 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeePM: Regime-Robust Deep Learning for Systematic Macro Portfolio Management
Jan 09, 2026We propose DeePM (Deep Portfolio Manager), a structured deep-learning macro portfolio manager trained end-to-end to maximize a robust, risk-adjusted utility. DeePM addresses three fundamental challenges in financial learning: (1) it resolves the asynchronous "ragged filtration" problem via a Directed Delay (Causal Sieve) mechanism that prioritizes causal impulse-response learning over information freshness; (2) it combats low signal-to-noise ratios via a Macroeconomic Graph Prior, regularizing cross-asset dependence according to economic first principles; and (3) it optimizes a distributionally robust objective where a smooth worst-window penalty serves as a differentiable proxy for Entropic Value-at-Risk (EVaR) - a window-robust utility encouraging strong performance in the most adverse historical subperiods. In large-scale backtests from 2010-2025 on 50 diversified futures with highly realistic transaction costs, DeePM attains net risk-adjusted returns that are roughly twice those of classical trend-following strategies and passive benchmarks, solely using daily closing prices. Furthermore, DeePM improves upon the state-of-the-art Momentum Transformer architecture by roughly fifty percent. The model demonstrates structural resilience across the 2010s "CTA (Commodity Trading Advisor) Winter" and the post-2020 volatility regime shift, maintaining consistent performance through the pandemic, inflation shocks, and the subsequent higher-for-longer environment. Ablation studies confirm that strictly lagged cross-sectional attention, graph prior, principled treatment of transaction costs, and robust minimax optimization are the primary drivers of this generalization capability.
Fusing Narrative Semantics for Financial Volatility Forecasting
Oct 23, 2025We introduce M2VN: Multi-Modal Volatility Network, a novel deep learning-based framework for financial volatility forecasting that unifies time series features with unstructured news data. M2VN leverages the representational power of deep neural networks to address two key challenges in this domain: (i) aligning and fusing heterogeneous data modalities, numerical financial data and textual information, and (ii) mitigating look-ahead bias that can undermine the validity of financial models. To achieve this, M2VN combines open-source market features with news embeddings generated by Time Machine GPT, a recently introduced point-in-time LLM, ensuring temporal integrity. An auxiliary alignment loss is introduced to enhance the integration of structured and unstructured data within the deep learning architecture. Extensive experiments demonstrate that M2VN consistently outperforms existing baselines, underscoring its practical value for risk management and financial decision-making in dynamic markets.
Stories that (are) Move(d by) Markets: A Causal Exploration of Market Shocks and Semantic Shifts across Different Partisan Groups
Feb 20, 2025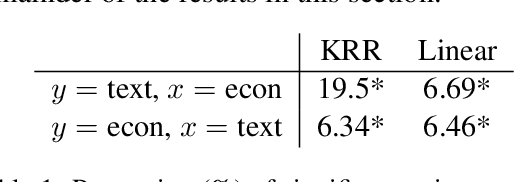
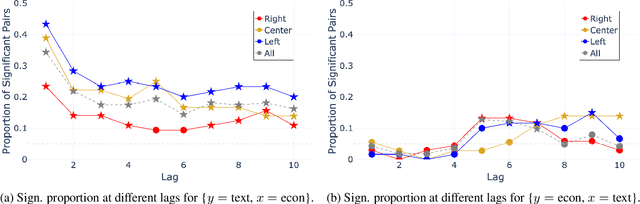
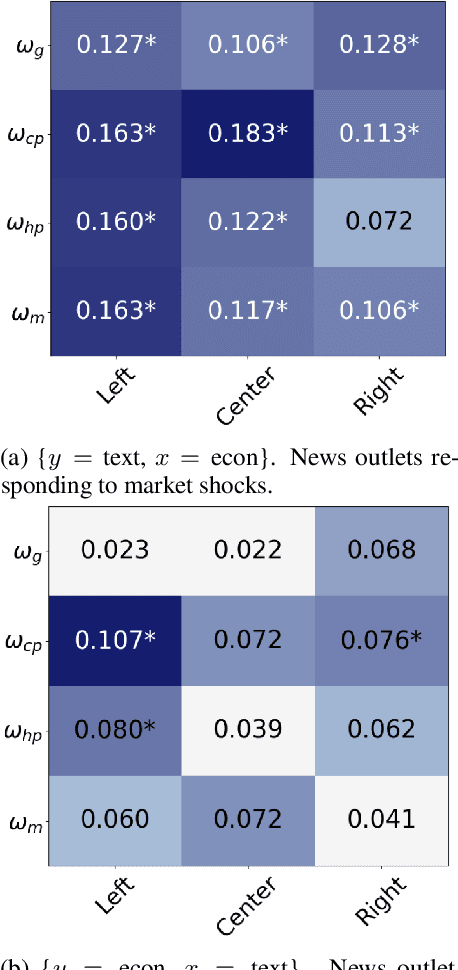
Macroeconomic fluctuations and the narratives that shape them form a mutually reinforcing cycle: public discourse can spur behavioural changes leading to economic shifts, which then result in changes in the stories that propagate. We show that shifts in semantic embedding space can be causally linked to financial market shocks -- deviations from the expected market behaviour. Furthermore, we show how partisanship can influence the predictive power of text for market fluctuations and shape reactions to those same shocks. We also provide some evidence that text-based signals are particularly salient during unexpected events such as COVID-19, highlighting the value of language data as an exogenous variable in economic forecasting. Our findings underscore the bidirectional relationship between news outlets and market shocks, offering a novel empirical approach to studying their effect on each other.
LOB-Bench: Benchmarking Generative AI for Finance - an Application to Limit Order Book Data
Feb 13, 2025While financial data presents one of the most challenging and interesting sequence modelling tasks due to high noise, heavy tails, and strategic interactions, progress in this area has been hindered by the lack of consensus on quantitative evaluation paradigms. To address this, we present LOB-Bench, a benchmark, implemented in python, designed to evaluate the quality and realism of generative message-by-order data for limit order books (LOB) in the LOBSTER format. Our framework measures distributional differences in conditional and unconditional statistics between generated and real LOB data, supporting flexible multivariate statistical evaluation. The benchmark also includes features commonly used LOB statistics such as spread, order book volumes, order imbalance, and message inter-arrival times, along with scores from a trained discriminator network. Lastly, LOB-Bench contains "market impact metrics", i.e. the cross-correlations and price response functions for specific events in the data. We benchmark generative autoregressive state-space models, a (C)GAN, as well as a parametric LOB model and find that the autoregressive GenAI approach beats traditional model classes.
When Dimensionality Hurts: The Role of LLM Embedding Compression for Noisy Regression Tasks
Feb 04, 2025



Large language models (LLMs) have shown remarkable success in language modelling due to scaling laws found in model size and the hidden dimension of the model's text representation. Yet, we demonstrate that compressed representations of text can yield better performance in LLM-based regression tasks. In this paper, we compare the relative performance of embedding compression in three different signal-to-noise contexts: financial return prediction, writing quality assessment and review scoring. Our results show that compressing embeddings, in a minimally supervised manner using an autoencoder's hidden representation, can mitigate overfitting and improve performance on noisy tasks, such as financial return prediction; but that compression reduces performance on tasks that have high causal dependencies between the input and target data. Our results suggest that the success of interpretable compressed representations such as sentiment may be due to a regularising effect.
Position: Empowering Time Series Reasoning with Multimodal LLMs
Feb 03, 2025



Understanding time series data is crucial for multiple real-world applications. While large language models (LLMs) show promise in time series tasks, current approaches often rely on numerical data alone, overlooking the multimodal nature of time-dependent information, such as textual descriptions, visual data, and audio signals. Moreover, these methods underutilize LLMs' reasoning capabilities, limiting the analysis to surface-level interpretations instead of deeper temporal and multimodal reasoning. In this position paper, we argue that multimodal LLMs (MLLMs) can enable more powerful and flexible reasoning for time series analysis, enhancing decision-making and real-world applications. We call on researchers and practitioners to leverage this potential by developing strategies that prioritize trust, interpretability, and robust reasoning in MLLMs. Lastly, we highlight key research directions, including novel reasoning paradigms, architectural innovations, and domain-specific applications, to advance time series reasoning with MLLMs.
Decision-informed Neural Networks with Large Language Model Integration for Portfolio Optimization
Feb 02, 2025This paper addresses the critical disconnect between prediction and decision quality in portfolio optimization by integrating Large Language Models (LLMs) with decision-focused learning. We demonstrate both theoretically and empirically that minimizing the prediction error alone leads to suboptimal portfolio decisions. We aim to exploit the representational power of LLMs for investment decisions. An attention mechanism processes asset relationships, temporal dependencies, and macro variables, which are then directly integrated into a portfolio optimization layer. This enables the model to capture complex market dynamics and align predictions with the decision objectives. Extensive experiments on S\&P100 and DOW30 datasets show that our model consistently outperforms state-of-the-art deep learning models. In addition, gradient-based analyses show that our model prioritizes the assets most crucial to decision making, thus mitigating the effects of prediction errors on portfolio performance. These findings underscore the value of integrating decision objectives into predictions for more robust and context-aware portfolio management.
Unlocking the Power of LSTM for Long Term Time Series Forecasting
Aug 19, 2024


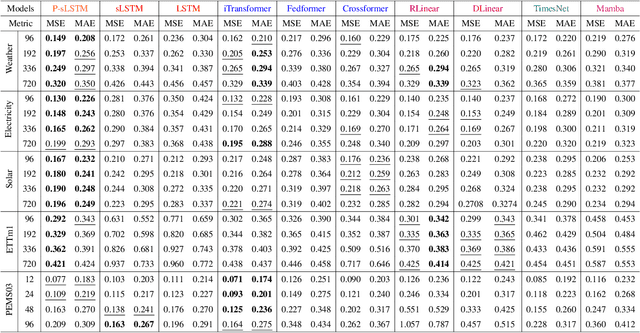
Traditional recurrent neural network architectures, such as long short-term memory neural networks (LSTM), have historically held a prominent role in time series forecasting (TSF) tasks. While the recently introduced sLSTM for Natural Language Processing (NLP) introduces exponential gating and memory mixing that are beneficial for long term sequential learning, its potential short memory issue is a barrier to applying sLSTM directly in TSF. To address this, we propose a simple yet efficient algorithm named P-sLSTM, which is built upon sLSTM by incorporating patching and channel independence. These modifications substantially enhance sLSTM's performance in TSF, achieving state-of-the-art results. Furthermore, we provide theoretical justifications for our design, and conduct extensive comparative and analytical experiments to fully validate the efficiency and superior performance of our model.
Deep Learning for Options Trading: An End-To-End Approach
Jul 31, 2024



We introduce a novel approach to options trading strategies using a highly scalable and data-driven machine learning algorithm. In contrast to traditional approaches that often require specifications of underlying market dynamics or assumptions on an option pricing model, our models depart fundamentally from the need for these prerequisites, directly learning non-trivial mappings from market data to optimal trading signals. Backtesting on more than a decade of option contracts for equities listed on the S&P 100, we demonstrate that deep learning models trained according to our end-to-end approach exhibit significant improvements in risk-adjusted performance over existing rules-based trading strategies. We find that incorporating turnover regularization into the models leads to further performance enhancements at prohibitively high levels of transaction costs.
Traditional Methods Outperform Generative LLMs at Forecasting Credit Ratings
Jul 24, 2024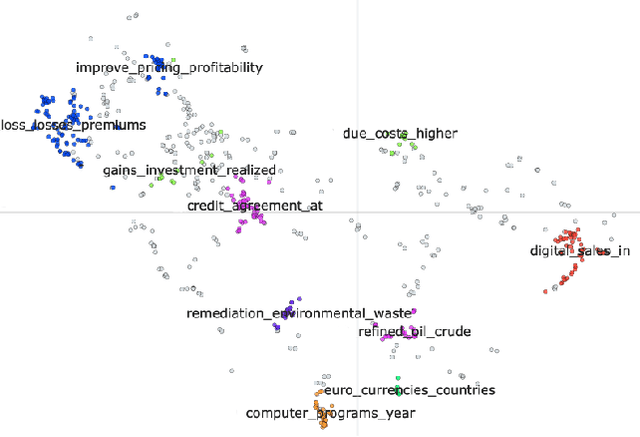
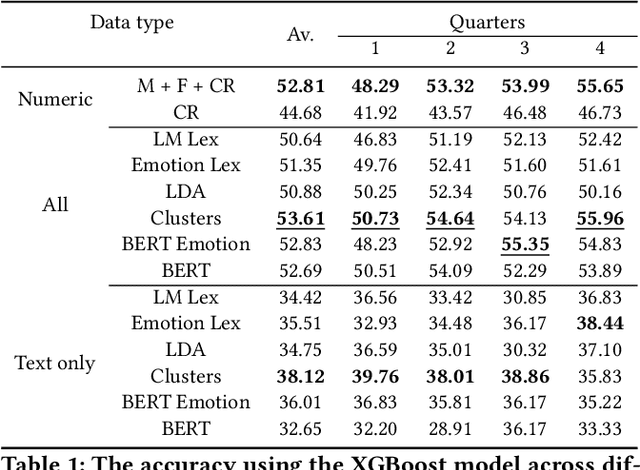
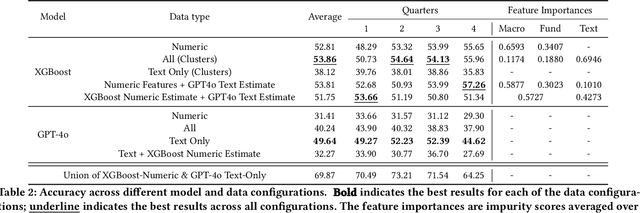
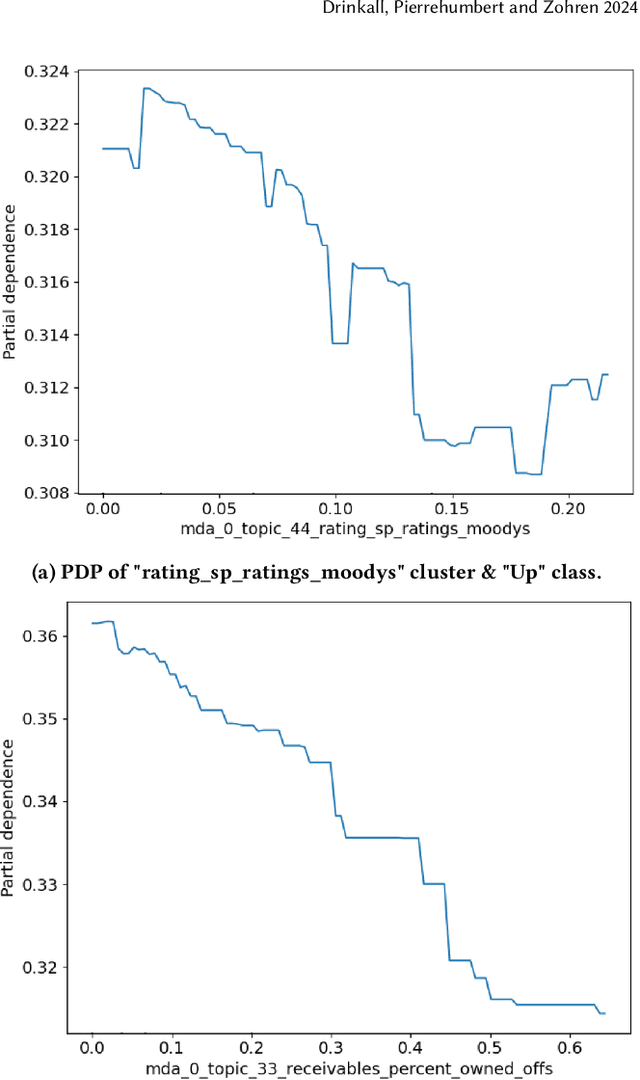
Large Language Models (LLMs) have been shown to perform well for many downstream tasks. Transfer learning can enable LLMs to acquire skills that were not targeted during pre-training. In financial contexts, LLMs can sometimes beat well-established benchmarks. This paper investigates how well LLMs perform in the task of forecasting corporate credit ratings. We show that while LLMs are very good at encoding textual information, traditional methods are still very competitive when it comes to encoding numeric and multimodal data. For our task, current LLMs perform worse than a more traditional XGBoost architecture that combines fundamental and macroeconomic data with high-density text-based embedding features.