 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Contrastive Decoding with Probabilistic Hallucination Detection - Mitigating Hallucinations in Large Vision Language Models -
Apr 16, 2025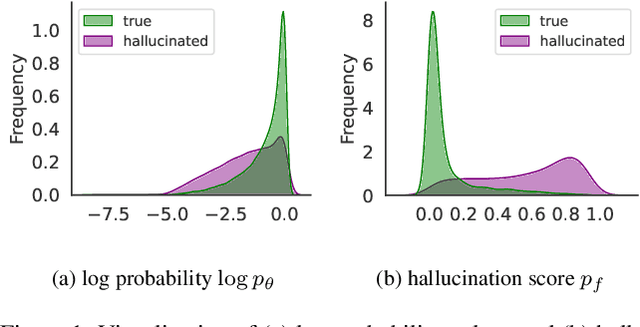


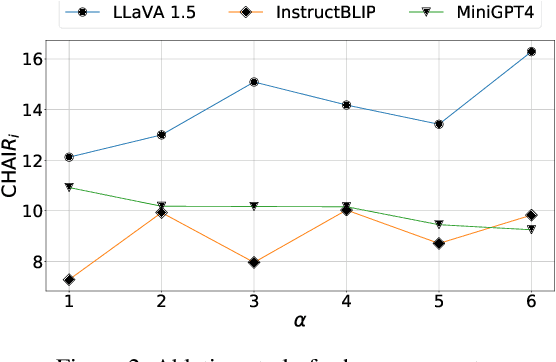
Despite recent advances in Large Vision Language Models (LVLMs), these models still suffer from generating hallucinatory responses that do not align with the visual input provided. To mitigate such hallucinations, we introduce Efficient Contrastive Decoding (ECD), a simple method that leverages probabilistic hallucination detection to shift the output distribution towards contextually accurate answers at inference time. By contrasting token probabilities and hallucination scores, ECD subtracts hallucinated concepts from the original distribution, effectively suppressing hallucinations. Notably, our proposed method can be applied to any open-source LVLM and does not require additional LVLM training. We evaluate our method on several benchmark datasets and across different LVLMs. Our experiments show that ECD effectively mitigates hallucinations, outperforming state-of-the-art methods with respect to performance on LVLM benchmarks and computation time.
Detecting underdetermination in parameterized quantum circuits
Apr 04, 2025A central question in machine learning is how reliable the predictions of a trained model are. Reliability includes the identification of instances for which a model is likely not to be trusted based on an analysis of the learning system itself. Such unreliability for an input may arise from the model family providing a variety of hypotheses consistent with the training data, which can vastly disagree in their predictions on that particular input point. This is called the underdetermination problem, and it is important to develop methods to detect it. With the emergence of quantum machine learning (QML) as a prospective alternative to classical methods for certain learning problems, the question arises to what extent they are subject to underdetermination and whether similar techniques as those developed for classical models can be employed for its detection. In this work, we first provide an overview of concepts from Safe AI and reliability, which in particular received little attention in QML. We then explore the use of a method based on local second-order information for the detection of underdetermination in parameterized quantum circuits through numerical experiments. We further demonstrate that the approach is robust to certain levels of shot noise. Our work contributes to the body of literature on Safe Quantum AI, which is an emerging field of growing importance.
Double descent in quantum machine learning
Jan 17, 2025



The double descent phenomenon challenges traditional statistical learning theory by revealing scenarios where larger models do not necessarily lead to reduced performance on unseen data. While this counterintuitive behavior has been observed in a variety of classical machine learning models, particularly modern neural network architectures, it remains elusive within the context of quantum machine learning. In this work, we analytically demonstrate that quantum learning models can exhibit double descent behavior by drawing on insights from linear regression and random matrix theory. Additionally, our numerical experiments on quantum kernel methods across different real-world datasets and system sizes further confirm the existence of a test error peak, a characteristic feature of double descent. Our findings provide evidence that quantum models can operate in the modern, overparameterized regime without experiencing overfitting, thereby opening pathways to improved learning performance beyond traditional statistical learning theory.
Quadratic Advantage with Quantum Randomized Smoothing Applied to Time-Series Analysis
Jul 25, 2024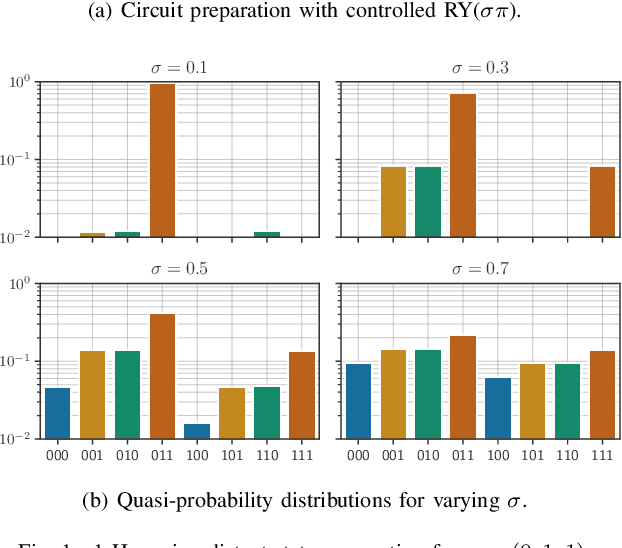
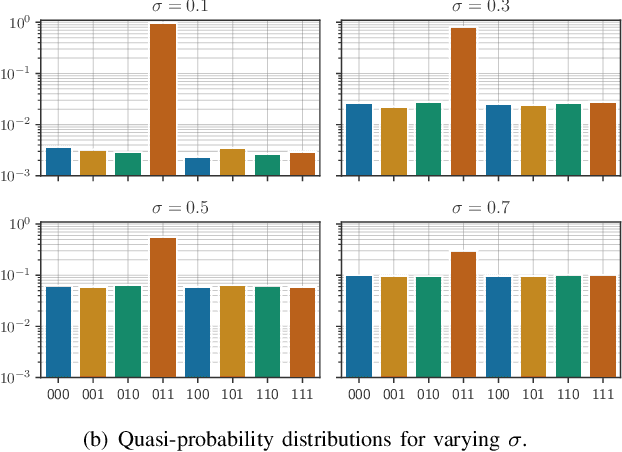


As quantum machine learning continues to develop at a rapid pace, the importance of ensuring the robustness and efficiency of quantum algorithms cannot be overstated. Our research presents an analysis of quantum randomized smoothing, how data encoding and perturbation modeling approaches can be matched to achieve meaningful robustness certificates. By utilizing an innovative approach integrating Grover's algorithm, a quadratic sampling advantage over classical randomized smoothing is achieved. This strategy necessitates a basis state encoding, thus restricting the space of meaningful perturbations. We show how constrained $k$-distant Hamming weight perturbations are a suitable noise distribution here, and elucidate how they can be constructed on a quantum computer. The efficacy of the proposed framework is demonstrated on a time series classification task employing a Bag-of-Words pre-processing solution. The advantage of quadratic sample reduction is recovered especially in the regime with large number of samples. This may allow quantum computers to efficiently scale randomized smoothing to more complex tasks beyond the reach of classical methods.
MetaToken: Detecting Hallucination in Image Descriptions by Meta Classification
May 29, 2024



Large Vision Language Models (LVLMs) have shown remarkable capabilities in multimodal tasks like visual question answering or image captioning. However, inconsistencies between the visual information and the generated text, a phenomenon referred to as hallucinations, remain an unsolved problem with regard to the trustworthiness of LVLMs. To address this problem, recent works proposed to incorporate computationally costly Large (Vision) Language Models in order to detect hallucinations on a sentence- or subsentence-level. In this work, we introduce MetaToken, a lightweight binary classifier to detect hallucinations on the token-level at negligible cost. Based on a statistical analysis, we reveal key factors of hallucinations in LVLMs which have been overseen in previous works. MetaToken can be applied to any open-source LVLM without any knowledge about ground truth data providing a reliable detection of hallucinations. We evaluate our method on four state-of-the-art LVLMs demonstrating the effectiveness of our approach.
Temporal Performance Prediction for Deep Convolutional Long Short-Term Memory Networks
Nov 13, 2023



Quantifying predictive uncertainty of deep semantic segmentation networks is essential in safety-critical tasks. In applications like autonomous driving, where video data is available, convolutional long short-term memory networks are capable of not only providing semantic segmentations but also predicting the segmentations of the next timesteps. These models use cell states to broadcast information from previous data by taking a time series of inputs to predict one or even further steps into the future. We present a temporal postprocessing method which estimates the prediction performance of convolutional long short-term memory networks by either predicting the intersection over union of predicted and ground truth segments or classifying between intersection over union being equal to zero or greater than zero. To this end, we create temporal cell state-based input metrics per segment and investigate different models for the estimation of the predictive quality based on these metrics. We further study the influence of the number of considered cell states for the proposed metrics.