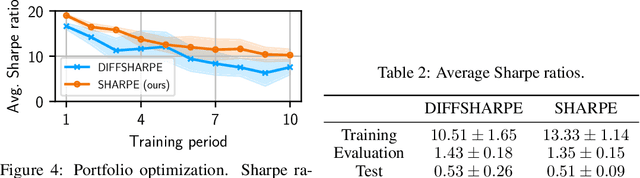
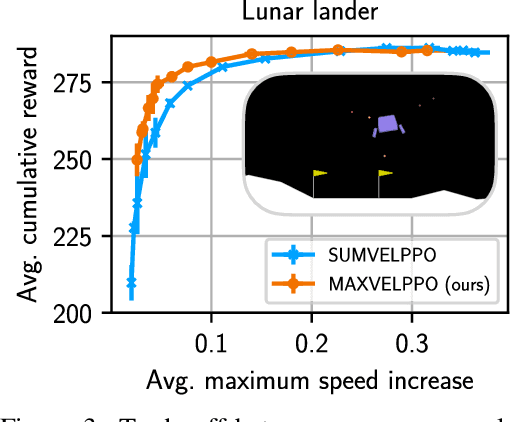
Markov decision processes (MDPs) are used to model a wide variety of applications ranging from game playing over robotics to finance. Their optimal policy typically maximizes the expected sum of rewards given at each step of the decision process. However, a large class of problems does not fit straightforwardly into this framework: Non-cumulative Markov decision processes (NCMDPs), where instead of the expected sum of rewards, the expected value of an arbitrary function of the rewards is maximized. Example functions include the maximum of the rewards or their mean divided by their standard deviation. In this work, we introduce a general mapping of NCMDPs to standard MDPs. This allows all techniques developed to find optimal policies for MDPs, such as reinforcement learning or dynamic programming, to be directly applied to the larger class of NCMDPs. Focusing on reinforcement learning, we show applications in a diverse set of tasks, including classical control, portfolio optimization in finance, and discrete optimization problems. Given our approach, we can improve both final performance and training time compared to relying on standard MDPs.
Training Coupled Phase Oscillators as a Neuromorphic Platform using Equilibrium Propagation
Feb 13, 2024



Given the rapidly growing scale and resource requirements of machine learning applications, the idea of building more efficient learning machines much closer to the laws of physics is an attractive proposition. One central question for identifying promising candidates for such neuromorphic platforms is whether not only inference but also training can exploit the physical dynamics. In this work, we show that it is possible to successfully train a system of coupled phase oscillators - one of the most widely investigated nonlinear dynamical systems with a multitude of physical implementations, comprising laser arrays, coupled mechanical limit cycles, superfluids, and exciton-polaritons. To this end, we apply the approach of equilibrium propagation, which permits to extract training gradients via a physical realization of backpropagation, based only on local interactions. The complex energy landscape of the XY/ Kuramoto model leads to multistability, and we show how to address this challenge. Our study identifies coupled phase oscillators as a new general-purpose neuromorphic platform and opens the door towards future experimental implementations.
Optimizing ZX-Diagrams with Deep Reinforcement Learning
Nov 30, 2023



ZX-diagrams are a powerful graphical language for the description of quantum processes with applications in fundamental quantum mechanics, quantum circuit optimization, tensor network simulation, and many more. The utility of ZX-diagrams relies on a set of local transformation rules that can be applied to them without changing the underlying quantum process they describe. These rules can be exploited to optimize the structure of ZX-diagrams for a range of applications. However, finding an optimal sequence of transformation rules is generally an open problem. In this work, we bring together ZX-diagrams with reinforcement learning, a machine learning technique designed to discover an optimal sequence of actions in a decision-making problem and show that a trained reinforcement learning agent can significantly outperform other optimization techniques like a greedy strategy or simulated annealing. The use of graph neural networks to encode the policy of the agent enables generalization to diagrams much bigger than seen during the training phase.