 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Interpretable Time Series Foundation Models
Jul 10, 2025In this paper, we investigate the distillation of time series reasoning capabilities into small, instruction-tuned language models as a step toward building interpretable time series foundation models. Leveraging a synthetic dataset of mean-reverting time series with systematically varied trends and noise levels, we generate natural language annotations using a large multimodal model and use these to supervise the fine-tuning of compact Qwen models. We introduce evaluation metrics that assess the quality of the distilled reasoning - focusing on trend direction, noise intensity, and extremum localization - and show that the post-trained models acquire meaningful interpretive capabilities. Our results highlight the feasibility of compressing time series understanding into lightweight, language-capable models suitable for on-device or privacy-sensitive deployment. This work contributes a concrete foundation toward developing small, interpretable models that explain temporal patterns in natural language.
TADACap: Time-series Adaptive Domain-Aware Captioning
Apr 15, 2025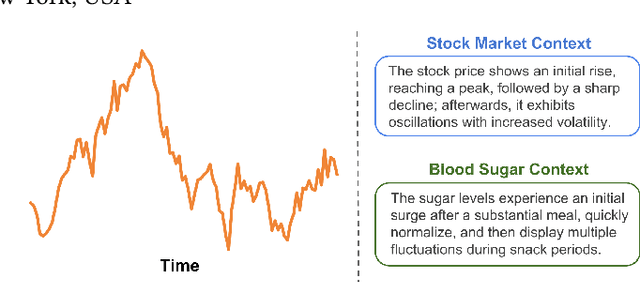



While image captioning has gained significant attention, the potential of captioning time-series images, prevalent in areas like finance and healthcare, remains largely untapped. Existing time-series captioning methods typically offer generic, domain-agnostic descriptions of time-series shapes and struggle to adapt to new domains without substantial retraining. To address these limitations, we introduce TADACap, a retrieval-based framework to generate domain-aware captions for time-series images, capable of adapting to new domains without retraining. Building on TADACap, we propose a novel retrieval strategy that retrieves diverse image-caption pairs from a target domain database, namely TADACap-diverse. We benchmarked TADACap-diverse against state-of-the-art methods and ablation variants. TADACap-diverse demonstrates comparable semantic accuracy while requiring significantly less annotation effort.
Mixup Regularization: A Probabilistic Perspective
Feb 19, 2025In recent years, mixup regularization has gained popularity as an effective way to improve the generalization performance of deep learning models by training on convex combinations of training data. While many mixup variants have been explored, the proper adoption of the technique to conditional density estimation and probabilistic machine learning remains relatively unexplored. This work introduces a novel framework for mixup regularization based on probabilistic fusion that is better suited for conditional density estimation tasks. For data distributed according to a member of the exponential family, we show that likelihood functions can be analytically fused using log-linear pooling. We further propose an extension of probabilistic mixup, which allows for fusion of inputs at an arbitrary intermediate layer of the neural network. We provide a theoretical analysis comparing our approach to standard mixup variants. Empirical results on synthetic and real datasets demonstrate the benefits of our proposed framework compared to existing mixup variants.
LOB-Bench: Benchmarking Generative AI for Finance - an Application to Limit Order Book Data
Feb 13, 2025While financial data presents one of the most challenging and interesting sequence modelling tasks due to high noise, heavy tails, and strategic interactions, progress in this area has been hindered by the lack of consensus on quantitative evaluation paradigms. To address this, we present LOB-Bench, a benchmark, implemented in python, designed to evaluate the quality and realism of generative message-by-order data for limit order books (LOB) in the LOBSTER format. Our framework measures distributional differences in conditional and unconditional statistics between generated and real LOB data, supporting flexible multivariate statistical evaluation. The benchmark also includes features commonly used LOB statistics such as spread, order book volumes, order imbalance, and message inter-arrival times, along with scores from a trained discriminator network. Lastly, LOB-Bench contains "market impact metrics", i.e. the cross-correlations and price response functions for specific events in the data. We benchmark generative autoregressive state-space models, a (C)GAN, as well as a parametric LOB model and find that the autoregressive GenAI approach beats traditional model classes.
Variational Neural Stochastic Differential Equations with Change Points
Nov 01, 2024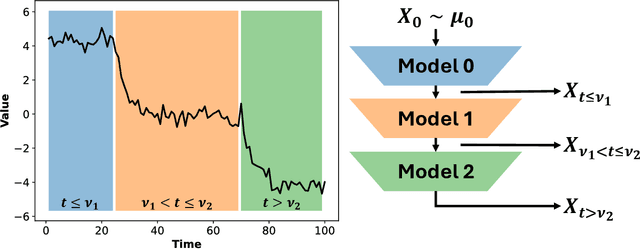


In this work, we explore modeling change points in time-series data using neural stochastic differential equations (neural SDEs). We propose a novel model formulation and training procedure based on the variational autoencoder (VAE) framework for modeling time-series as a neural SDE. Unlike existing algorithms training neural SDEs as VAEs, our proposed algorithm only necessitates a Gaussian prior of the initial state of the latent stochastic process, rather than a Wiener process prior on the entire latent stochastic process. We develop two methodologies for modeling and estimating change points in time-series data with distribution shifts. Our iterative algorithm alternates between updating neural SDE parameters and updating the change points based on either a maximum likelihood-based approach or a change point detection algorithm using the sequential likelihood ratio test. We provide a theoretical analysis of this proposed change point detection scheme. Finally, we present an empirical evaluation that demonstrates the expressive power of our proposed model, showing that it can effectively model both classical parametric SDEs and some real datasets with distribution shifts.
A Language Model-Guided Framework for Mining Time Series with Distributional Shifts
Jun 07, 2024Effective utilization of time series data is often constrained by the scarcity of data quantity that reflects complex dynamics, especially under the condition of distributional shifts. Existing datasets may not encompass the full range of statistical properties required for robust and comprehensive analysis. And privacy concerns can further limit their accessibility in domains such as finance and healthcare. This paper presents an approach that utilizes large language models and data source interfaces to explore and collect time series datasets. While obtained from external sources, the collected data share critical statistical properties with primary time series datasets, making it possible to model and adapt to various scenarios. This method enlarges the data quantity when the original data is limited or lacks essential properties. It suggests that collected datasets can effectively supplement existing datasets, especially involving changes in data distribution. We demonstrate the effectiveness of the collected datasets through practical examples and show how time series forecasting foundation models fine-tuned on these datasets achieve comparable performance to those models without fine-tuning.
Evaluating Large Language Models on Time Series Feature Understanding: A Comprehensive Taxonomy and Benchmark
Apr 25, 2024Large Language Models (LLMs) offer the potential for automatic time series analysis and reporting, which is a critical task across many domains, spanning healthcare, finance, climate, energy, and many more. In this paper, we propose a framework for rigorously evaluating the capabilities of LLMs on time series understanding, encompassing both univariate and multivariate forms. We introduce a comprehensive taxonomy of time series features, a critical framework that delineates various characteristics inherent in time series data. Leveraging this taxonomy, we have systematically designed and synthesized a diverse dataset of time series, embodying the different outlined features. This dataset acts as a solid foundation for assessing the proficiency of LLMs in comprehending time series. Our experiments shed light on the strengths and limitations of state-of-the-art LLMs in time series understanding, revealing which features these models readily comprehend effectively and where they falter. In addition, we uncover the sensitivity of LLMs to factors including the formatting of the data, the position of points queried within a series and the overall time series length.
LLM-driven Imitation of Subrational Behavior : Illusion or Reality?
Feb 13, 2024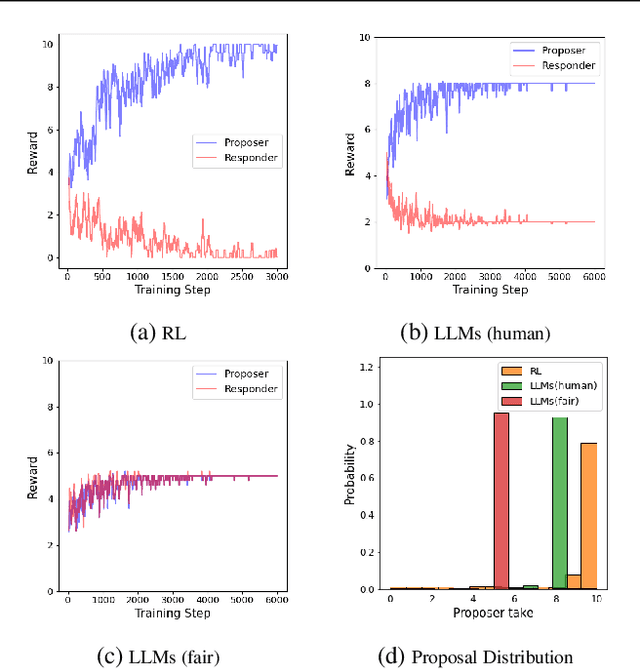

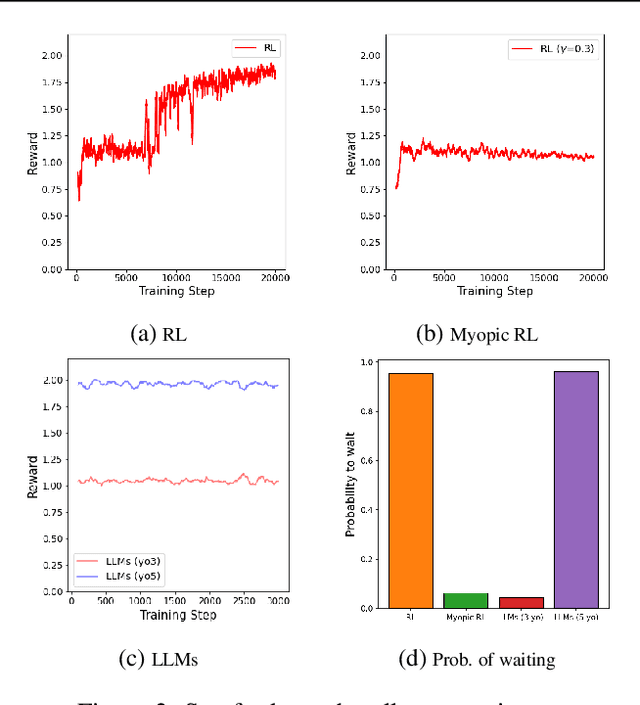

Modeling subrational agents, such as humans or economic households, is inherently challenging due to the difficulty in calibrating reinforcement learning models or collecting data that involves human subjects. Existing work highlights the ability of Large Language Models (LLMs) to address complex reasoning tasks and mimic human communication, while simulation using LLMs as agents shows emergent social behaviors, potentially improving our comprehension of human conduct. In this paper, we propose to investigate the use of LLMs to generate synthetic human demonstrations, which are then used to learn subrational agent policies though Imitation Learning. We make an assumption that LLMs can be used as implicit computational models of humans, and propose a framework to use synthetic demonstrations derived from LLMs to model subrational behaviors that are characteristic of humans (e.g., myopic behavior or preference for risk aversion). We experimentally evaluate the ability of our framework to model sub-rationality through four simple scenarios, including the well-researched ultimatum game and marshmallow experiment. To gain confidence in our framework, we are able to replicate well-established findings from prior human studies associated with the above scenarios. We conclude by discussing the potential benefits, challenges and limitations of our framework.
Synthetic Data Applications in Finance
Dec 29, 2023

Synthetic data has made tremendous strides in various commercial settings including finance, healthcare, and virtual reality. We present a broad overview of prototypical applications of synthetic data in the financial sector and in particular provide richer details for a few select ones. These cover a wide variety of data modalities including tabular, time-series, event-series, and unstructured arising from both markets and retail financial applications. Since finance is a highly regulated industry, synthetic data is a potential approach for dealing with issues related to privacy, fairness, and explainability. Various metrics are utilized in evaluating the quality and effectiveness of our approaches in these applications. We conclude with open directions in synthetic data in the context of the financial domain.
Neural Stochastic Differential Equations with Change Points: A Generative Adversarial Approach
Dec 20, 2023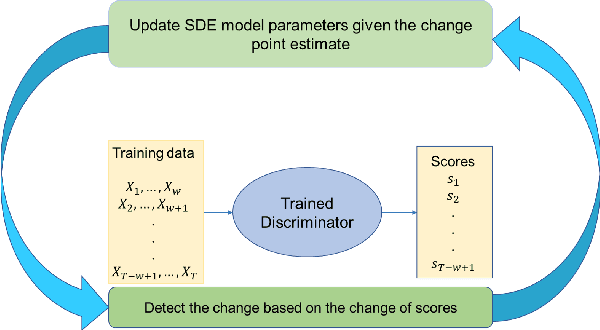
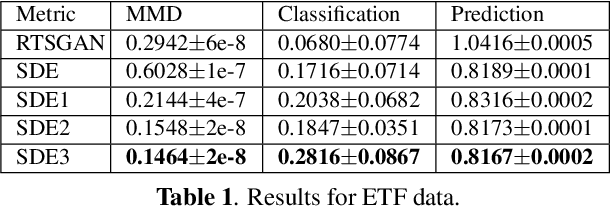

Stochastic differential equations (SDEs) have been widely used to model real world random phenomena. Existing works mainly focus on the case where the time series is modeled by a single SDE, which might be restrictive for modeling time series with distributional shift. In this work, we propose a change point detection algorithm for time series modeled as neural SDEs. Given a time series dataset, the proposed method jointly learns the unknown change points and the parameters of distinct neural SDE models corresponding to each change point. Specifically, the SDEs are learned under the framework of generative adversarial networks (GANs) and the change points are detected based on the output of the GAN discriminator in a forward pass. At each step of the proposed algorithm, the change points and the SDE model parameters are updated in an alternating fashion. Numerical results on both synthetic and real datasets are provided to validate the performance of our algorithm in comparison to classical change point detection benchmarks, standard GAN-based neural SDEs, and other state-of-the-art deep generative models for time series data.