 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast dynamic time warping and clustering in C++
Jul 10, 2023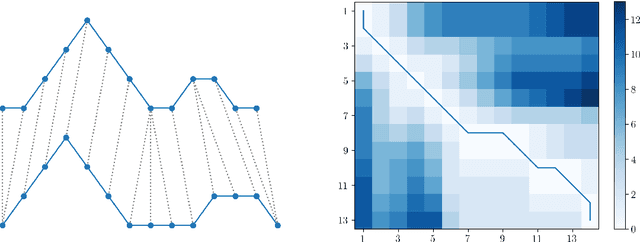
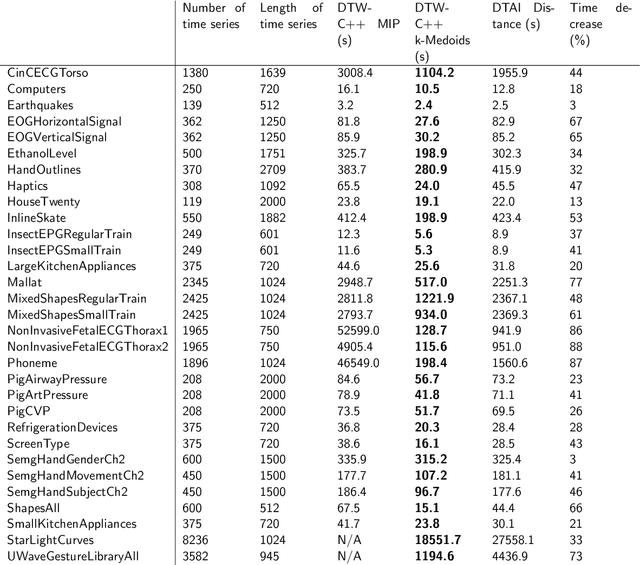
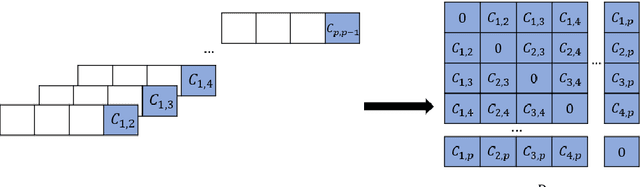
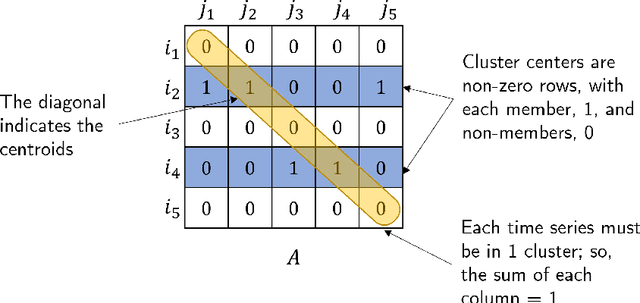
We present an approach for computationally efficient dynamic time warping (DTW) and clustering of time-series data. The method frames the dynamic warping of time series datasets as an optimisation problem solved using dynamic programming, and then clusters time series data by solving a second optimisation problem using mixed-integer programming (MIP). There is also an option to use k-medoids clustering for increased speed, when a certificate for global optimality is not essential. The improved efficiency of our approach is due to task-level parallelisation of the clustering alongside DTW. Our approach was tested using the UCR Time Series Archive, and was found to be, on average, 33% faster than the next fastest option when using the same clustering method. This increases to 64% faster when considering only larger datasets (with more than 1000 time series). The MIP clustering is most effective on small numbers of longer time series, because the DTW computation is faster than other approaches, but the clustering problem becomes increasingly computationally expensive as the number of time series to be clustered increases.