 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLooping in the Human: Collaborative and Explainable Bayesian Optimization
Nov 06, 2023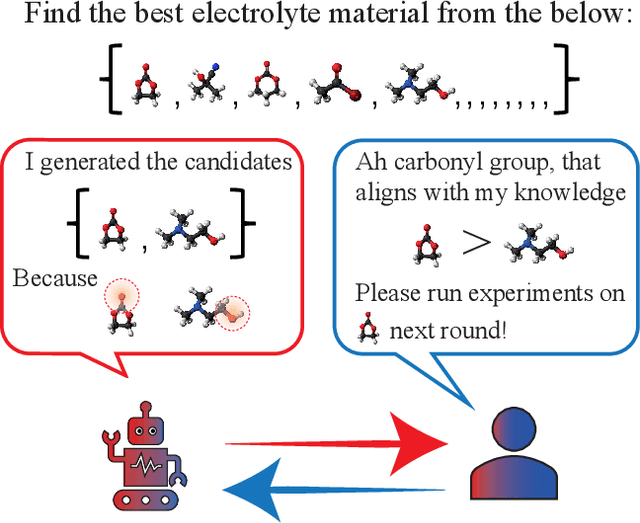
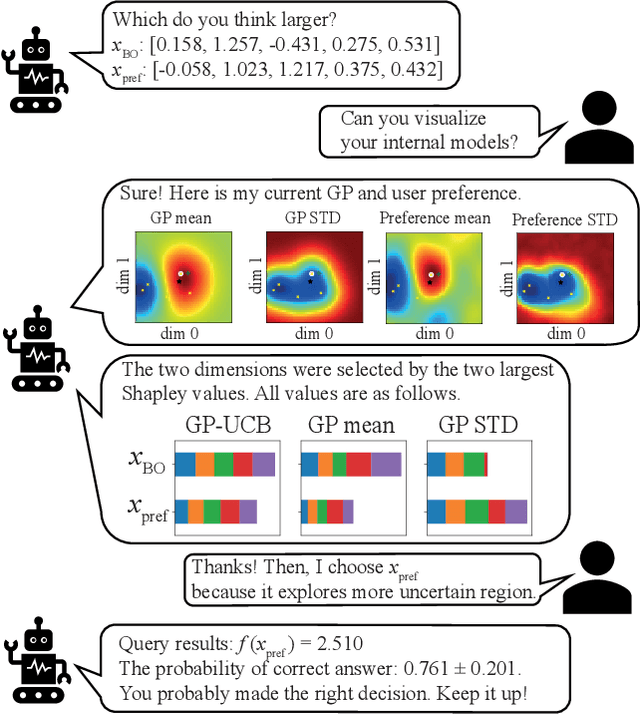
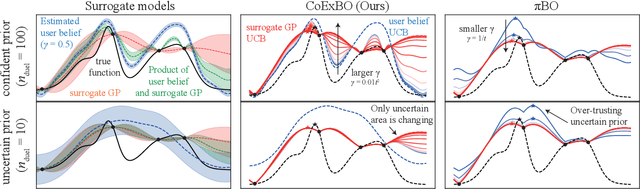
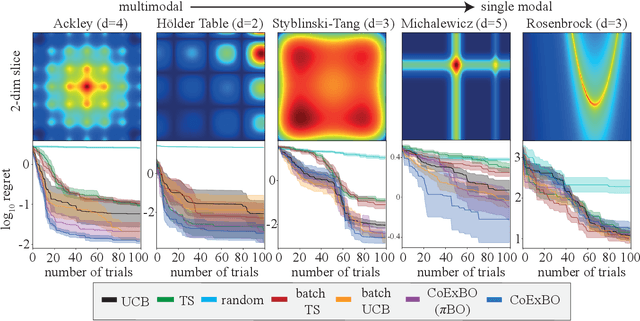
Like many optimizers, Bayesian optimization often falls short of gaining user trust due to opacity. While attempts have been made to develop human-centric optimizers, they typically assume user knowledge is well-specified and error-free, employing users mainly as supervisors of the optimization process. We relax these assumptions and propose a more balanced human-AI partnership with our Collaborative and Explainable Bayesian Optimization (CoExBO) framework. Instead of explicitly requiring a user to provide a knowledge model, CoExBO employs preference learning to seamlessly integrate human insights into the optimization, resulting in algorithmic suggestions that resonate with user preference. CoExBO explains its candidate selection every iteration to foster trust, empowering users with a clearer grasp of the optimization. Furthermore, CoExBO offers a no-harm guarantee, allowing users to make mistakes; even with extreme adversarial interventions, the algorithm converges asymptotically to a vanilla Bayesian optimization. We validate CoExBO's efficacy through human-AI teaming experiments in lithium-ion battery design, highlighting substantial improvements over conventional methods.
Fast dynamic time warping and clustering in C++
Jul 10, 2023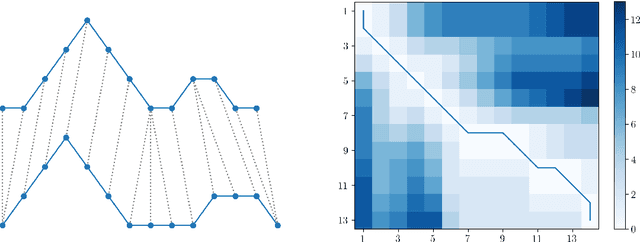
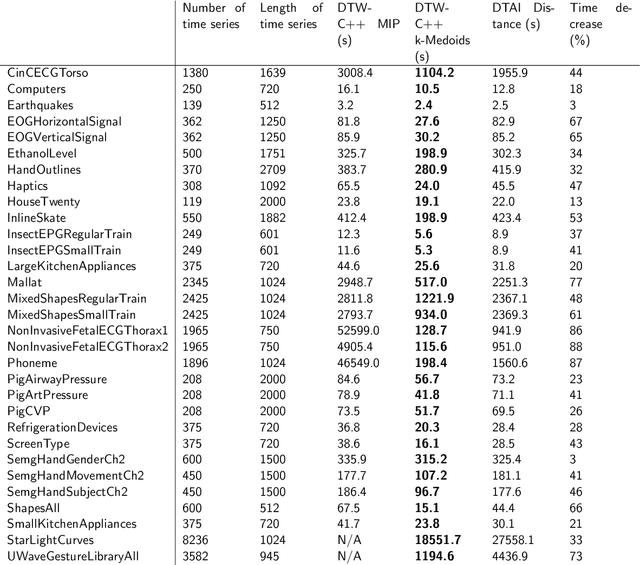
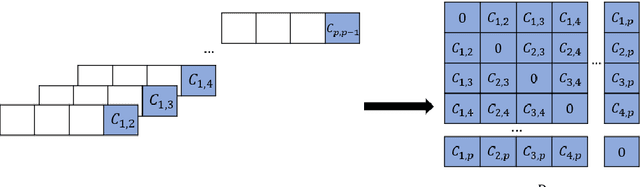
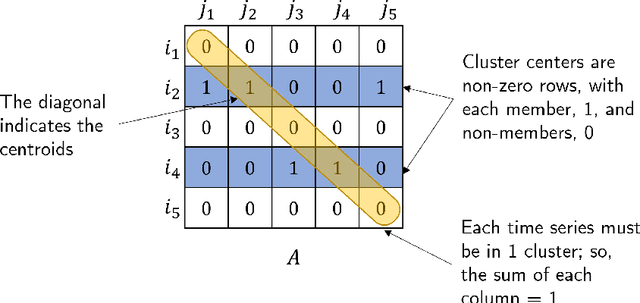
We present an approach for computationally efficient dynamic time warping (DTW) and clustering of time-series data. The method frames the dynamic warping of time series datasets as an optimisation problem solved using dynamic programming, and then clusters time series data by solving a second optimisation problem using mixed-integer programming (MIP). There is also an option to use k-medoids clustering for increased speed, when a certificate for global optimality is not essential. The improved efficiency of our approach is due to task-level parallelisation of the clustering alongside DTW. Our approach was tested using the UCR Time Series Archive, and was found to be, on average, 33% faster than the next fastest option when using the same clustering method. This increases to 64% faster when considering only larger datasets (with more than 1000 time series). The MIP clustering is most effective on small numbers of longer time series, because the DTW computation is faster than other approaches, but the clustering problem becomes increasingly computationally expensive as the number of time series to be clustered increases.
Learning battery model parameter dynamics from data with recursive Gaussian process regression
Apr 26, 2023Estimating state of health is a critical function of a battery management system but remains challenging due to the variability of operating conditions and usage requirements of real applications. As a result, techniques based on fitting equivalent circuit models may exhibit inaccuracy at extremes of performance and over long-term ageing, or instability of parameter estimates. Pure data-driven techniques, on the other hand, suffer from lack of generality beyond their training dataset. In this paper, we propose a hybrid approach combining data- and model-driven techniques for battery health estimation. Specifically, we demonstrate a Bayesian data-driven method, Gaussian process regression, to estimate model parameters as functions of states, operating conditions, and lifetime. Computational efficiency is ensured through a recursive approach yielding a unified joint state-parameter estimator that learns parameter dynamics from data and is robust to gaps and varying operating conditions. Results show the efficacy of the method, on both simulated and measured data, including accurate estimates and forecasts of battery capacity and internal resistance. This opens up new opportunities to understand battery ageing in real applications.
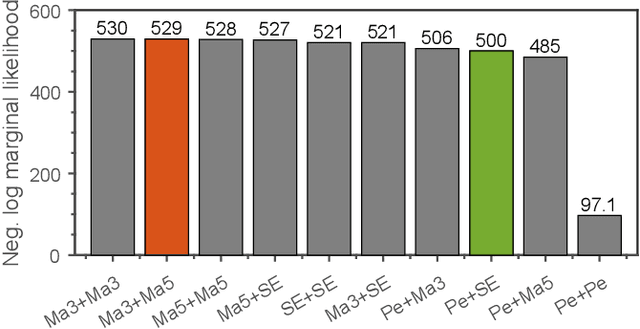
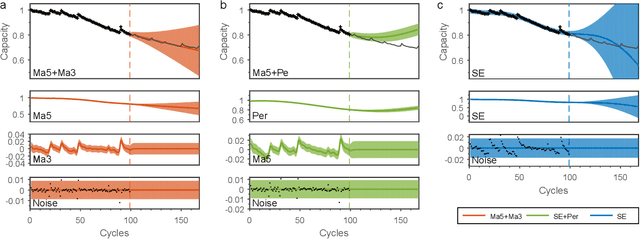
Bayesian Model Selection of Lithium-Ion Battery Models via Bayesian Quadrature
Nov 13, 2022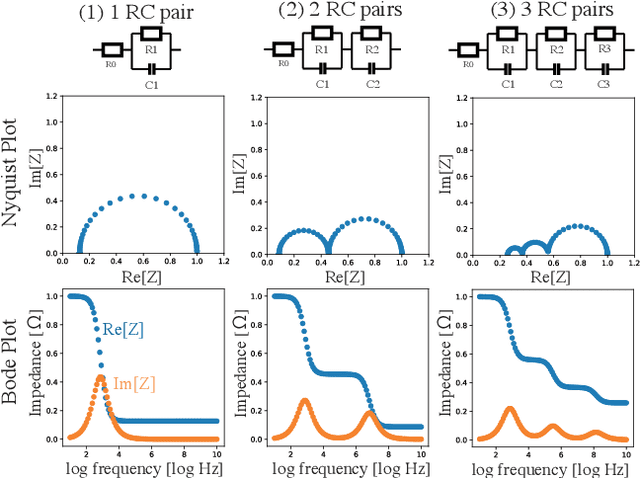
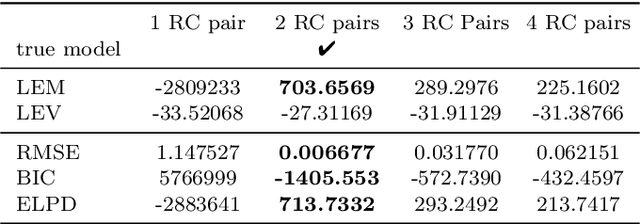
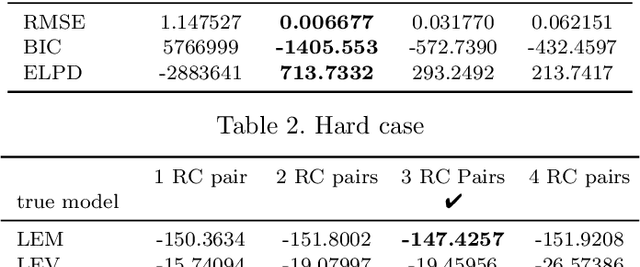
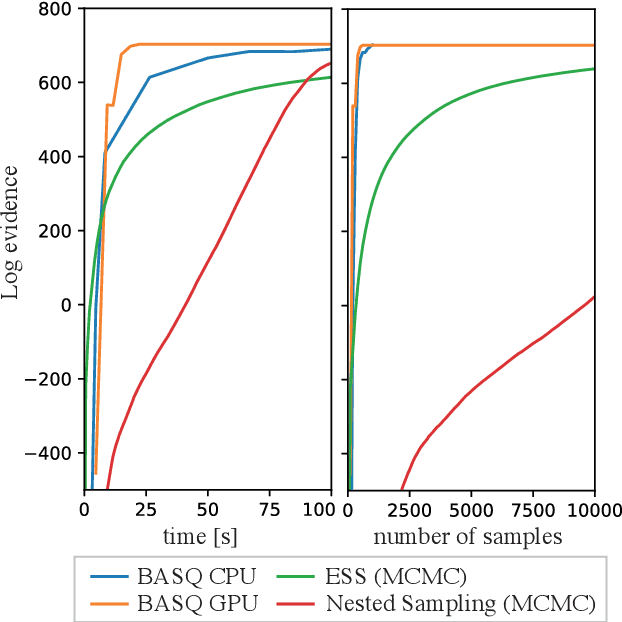
A wide variety of battery models are available, and it is not always obvious which model `best' describes a dataset. This paper presents a Bayesian model selection approach using Bayesian quadrature. The model evidence is adopted as the selection metric, choosing the simplest model that describes the data, in the spirit of Occam's razor. However, estimating this requires integral computations over parameter space, which is usually prohibitively expensive. Bayesian quadrature offers sample-efficient integration via model-based inference that minimises the number of battery model evaluations. The posterior distribution of model parameters can also be inferred as a byproduct without further computation. Here, the simplest lithium-ion battery models, equivalent circuit models, were used to analyse the sensitivity of the selection criterion to given different datasets and model configurations. We show that popular model selection criteria, such as root-mean-square error and Bayesian information criterion, can fail to select a parsimonious model in the case of a multimodal posterior. The model evidence can spot the optimal model in such cases, simultaneously providing the variance of the evidence inference itself as an indication of confidence. We also show that Bayesian quadrature can compute the evidence faster than popular Monte Carlo based solvers.
Bayesian hierarchical modelling for battery lifetime early prediction
Nov 10, 2022



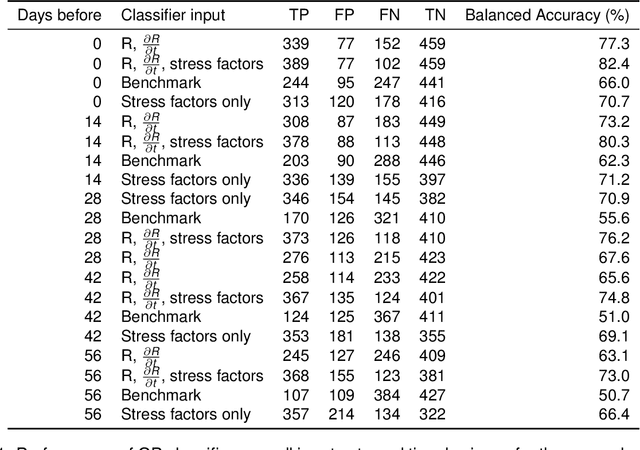
Accurate prediction of battery health is essential for real-world system management and lab-based experiment design. However, building a life-prediction model from different cycling conditions is still a challenge. Large lifetime variability results from both cycling conditions and initial manufacturing variability, and this -- along with the limited experimental resources usually available for each cycling condition -- makes data-driven lifetime prediction challenging. Here, a hierarchical Bayesian linear model is proposed for battery life prediction, combining both individual cell features (reflecting manufacturing variability) with population-wide features (reflecting the impact of cycling conditions on the population average). The individual features were collected from the first 100 cycles of data, which is around 5-10% of lifetime. The model is able to predict end of life with a root mean square error of 3.2 days and mean absolute percentage error of 8.6%, measured through 5-fold cross-validation, overperforming the baseline (non-hierarchical) model by around 12-13%.
Predicting battery end of life from solar off-grid system field data using machine learning
Jul 29, 2021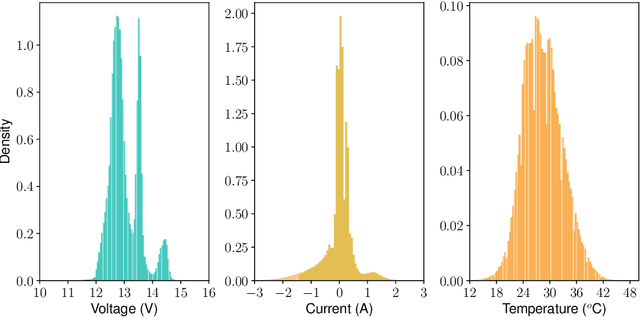
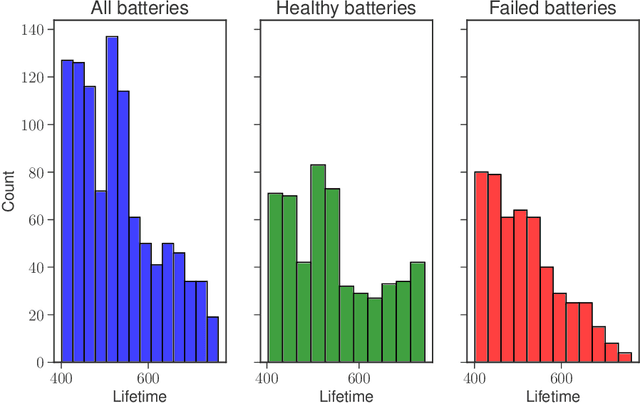

Hundreds of millions of people lack access to electricity. Decentralised solar-battery systems are key for addressing this whilst avoiding carbon emissions and air pollution, but are hindered by relatively high costs and rural locations that inhibit timely preventative maintenance. Accurate diagnosis of battery health and prediction of end of life from operational data improves user experience and reduces costs. But lack of controlled validation tests and variable data quality mean existing lab-based techniques fail to work. We apply a scaleable probabilistic machine learning approach to diagnose health in 1027 solar-connected lead-acid batteries, each running for 400-760 days, totalling 620 million data rows. We demonstrate 73% accurate prediction of end of life, eight weeks in advance, rising to 82% at the point of failure. This work highlights the opportunity to estimate health from existing measurements using `big data' techniques, without additional equipment, extending lifetime and improving performance in real-world applications.
Piecewise-linear modelling with feature selection for Li-ion battery end of life prognosis
Apr 15, 2021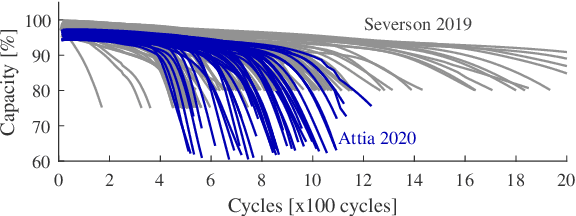
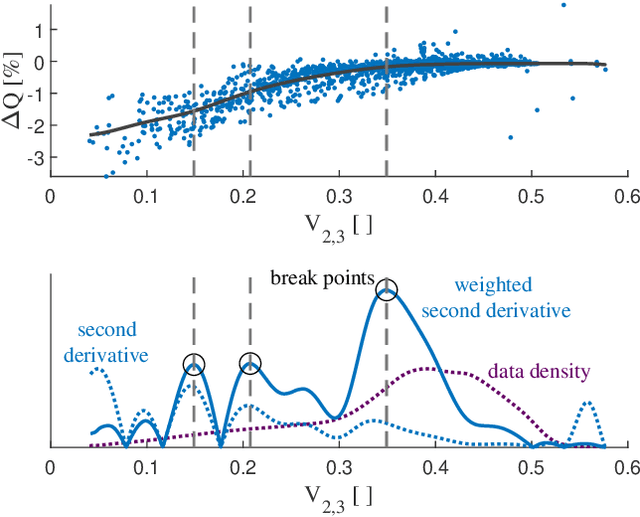
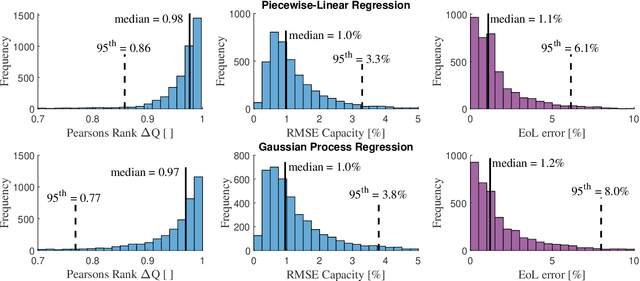
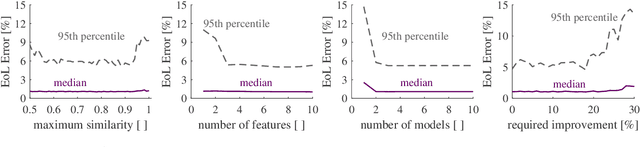
The complex nature of lithium-ion battery degradation has led to many machine learning based approaches to health forecasting being proposed in literature. However, machine learning can be computationally intensive. Linear approaches are faster but have previously been too inflexible for successful prognosis. For both techniques, the choice and quality of the inputs is a limiting factor of performance. Piecewise-linear models, combined with automated feature selection, offer a fast and flexible alternative without being as computationally intensive as machine learning. Here, a piecewise-linear approach to battery health forecasting was compared to a Gaussian process regression tool and found to perform equally well. The input feature selection process demonstrated the benefit of limiting the correlation between inputs. Further trials found that the piecewise-linear approach was robust to changing input size and availability of training data.
Battery health prediction under generalized conditions using a Gaussian process transition model
Jul 17, 2018
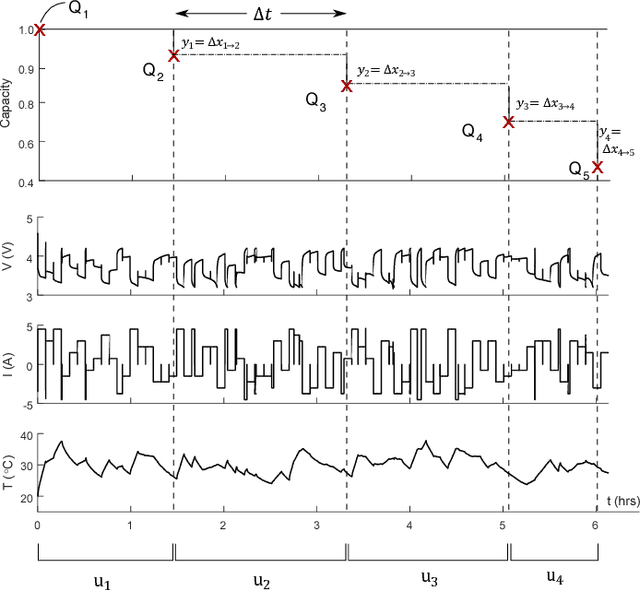


Accurately predicting the future health of batteries is necessary to ensure reliable operation, minimise maintenance costs, and calculate the value of energy storage investments. The complex nature of degradation renders data-driven approaches a promising alternative to mechanistic modelling. This study predicts the changes in battery capacity over time using a Bayesian non-parametric approach based on Gaussian process regression. These changes can be integrated against an arbitrary input sequence to predict capacity fade in a variety of usage scenarios, forming a generalised health model. The approach naturally incorporates varying current, voltage and temperature inputs, crucial for enabling real world application. A key innovation is the feature selection step, where arbitrary length current, voltage and temperature measurement vectors are mapped to fixed size feature vectors, enabling them to be efficiently used as exogenous variables. The approach is demonstrated on the open-source NASA Randomised Battery Usage Dataset, with data of 26 cells aged under randomized operational conditions. Using half of the cells for training, and half for validation, the method is shown to accurately predict non-linear capacity fade, with a best case normalised root mean square error of 4.3%, including accurate estimation of prediction uncertainty.
Gaussian process regression for forecasting battery state of health
May 31, 2017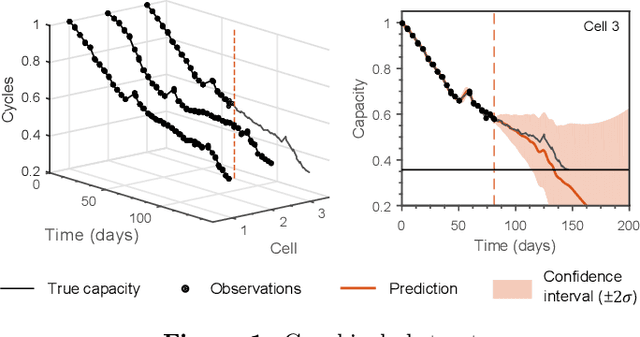
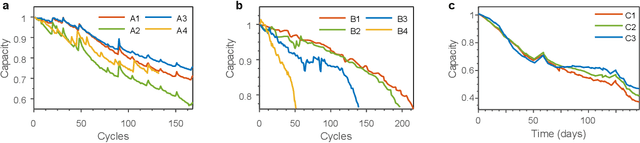
Accurately predicting the future capacity and remaining useful life of batteries is necessary to ensure reliable system operation and to minimise maintenance costs. The complex nature of battery degradation has meant that mechanistic modelling of capacity fade has thus far remained intractable; however, with the advent of cloud-connected devices, data from cells in various applications is becoming increasingly available, and the feasibility of data-driven methods for battery prognostics is increasing. Here we propose Gaussian process (GP) regression for forecasting battery state of health, and highlight various advantages of GPs over other data-driven and mechanistic approaches. GPs are a type of Bayesian non-parametric method, and hence can model complex systems whilst handling uncertainty in a principled manner. Prior information can be exploited by GPs in a variety of ways: explicit mean functions can be used if the functional form of the underlying degradation model is available, and multiple-output GPs can effectively exploit correlations between data from different cells. We demonstrate the predictive capability of GPs for short-term and long-term (remaining useful life) forecasting on a selection of capacity vs. cycle datasets from lithium-ion cells.
* 13 pages, 7 figures, published in the Journal of Power Sources, 2017