 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBONE: a unifying framework for Bayesian online learning in non-stationary environments
Nov 15, 2024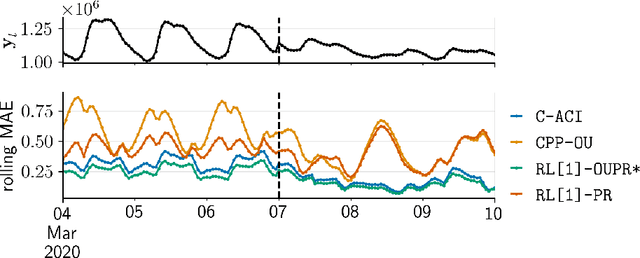
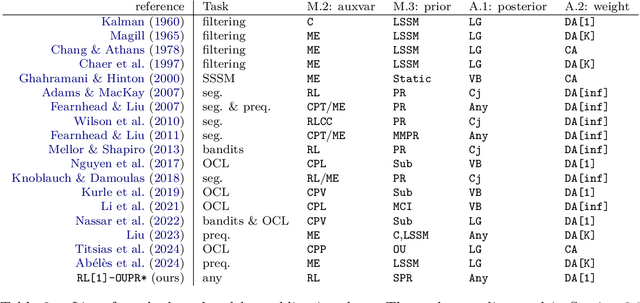
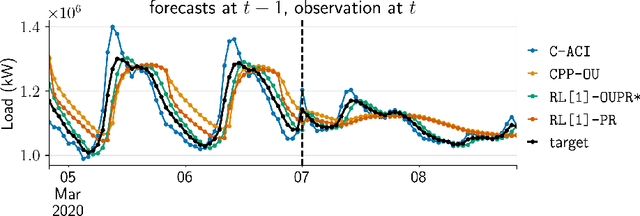
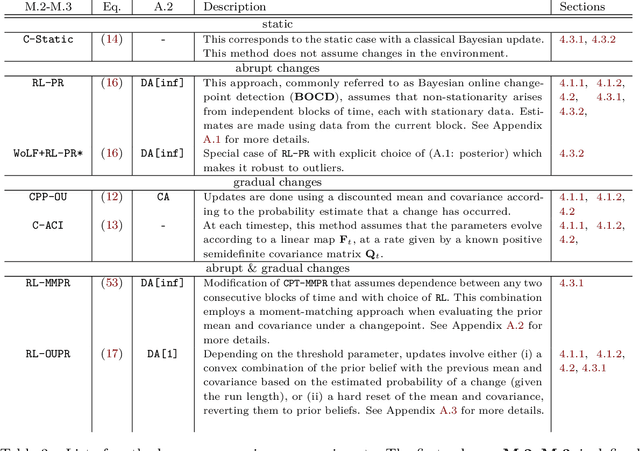
We propose a unifying framework for methods that perform Bayesian online learning in non-stationary environments. We call the framework BONE, which stands for (B)ayesian (O)nline learning in (N)on-stationary (E)nvironments. BONE provides a common structure to tackle a variety of problems, including online continual learning, prequential forecasting, and contextual bandits. The framework requires specifying three modelling choices: (i) a model for measurements (e.g., a neural network), (ii) an auxiliary process to model non-stationarity (e.g., the time since the last changepoint), and (iii) a conditional prior over model parameters (e.g., a multivariate Gaussian). The framework also requires two algorithmic choices, which we use to carry out approximate inference under this framework: (i) an algorithm to estimate beliefs (posterior distribution) about the model parameters given the auxiliary variable, and (ii) an algorithm to estimate beliefs about the auxiliary variable. We show how this modularity allows us to write many different existing methods as instances of BONE; we also use this framework to propose a new method. We then experimentally compare existing methods with our proposed new method on several datasets; we provide insights into the situations that make one method more suitable than another for a given task.
Outlier-robust Kalman Filtering through Generalised Bayes
May 09, 2024



We derive a novel, provably robust, and closed-form Bayesian update rule for online filtering in state-space models in the presence of outliers and misspecified measurement models. Our method combines generalised Bayesian inference with filtering methods such as the extended and ensemble Kalman filter. We use the former to show robustness and the latter to ensure computational efficiency in the case of nonlinear models. Our method matches or outperforms other robust filtering methods (such as those based on variational Bayes) at a much lower computational cost. We show this empirically on a range of filtering problems with outlier measurements, such as object tracking, state estimation in high-dimensional chaotic systems, and online learning of neural networks.
Robust Detection of Lead-Lag Relationships in Lagged Multi-Factor Models
May 11, 2023



In multivariate time series systems, key insights can be obtained by discovering lead-lag relationships inherent in the data, which refer to the dependence between two time series shifted in time relative to one another, and which can be leveraged for the purposes of control, forecasting or clustering. We develop a clustering-driven methodology for the robust detection of lead-lag relationships in lagged multi-factor models. Within our framework, the envisioned pipeline takes as input a set of time series, and creates an enlarged universe of extracted subsequence time series from each input time series, by using a sliding window approach. We then apply various clustering techniques (e.g, K-means++ and spectral clustering), employing a variety of pairwise similarity measures, including nonlinear ones. Once the clusters have been extracted, lead-lag estimates across clusters are aggregated to enhance the identification of the consistent relationships in the original universe. Since multivariate time series are ubiquitous in a wide range of domains, we demonstrate that our method is not only able to robustly detect lead-lag relationships in financial markets, but can also yield insightful results when applied to an environmental data set.