 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinned Mean Field Langevin Dynamics
May 27, 2026Several important learning tasks can be formulated as minimizing an entropy-regularized objective over an appropriate space of probability distributions. Mean-field Langevin dynamics (MFLD) facilitate computation in this general context, casting the minimizer as the invariant distribution of a McKean--Vlasov process, which can be numerically discretized using $N$ particles and thus simulated. However, simulating this interacting particle system has computational complexity of order $N^2$. Motivated by recent research into \emph{kernel thinning}, we propose \texttt{KT-MFLD}, in which each particle interacts only with a thinned particle coreset of size $\mathcal{O}(N^{\frac{1}{2}})$. \texttt{KT-MFLD} thus reduces the computational complexity to order $N^{\frac{3}{2}}$ while, under mild regularity conditions, achieving the same convergence guarantees (up to logarithmic factors) as MFLD. Our theoretical analysis is empirically confirmed on tasks including the training of student-teacher neural networks, quantization with maximum mean discrepancy, and computation of predictively-oriented posteriors in a post-Bayesian framework.
Conservative neural posterior estimation via distributionally robust training
May 27, 2026Simulation-based inference with neural posterior estimation (NPE) often yields overconfident and unreliable posteriors under limited simulation budgets. To address this, we propose DRO-NPE, a distributionally robust approach that replaces the standard NPE objective with a worst-case loss over a Wasserstein ambiguity set. We introduce KL-based metrics for miscoverage and miscalibration, and use these to show that the DRO-NPE objective controls overfitting and reduces posterior overconfidence. Our method is tractable, parallelisable, and readily integrates with standard normalising flows. Across benchmark SBI tasks, DRO-NPE consistently improves coverage and calibration, while narrowing the gap between empirical and population NPE loss, leading to more reliable inference in low-simulation regimes.
Amortised and provably-robust simulation-based inference
Feb 17, 2026Complex simulator-based models are now routinely used to perform inference across the sciences and engineering, but existing inference methods are often unable to account for outliers and other extreme values in data which occur due to faulty measurement instruments or human error. In this paper, we introduce a novel approach to simulation-based inference grounded in generalised Bayesian inference and a neural approximation of a weighted score-matching loss. This leads to a method that is both amortised and provably robust to outliers, a combination not achieved by existing approaches. Furthermore, through a carefully chosen conditional density model, we demonstrate that inference can be further simplified and performed without the need for Markov chain Monte Carlo sampling, thereby offering significant computational advantages, with complexity that is only a small fraction of that of current state-of-the-art approaches.
BayesSum: Bayesian Quadrature in Discrete Spaces
Dec 18, 2025This paper addresses the challenging computational problem of estimating intractable expectations over discrete domains. Existing approaches, including Monte Carlo and Russian Roulette estimators, are consistent but often require a large number of samples to achieve accurate results. We propose a novel estimator, \emph{BayesSum}, which is an extension of Bayesian quadrature to discrete domains. It is more sample efficient than alternatives due to its ability to make use of prior information about the integrand through a Gaussian process. We show this through theory, deriving a convergence rate significantly faster than Monte Carlo in a broad range of settings. We also demonstrate empirically that our proposed method does indeed require fewer samples on several synthetic settings as well as for parameter estimation for Conway-Maxwell-Poisson and Potts models.
Multi-Output Robust and Conjugate Gaussian Processes
Oct 30, 2025Multi-output Gaussian process (MOGP) regression allows modelling dependencies among multiple correlated response variables. Similarly to standard Gaussian processes, MOGPs are sensitive to model misspecification and outliers, which can distort predictions within individual outputs. This situation can be further exacerbated by multiple anomalous response variables whose errors propagate due to correlations between outputs. To handle this situation, we extend and generalise the robust and conjugate Gaussian process (RCGP) framework introduced by Altamirano et al. (2024). This results in the multi-output RCGP (MO-RCGP): a provably robust MOGP that is conjugate, and jointly captures correlations across outputs. We thoroughly evaluate our approach through applications in finance and cancer research.
Multilevel neural simulation-based inference
Jun 06, 2025



Neural simulation-based inference (SBI) is a popular set of methods for Bayesian inference when models are only available in the form of a simulator. These methods are widely used in the sciences and engineering, where writing down a likelihood can be significantly more challenging than constructing a simulator. However, the performance of neural SBI can suffer when simulators are computationally expensive, thereby limiting the number of simulations that can be performed. In this paper, we propose a novel approach to neural SBI which leverages multilevel Monte Carlo techniques for settings where several simulators of varying cost and fidelity are available. We demonstrate through both theoretical analysis and extensive experiments that our method can significantly enhance the accuracy of SBI methods given a fixed computational budget.
Stationary MMD Points for Cubature
May 27, 2025Approximation of a target probability distribution using a finite set of points is a problem of fundamental importance, arising in cubature, data compression, and optimisation. Several authors have proposed to select points by minimising a maximum mean discrepancy (MMD), but the non-convexity of this objective precludes global minimisation in general. Instead, we consider \emph{stationary} points of the MMD which, in contrast to points globally minimising the MMD, can be accurately computed. Our main theoretical contribution is the (perhaps surprising) result that, for integrands in the associated reproducing kernel Hilbert space, the cubature error of stationary MMD points vanishes \emph{faster} than the MMD. Motivated by this \emph{super-convergence} property, we consider discretised gradient flows as a practical strategy for computing stationary points of the MMD, presenting a refined convergence analysis that establishes a novel non-asymptotic finite-particle error bound, which may be of independent interest.
Kernel Quantile Embeddings and Associated Probability Metrics
May 26, 2025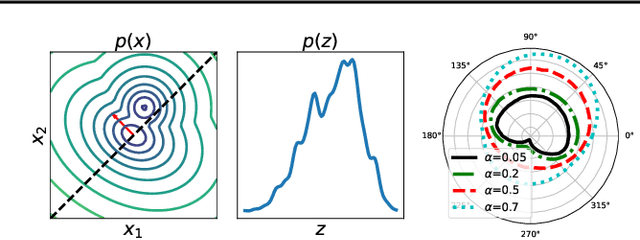
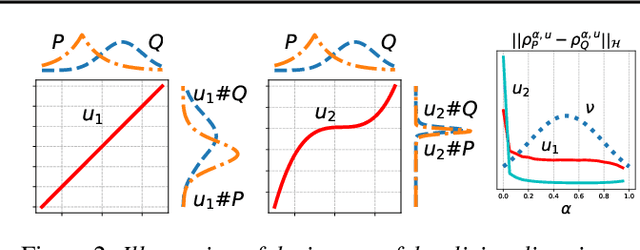
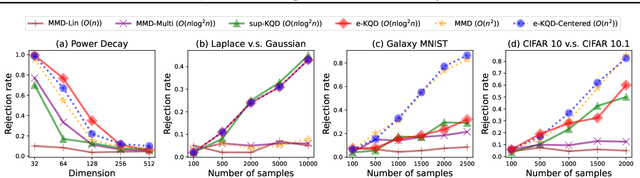
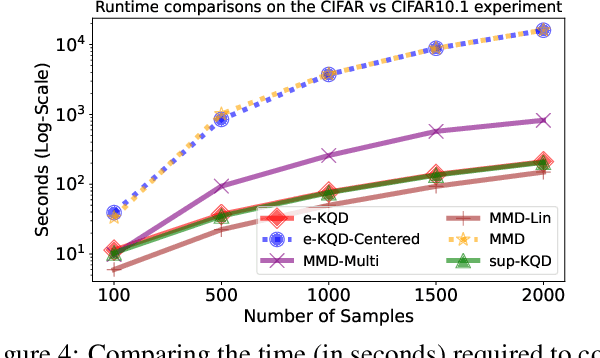
Embedding probability distributions into reproducing kernel Hilbert spaces (RKHS) has enabled powerful nonparametric methods such as the maximum mean discrepancy (MMD), a statistical distance with strong theoretical and computational properties. At its core, the MMD relies on kernel mean embeddings to represent distributions as mean functions in RKHS. However, it remains unclear if the mean function is the only meaningful RKHS representation. Inspired by generalised quantiles, we introduce the notion of kernel quantile embeddings (KQEs). We then use KQEs to construct a family of distances that: (i) are probability metrics under weaker kernel conditions than MMD; (ii) recover a kernelised form of the sliced Wasserstein distance; and (iii) can be efficiently estimated with near-linear cost. Through hypothesis testing, we show that these distances offer a competitive alternative to MMD and its fast approximations.
A Dictionary of Closed-Form Kernel Mean Embeddings
Apr 26, 2025
Kernel mean embeddings -- integrals of a kernel with respect to a probability distribution -- are essential in Bayesian quadrature, but also widely used in other computational tools for numerical integration or for statistical inference based on the maximum mean discrepancy. These methods often require, or are enhanced by, the availability of a closed-form expression for the kernel mean embedding. However, deriving such expressions can be challenging, limiting the applicability of kernel-based techniques when practitioners do not have access to a closed-form embedding. This paper addresses this limitation by providing a comprehensive dictionary of known kernel mean embeddings, along with practical tools for deriving new embeddings from known ones. We also provide a Python library that includes minimal implementations of the embeddings.
Nested Expectations with Kernel Quadrature
Feb 25, 2025


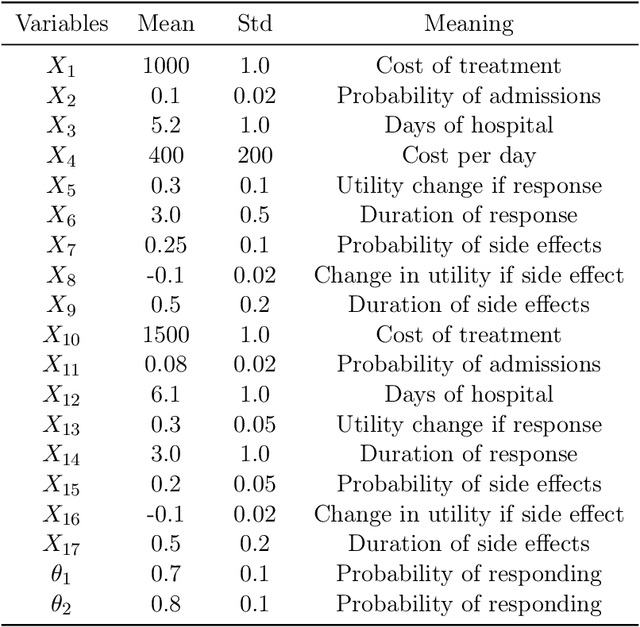
This paper considers the challenging computational task of estimating nested expectations. Existing algorithms, such as nested Monte Carlo or multilevel Monte Carlo, are known to be consistent but require a large number of samples at both inner and outer levels to converge. Instead, we propose a novel estimator consisting of nested kernel quadrature estimators and we prove that it has a faster convergence rate than all baseline methods when the integrands have sufficient smoothness. We then demonstrate empirically that our proposed method does indeed require fewer samples to estimate nested expectations on real-world applications including Bayesian optimisation, option pricing, and health economics.