 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Epistemic Predictive Uncertainty in Conformal Prediction
Feb 02, 2026We study the problem of quantifying epistemic predictive uncertainty (EPU) -- that is, uncertainty faced at prediction time due to the existence of multiple plausible predictive models -- within the framework of conformal prediction (CP). To expose the implicit model multiplicity underlying CP, we build on recent results showing that, under a mild assumption, any full CP procedure induces a set of closed and convex predictive distributions, commonly referred to as a credal set. Importantly, the conformal prediction region (CPR) coincides exactly with the set of labels to which all distributions in the induced credal set assign probability at least $1-α$. As our first contribution, we prove that this characterisation also holds in split CP. Building on this connection, we then propose a computationally efficient and analytically tractable uncertainty measure, based on \emph{Maximum Mean Imprecision}, to quantify the EPU by measuring the degree of conflicting information within the induced credal set. Experiments on active learning and selective classification demonstrate that the quantified EPU provides substantially more informative and fine-grained uncertainty assessments than reliance on CPR size alone. More broadly, this work highlights the potential of CP serving as a principled basis for decision-making under epistemic uncertainty.
When Do Credal Sets Stabilize? Fixed-Point Theorems for Credal Set Updates
Oct 06, 2025Many machine learning algorithms rely on iterative updates of uncertainty representations, ranging from variational inference and expectation-maximization, to reinforcement learning, continual learning, and multi-agent learning. In the presence of imprecision and ambiguity, credal sets -- closed, convex sets of probability distributions -- have emerged as a popular framework for representing imprecise probabilistic beliefs. Under such imprecision, many learning problems in imprecise probabilistic machine learning (IPML) may be viewed as processes involving successive applications of update rules on credal sets. This naturally raises the question of whether this iterative process converges to stable fixed points -- or, more generally, under what conditions on the updating mechanism such fixed points exist, and whether they can be attained. We provide the first analysis of this problem and illustrate our findings using Credal Bayesian Deep Learning as a concrete example. Our work demonstrates that incorporating imprecision into the learning process not only enriches the representation of uncertainty, but also reveals structural conditions under which stability emerges, thereby offering new insights into the dynamics of iterative learning under imprecision.
Exact Shapley Attributions in Quadratic-time for FANOVA Gaussian Processes
Aug 20, 2025Shapley values are widely recognized as a principled method for attributing importance to input features in machine learning. However, the exact computation of Shapley values scales exponentially with the number of features, severely limiting the practical application of this powerful approach. The challenge is further compounded when the predictive model is probabilistic - as in Gaussian processes (GPs) - where the outputs are random variables rather than point estimates, necessitating additional computational effort in modeling higher-order moments. In this work, we demonstrate that for an important class of GPs known as FANOVA GP, which explicitly models all main effects and interactions, *exact* Shapley attributions for both local and global explanations can be computed in *quadratic time*. For local, instance-wise explanations, we define a stochastic cooperative game over function components and compute the exact stochastic Shapley value in quadratic time only, capturing both the expected contribution and uncertainty. For global explanations, we introduce a deterministic, variance-based value function and compute exact Shapley values that quantify each feature's contribution to the model's overall sensitivity. Our methods leverage a closed-form (stochastic) M\"{o}bius representation of the FANOVA decomposition and introduce recursive algorithms, inspired by Newton's identities, to efficiently compute the mean and variance of Shapley values. Our work enhances the utility of explainable AI, as demonstrated by empirical studies, by providing more scalable, axiomatically sound, and uncertainty-aware explanations for predictions generated by structured probabilistic models.
Kernel Quantile Embeddings and Associated Probability Metrics
May 26, 2025Embedding probability distributions into reproducing kernel Hilbert spaces (RKHS) has enabled powerful nonparametric methods such as the maximum mean discrepancy (MMD), a statistical distance with strong theoretical and computational properties. At its core, the MMD relies on kernel mean embeddings to represent distributions as mean functions in RKHS. However, it remains unclear if the mean function is the only meaningful RKHS representation. Inspired by generalised quantiles, we introduce the notion of kernel quantile embeddings (KQEs). We then use KQEs to construct a family of distances that: (i) are probability metrics under weaker kernel conditions than MMD; (ii) recover a kernelised form of the sliced Wasserstein distance; and (iii) can be efficiently estimated with near-linear cost. Through hypothesis testing, we show that these distances offer a competitive alternative to MMD and its fast approximations.
Computing Exact Shapley Values in Polynomial Time for Product-Kernel Methods
May 22, 2025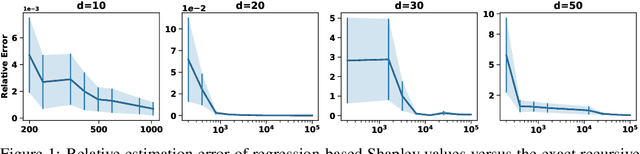
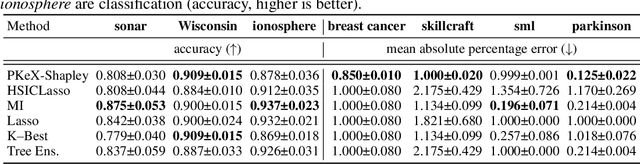
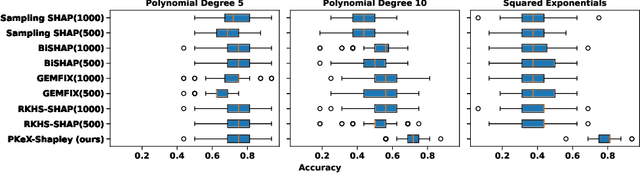
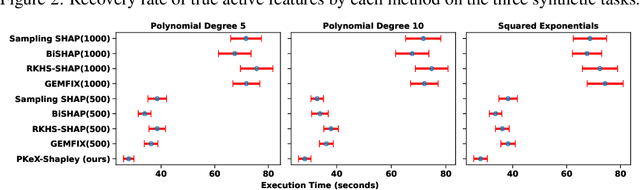
Kernel methods are widely used in machine learning due to their flexibility and expressive power. However, their black-box nature poses significant challenges to interpretability, limiting their adoption in high-stakes applications. Shapley value-based feature attribution techniques, such as SHAP and kernel-specific variants like RKHS-SHAP, offer a promising path toward explainability. Yet, computing exact Shapley values remains computationally intractable in general, motivating the development of various approximation schemes. In this work, we introduce PKeX-Shapley, a novel algorithm that utilizes the multiplicative structure of product kernels to enable the exact computation of Shapley values in polynomial time. We show that product-kernel models admit a functional decomposition that allows for a recursive formulation of Shapley values. This decomposition not only yields computational efficiency but also enhances interpretability in kernel-based learning. We also demonstrate how our framework can be generalized to explain kernel-based statistical discrepancies such as the Maximum Mean Discrepancy (MMD) and the Hilbert-Schmidt Independence Criterion (HSIC), thus offering new tools for interpretable statistical inference.
Integral Imprecise Probability Metrics
May 22, 2025Quantifying differences between probability distributions is fundamental to statistics and machine learning, primarily for comparing statistical uncertainty. In contrast, epistemic uncertainty (EU) -- due to incomplete knowledge -- requires richer representations than those offered by classical probability. Imprecise probability (IP) theory offers such models, capturing ambiguity and partial belief. This has driven growing interest in imprecise probabilistic machine learning (IPML), where inference and decision-making rely on broader uncertainty models -- highlighting the need for metrics beyond classical probability. This work introduces the Integral Imprecise Probability Metric (IIPM) framework, a Choquet integral-based generalisation of classical Integral Probability Metric (IPM) to the setting of capacities -- a broad class of IP models encompassing many existing ones, including lower probabilities, probability intervals, belief functions, and more. Theoretically, we establish conditions under which IIPM serves as a valid metric and metrises a form of weak convergence of capacities. Practically, IIPM not only enables comparison across different IP models but also supports the quantification of epistemic uncertainty within a single IP model. In particular, by comparing an IP model with its conjugate, IIPM gives rise to a new class of EU measures -- Maximum Mean Imprecision -- which satisfy key axiomatic properties proposed in the Uncertainty Quantification literature. We validate MMI through selective classification experiments, demonstrating strong empirical performance against established EU measures, and outperforming them when classical methods struggle to scale to a large number of classes. Our work advances both theory and practice in IPML, offering a principled framework for comparing and quantifying epistemic uncertainty under imprecision.
Truthful Elicitation of Imprecise Forecasts
Mar 20, 2025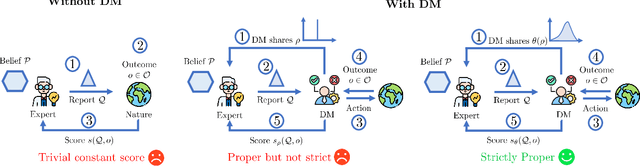
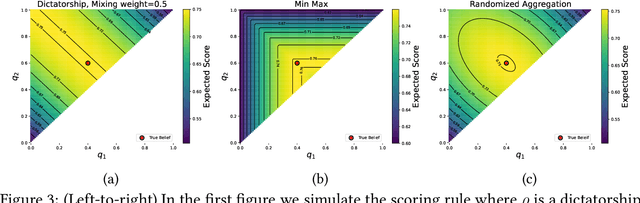
The quality of probabilistic forecasts is crucial for decision-making under uncertainty. While proper scoring rules incentivize truthful reporting of precise forecasts, they fall short when forecasters face epistemic uncertainty about their beliefs, limiting their use in safety-critical domains where decision-makers (DMs) prioritize proper uncertainty management. To address this, we propose a framework for scoring imprecise forecasts -- forecasts given as a set of beliefs. Despite existing impossibility results for deterministic scoring rules, we enable truthful elicitation by drawing connection to social choice theory and introducing a two-way communication framework where DMs first share their aggregation rules (e.g., averaging or min-max) used in downstream decisions for resolving forecast ambiguity. This, in turn, helps forecasters resolve indecision during elicitation. We further show that truthful elicitation of imprecise forecasts is achievable using proper scoring rules randomized over the aggregation procedure. Our approach allows DM to elicit and integrate the forecaster's epistemic uncertainty into their decision-making process, thus improving credibility.
Bayesian Optimization for Building Social-Influence-Free Consensus
Feb 11, 2025We introduce Social Bayesian Optimization (SBO), a vote-efficient algorithm for consensus-building in collective decision-making. In contrast to single-agent scenarios, collective decision-making encompasses group dynamics that may distort agents' preference feedback, thereby impeding their capacity to achieve a social-influence-free consensus -- the most preferable decision based on the aggregated agent utilities. We demonstrate that under mild rationality axioms, reaching social-influence-free consensus using noisy feedback alone is impossible. To address this, SBO employs a dual voting system: cheap but noisy public votes (e.g., show of hands in a meeting), and more accurate, though expensive, private votes (e.g., one-to-one interview). We model social influence using an unknown social graph and leverage the dual voting system to efficiently learn this graph. Our theoretical findigns show that social graph estimation converges faster than the black-box estimation of agents' utilities, allowing us to reduce reliance on costly private votes early in the process. This enables efficient consensus-building primarily through noisy public votes, which are debiased based on the estimated social graph to infer social-influence-free feedback. We validate the efficacy of SBO across multiple real-world applications, including thermal comfort, team building, travel negotiation, and energy trading collaboration.
Strategic Learning with Local Explanations as Feedback
Feb 06, 2025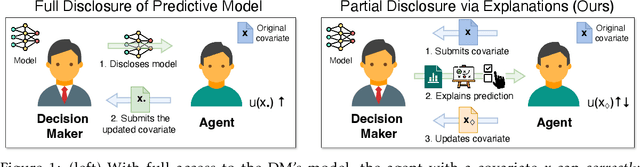
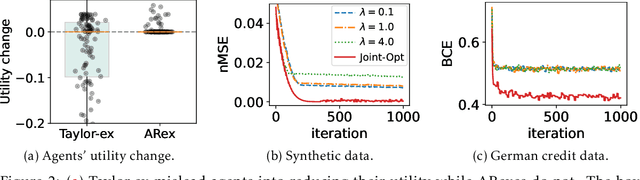
We investigate algorithmic decision problems where agents can respond strategically to the decision maker's (DM) models. The demand for clear and actionable explanations from DMs to (potentially strategic) agents continues to rise. While prior work often treats explanations as full model disclosures, explanations in practice might convey only partial information, which can lead to misinterpretations and harmful responses. When full disclosure of the predictive model is neither feasible nor desirable, a key open question is how DMs can use explanations to maximise their utility without compromising agent welfare. In this work, we explore well-known local and global explanation methods, and establish a necessary condition to prevent explanations from misleading agents into self-harming actions. Moreover, with conditional homogeneity, we establish that action recommendation (AR)-based explanations are sufficient for non-harmful responses, akin to the revelation principle in information design. To operationalise AR-based explanations, we propose a simple algorithm to jointly optimise the predictive model and AR policy to balance DM outcomes with agent welfare. Our empirical results demonstrate the benefits of this approach as a more refined strategy for safe and effective partial model disclosure in algorithmic decision-making.
Credal Two-Sample Tests of Epistemic Ignorance
Oct 16, 2024



We introduce credal two-sample testing, a new hypothesis testing framework for comparing credal sets -- convex sets of probability measures where each element captures aleatoric uncertainty and the set itself represents epistemic uncertainty that arises from the modeller's partial ignorance. Classical two-sample tests, which rely on comparing precise distributions, fail to address epistemic uncertainty due to partial ignorance. To bridge this gap, we generalise two-sample tests to compare credal sets, enabling reasoning for equality, inclusion, intersection, and mutual exclusivity, each offering unique insights into the modeller's epistemic beliefs. We formalise these tests as two-sample tests with nuisance parameters and introduce the first permutation-based solution for this class of problems, significantly improving upon existing methods. Our approach properly incorporates the modeller's epistemic uncertainty into hypothesis testing, leading to more robust and credible conclusions, with kernel-based implementations for real-world applications.