 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing Trainability of Instantaneous Quantum Polynomial Circuit Born Machines
Feb 13, 2026Instantaneous quantum polynomial quantum circuit Born machines (IQP-QCBMs) have been proposed as quantum generative models with a classically tractable training objective based on the maximum mean discrepancy (MMD) and a potential quantum advantage motivated by sampling-complexity arguments, making them an exciting model worth deeper investigation. While recent works have further proven the universality of a (slightly generalized) model, the next immediate question pertains to its trainability, i.e., whether it suffers from the exponentially vanishing loss gradients, known as the barren plateau issue, preventing effective use, and how regimes of trainability overlap with regimes of possible quantum advantage. Here, we provide significant strides in these directions. To study the trainability at initialization, we analytically derive closed-form expressions for the variances of the partial derivatives of the MMD loss function and provide general upper and lower bounds. With uniform initialization, we show that barren plateaus depend on the generator set and the spectrum of the chosen kernel. We identify regimes in which low-weight-biased kernels avoid exponential gradient suppression in structured topologies. Also, we prove that a small-variance Gaussian initialization ensures polynomial scaling for the gradient under mild conditions. As for the potential quantum advantage, we further argue, based on previous complexity-theoretic arguments, that sparse IQP families can output a probability distribution family that is classically intractable, and that this distribution remains trainable at initialization at least at lower-weight frequencies.
Quantum computing and artificial intelligence: status and perspectives
May 29, 2025


This white paper discusses and explores the various points of intersection between quantum computing and artificial intelligence (AI). It describes how quantum computing could support the development of innovative AI solutions. It also examines use cases of classical AI that can empower research and development in quantum technologies, with a focus on quantum computing and quantum sensing. The purpose of this white paper is to provide a long-term research agenda aimed at addressing foundational questions about how AI and quantum computing interact and benefit one another. It concludes with a set of recommendations and challenges, including how to orchestrate the proposed theoretical work, align quantum AI developments with quantum hardware roadmaps, estimate both classical and quantum resources - especially with the goal of mitigating and optimizing energy consumption - advance this emerging hybrid software engineering discipline, and enhance European industrial competitiveness while considering societal implications.
Detecting underdetermination in parameterized quantum circuits
Apr 04, 2025A central question in machine learning is how reliable the predictions of a trained model are. Reliability includes the identification of instances for which a model is likely not to be trusted based on an analysis of the learning system itself. Such unreliability for an input may arise from the model family providing a variety of hypotheses consistent with the training data, which can vastly disagree in their predictions on that particular input point. This is called the underdetermination problem, and it is important to develop methods to detect it. With the emergence of quantum machine learning (QML) as a prospective alternative to classical methods for certain learning problems, the question arises to what extent they are subject to underdetermination and whether similar techniques as those developed for classical models can be employed for its detection. In this work, we first provide an overview of concepts from Safe AI and reliability, which in particular received little attention in QML. We then explore the use of a method based on local second-order information for the detection of underdetermination in parameterized quantum circuits through numerical experiments. We further demonstrate that the approach is robust to certain levels of shot noise. Our work contributes to the body of literature on Safe Quantum AI, which is an emerging field of growing importance.
Double descent in quantum machine learning
Jan 17, 2025



The double descent phenomenon challenges traditional statistical learning theory by revealing scenarios where larger models do not necessarily lead to reduced performance on unseen data. While this counterintuitive behavior has been observed in a variety of classical machine learning models, particularly modern neural network architectures, it remains elusive within the context of quantum machine learning. In this work, we analytically demonstrate that quantum learning models can exhibit double descent behavior by drawing on insights from linear regression and random matrix theory. Additionally, our numerical experiments on quantum kernel methods across different real-world datasets and system sizes further confirm the existence of a test error peak, a characteristic feature of double descent. Our findings provide evidence that quantum models can operate in the modern, overparameterized regime without experiencing overfitting, thereby opening pathways to improved learning performance beyond traditional statistical learning theory.
Quantum computing and persistence in topological data analysis
Oct 28, 2024Topological data analysis (TDA) aims to extract noise-robust features from a data set by examining the number and persistence of holes in its topology. We show that a computational problem closely related to a core task in TDA -- determining whether a given hole persists across different length scales -- is $\mathsf{BQP}_1$-hard and contained in $\mathsf{BQP}$. This result implies an exponential quantum speedup for this problem under standard complexity-theoretic assumptions. Our approach relies on encoding the persistence of a hole in a variant of the guided sparse Hamiltonian problem, where the guiding state is constructed from a harmonic representative of the hole.
On the relation between trainability and dequantization of variational quantum learning models
Jun 11, 2024



The quest for successful variational quantum machine learning (QML) relies on the design of suitable parametrized quantum circuits (PQCs), as analogues to neural networks in classical machine learning. Successful QML models must fulfill the properties of trainability and non-dequantization, among others. Recent works have highlighted an intricate interplay between trainability and dequantization of such models, which is still unresolved. In this work we contribute to this debate from the perspective of machine learning, proving a number of results identifying, among others when trainability and non-dequantization are not mutually exclusive. We begin by providing a number of new somewhat broader definitions of the relevant concepts, compared to what is found in other literature, which are operationally motivated, and consistent with prior art. With these precise definitions given and motivated, we then study the relation between trainability and dequantization of variational QML. Next, we also discuss the degrees of "variationalness" of QML models, where we distinguish between models like the hardware efficient ansatz and quantum kernel methods. Finally, we introduce recipes for building PQC-based QML models which are both trainable and nondequantizable, and corresponding to different degrees of variationalness. We do not address the practical utility for such models. Our work however does point toward a way forward for finding more general constructions, for which finding applications may become feasible.
Curriculum reinforcement learning for quantum architecture search under hardware errors
Feb 05, 2024
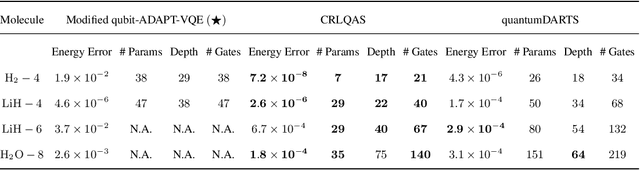


The key challenge in the noisy intermediate-scale quantum era is finding useful circuits compatible with current device limitations. Variational quantum algorithms (VQAs) offer a potential solution by fixing the circuit architecture and optimizing individual gate parameters in an external loop. However, parameter optimization can become intractable, and the overall performance of the algorithm depends heavily on the initially chosen circuit architecture. Several quantum architecture search (QAS) algorithms have been developed to design useful circuit architectures automatically. In the case of parameter optimization alone, noise effects have been observed to dramatically influence the performance of the optimizer and final outcomes, which is a key line of study. However, the effects of noise on the architecture search, which could be just as critical, are poorly understood. This work addresses this gap by introducing a curriculum-based reinforcement learning QAS (CRLQAS) algorithm designed to tackle challenges in realistic VQA deployment. The algorithm incorporates (i) a 3D architecture encoding and restrictions on environment dynamics to explore the search space of possible circuits efficiently, (ii) an episode halting scheme to steer the agent to find shorter circuits, and (iii) a novel variant of simultaneous perturbation stochastic approximation as an optimizer for faster convergence. To facilitate studies, we developed an optimized simulator for our algorithm, significantly improving computational efficiency in simulating noisy quantum circuits by employing the Pauli-transfer matrix formalism in the Pauli-Liouville basis. Numerical experiments focusing on quantum chemistry tasks demonstrate that CRLQAS outperforms existing QAS algorithms across several metrics in both noiseless and noisy environments.
Compilation of product-formula Hamiltonian simulation via reinforcement learning
Nov 07, 2023



Hamiltonian simulation is believed to be one of the first tasks where quantum computers can yield a quantum advantage. One of the most popular methods of Hamiltonian simulation is Trotterization, which makes use of the approximation $e^{i\sum_jA_j}\sim \prod_je^{iA_j}$ and higher-order corrections thereto. However, this leaves open the question of the order of operations (i.e. the order of the product over $j$, which is known to affect the quality of approximation). In some cases this order is fixed by the desire to minimise the error of approximation; when it is not the case, we propose that the order can be chosen to optimize compilation to a native quantum architecture. This presents a new compilation problem -- order-agnostic quantum circuit compilation -- which we prove is NP-hard in the worst case. In lieu of an easily-computable exact solution, we turn to methods of heuristic optimization of compilation. We focus on reinforcement learning due to the sequential nature of the compilation task, comparing it to simulated annealing and Monte Carlo tree search. While two of the methods outperform a naive heuristic, reinforcement learning clearly outperforms all others, with a gain of around 12% with respect to the second-best method and of around 50% compared to the naive heuristic in terms of the gate count. We further test the ability of RL to generalize across instances of the compilation problem, and find that a single learner is able to solve entire problem families. This demonstrates the ability of machine learning techniques to provide assistance in an order-agnostic quantum compilation task.
On the expressivity of embedding quantum kernels
Sep 25, 2023One of the most natural connections between quantum and classical machine learning has been established in the context of kernel methods. Kernel methods rely on kernels, which are inner products of feature vectors living in large feature spaces. Quantum kernels are typically evaluated by explicitly constructing quantum feature states and then taking their inner product, here called embedding quantum kernels. Since classical kernels are usually evaluated without using the feature vectors explicitly, we wonder how expressive embedding quantum kernels are. In this work, we raise the fundamental question: can all quantum kernels be expressed as the inner product of quantum feature states? Our first result is positive: Invoking computational universality, we find that for any kernel function there always exists a corresponding quantum feature map and an embedding quantum kernel. The more operational reading of the question is concerned with efficient constructions, however. In a second part, we formalize the question of universality of efficient embedding quantum kernels. For shift-invariant kernels, we use the technique of random Fourier features to show that they are universal within the broad class of all kernels which allow a variant of efficient Fourier sampling. We then extend this result to a new class of so-called composition kernels, which we show also contains projected quantum kernels introduced in recent works. After proving the universality of embedding quantum kernels for both shift-invariant and composition kernels, we identify the directions towards new, more exotic, and unexplored quantum kernel families, for which it still remains open whether they correspond to efficient embedding quantum kernels.
Exponential separations between classical and quantum learners
Jun 28, 2023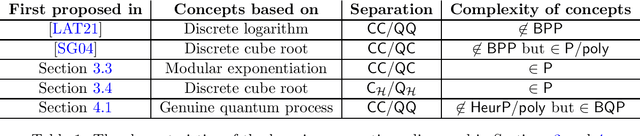
Despite significant effort, the quantum machine learning community has only demonstrated quantum learning advantages for artificial cryptography-inspired datasets when dealing with classical data. In this paper we address the challenge of finding learning problems where quantum learning algorithms can achieve a provable exponential speedup over classical learning algorithms. We reflect on computational learning theory concepts related to this question and discuss how subtle differences in definitions can result in significantly different requirements and tasks for the learner to meet and solve. We examine existing learning problems with provable quantum speedups and find that they largely rely on the classical hardness of evaluating the function that generates the data, rather than identifying it. To address this, we present two new learning separations where the classical difficulty primarily lies in identifying the function generating the data. Furthermore, we explore computational hardness assumptions that can be leveraged to prove quantum speedups in scenarios where data is quantum-generated, which implies likely quantum advantages in a plethora of more natural settings (e.g., in condensed matter and high energy physics). We also discuss the limitations of the classical shadow paradigm in the context of learning separations, and how physically-motivated settings such as characterizing phases of matter and Hamiltonian learning fit in the computational learning framework.