 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning Task Shielding: Detecting and Repairing Flaws in Planning Tasks through Turning them Unsolvable
Apr 08, 2026Most research in planning focuses on generating a plan to achieve a desired set of goals. However, a goal specification can also be used to encode a property that should never hold, allowing a planner to identify a trace that would reach a flawed state. In such cases, the objective may shift to modifying the planning task to ensure that the flawed state is never reached-in other words, to make the planning task unsolvable. In this paper we introduce planning task shielding: the problem of detecting and repairing flaws in planning tasks. We propose $allmin$, an optimal algorithm that solves these tasks by minimally modifying the original actions to render the planning task unsolvable. We empirically evaluate the performance of $allmin$ in shielding planning tasks of increasing size, showing how it can effectively shield the system by turning the planning task unsolvable.
TradeFM: A Generative Foundation Model for Trade-flow and Market Microstructure
Feb 27, 2026Foundation models have transformed domains from language to genomics by learning general-purpose representations from large-scale, heterogeneous data. We introduce TradeFM, a 524M-parameter generative Transformer that brings this paradigm to market microstructure, learning directly from billions of trade events across >9K equities. To enable cross-asset generalization, we develop scale-invariant features and a universal tokenization scheme that map the heterogeneous, multi-modal event stream of order flow into a unified discrete sequence -- eliminating asset-specific calibration. Integrated with a deterministic market simulator, TradeFM-generated rollouts reproduce key stylized facts of financial returns, including heavy tails, volatility clustering, and absence of return autocorrelation. Quantitatively, TradeFM achieves 2-3x lower distributional error than Compound Hawkes baselines and generalizes zero-shot to geographically out-of-distribution APAC markets with moderate perplexity degradation. Together, these results suggest that scale-invariant trade representations capture transferable structure in market microstructure, opening a path toward synthetic data generation, stress testing, and learning-based trading agents.
Semantic Partial Grounding via LLMs
Feb 25, 2026Grounding is a critical step in classical planning, yet it often becomes a computational bottleneck due to the exponential growth in grounded actions and atoms as task size increases. Recent advances in partial grounding have addressed this challenge by incrementally grounding only the most promising operators, guided by predictive models. However, these approaches primarily rely on relational features or learned embeddings and do not leverage the textual and structural cues present in PDDL descriptions. We propose SPG-LLM, which uses LLMs to analyze the domain and problem files to heuristically identify potentially irrelevant objects, actions, and predicates prior to grounding, significantly reducing the size of the grounded task. Across seven hard-to-ground benchmarks, SPG-LLM achieves faster grounding-often by orders of magnitude-while delivering comparable or better plan costs in some domains.
The Subset Sum Matching Problem
Aug 26, 2025



This paper presents a new combinatorial optimisation task, the Subset Sum Matching Problem (SSMP), which is an abstraction of common financial applications such as trades reconciliation. We present three algorithms, two suboptimal and one optimal, to solve this problem. We also generate a benchmark to cover different instances of SSMP varying in complexity, and carry out an experimental evaluation to assess the performance of the approaches.
GenPlanX. Generation of Plans and Execution
Jun 12, 2025Classical AI Planning techniques generate sequences of actions for complex tasks. However, they lack the ability to understand planning tasks when provided using natural language. The advent of Large Language Models (LLMs) has introduced novel capabilities in human-computer interaction. In the context of planning tasks, LLMs have shown to be particularly good in interpreting human intents among other uses. This paper introduces GenPlanX that integrates LLMs for natural language-based description of planning tasks, with a classical AI planning engine, alongside an execution and monitoring framework. We demonstrate the efficacy of GenPlanX in assisting users with office-related tasks, highlighting its potential to streamline workflows and enhance productivity through seamless human-AI collaboration.
On the Temporal Question-Answering Capabilities of Large Language Models Over Anonymized Data
Apr 10, 2025The applicability of Large Language Models (LLMs) in temporal reasoning tasks over data that is not present during training is still a field that remains to be explored. In this paper we work on this topic, focusing on structured and semi-structured anonymized data. We not only develop a direct LLM pipeline, but also compare various methodologies and conduct an in-depth analysis. We identified and examined seventeen common temporal reasoning tasks in natural language, focusing on their algorithmic components. To assess LLM performance, we created the \textit{Reasoning and Answering Temporal Ability} dataset (RATA), featuring semi-structured anonymized data to ensure reliance on reasoning rather than on prior knowledge. We compared several methodologies, involving SoTA techniques such as Tree-of-Thought, self-reflexion and code execution, tuned specifically for this scenario. Our results suggest that achieving scalable and reliable solutions requires more than just standalone LLMs, highlighting the need for integrated approaches.
The Value of Goal Commitment in Planning
Mar 12, 2025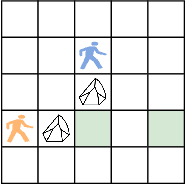
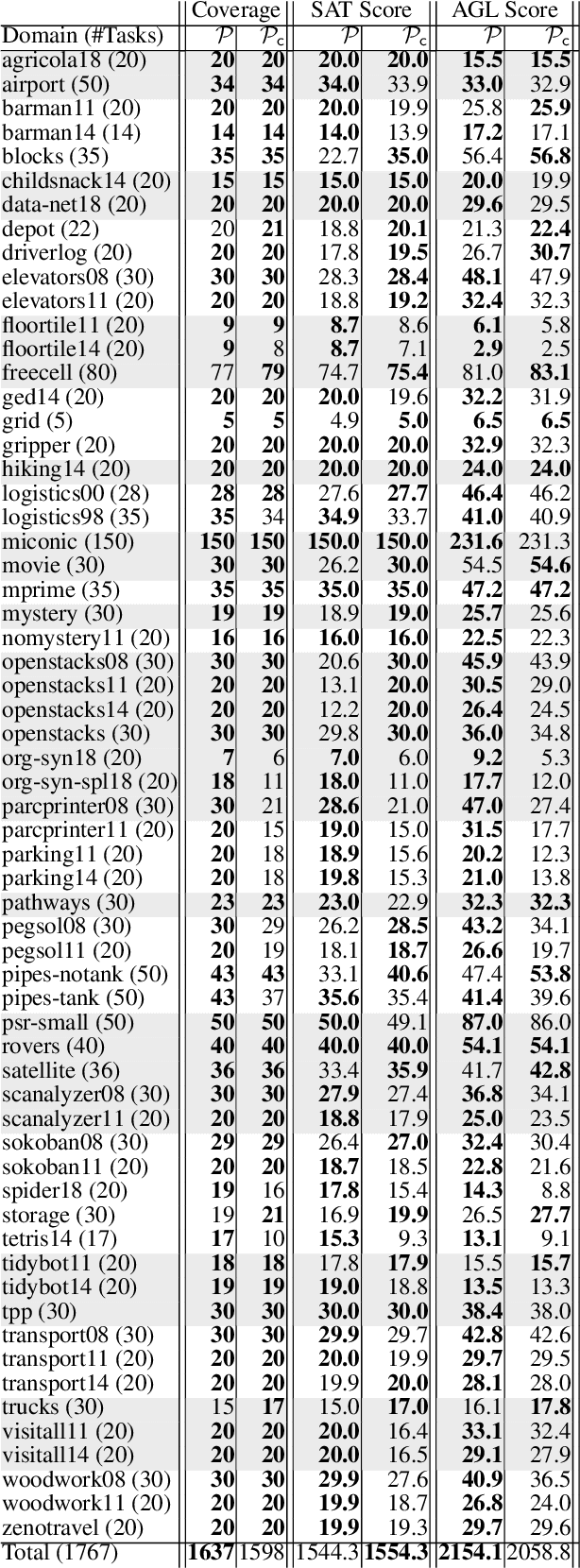
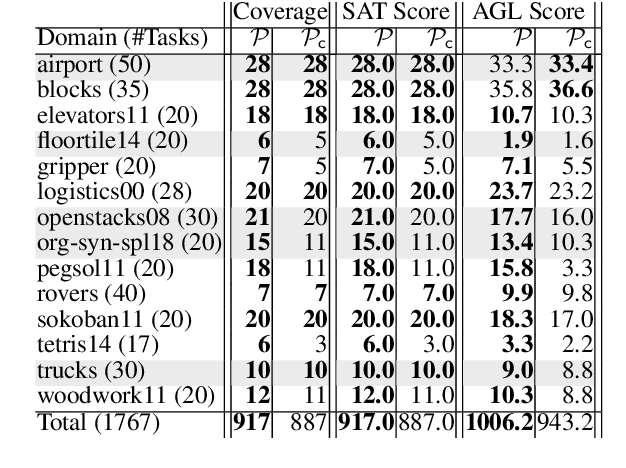
In this paper, we revisit the concept of goal commitment from early planners in the presence of current forward chaining heuristic planners. We present a compilation that extends the original planning task with commit actions that enforce the persistence of specific goals once achieved, thereby committing to them in the search sub-tree. This approach imposes a specific goal achievement order in parts of the search tree, potentially introducing dead-end states. This can reduce search effort if the goal achievement order is correct. Otherwise, the search algorithm can expand nodes in the open list where goals do not persist. Experimental results demonstrate that the reformulated tasks suit state-of-the-art agile planners, enabling them to find better
Hypercone Assisted Contour Generation for Out-of-Distribution Detection
Jan 17, 2025Recent advances in the field of out-of-distribution (OOD) detection have placed great emphasis on learning better representations suited to this task. While there are distance-based approaches, distributional awareness has seldom been exploited for better performance. We present HAC$_k$-OOD, a novel OOD detection method that makes no distributional assumption about the data, but automatically adapts to its distribution. Specifically, HAC$_k$-OOD constructs a set of hypercones by maximizing the angular distance to neighbors in a given data-point's vicinity to approximate the contour within which in-distribution (ID) data-points lie. Experimental results show state-of-the-art FPR@95 and AUROC performance on Near-OOD detection and on Far-OOD detection on the challenging CIFAR-100 benchmark without explicitly training for OOD performance.
TRIM: Token Reduction and Inference Modeling for Cost-Effective Language Generation
Dec 10, 2024



The inference cost of Large Language Models (LLMs) is a significant challenge due to their computational demands, specially on tasks requiring long outputs. However, natural language often contains redundancy, which presents an opportunity for optimization. We have observed that LLMs can generate distilled language-concise outputs that retain essential meaning, when prompted appropriately. We propose a framework for saving computational cost, in which a shorter distilled output from the LLM is reconstructed into a full narrative by a smaller model with lower inference costs. Our experiments show promising results, particularly in general knowledge domains with 20.58% saved tokens on average with tiny decrease in evaluation metrics, hinting that this approach can effectively balance efficiency and accuracy in language processing tasks.
Projection Abstractions in Planning Under the Lenses of Abstractions for MDPs
Dec 03, 2024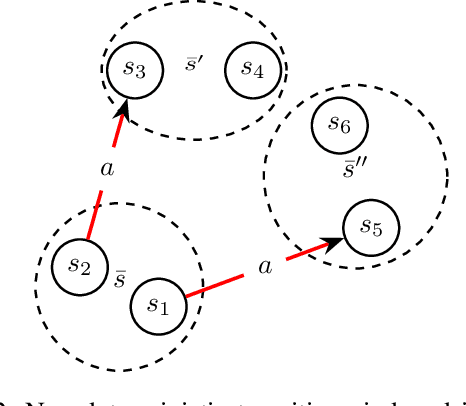
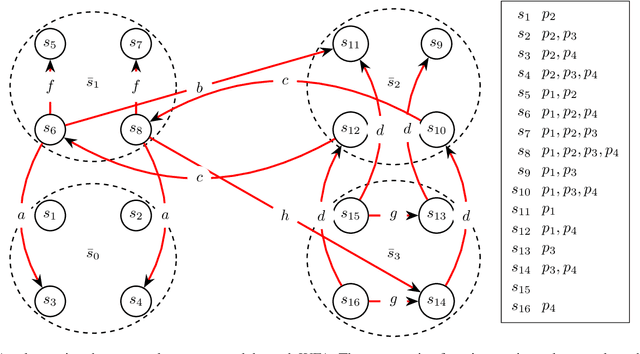
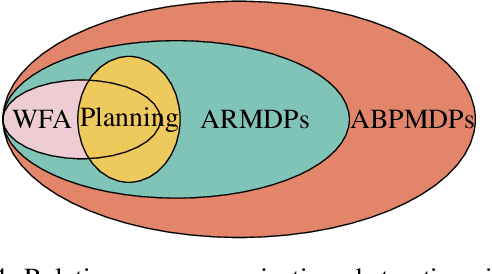
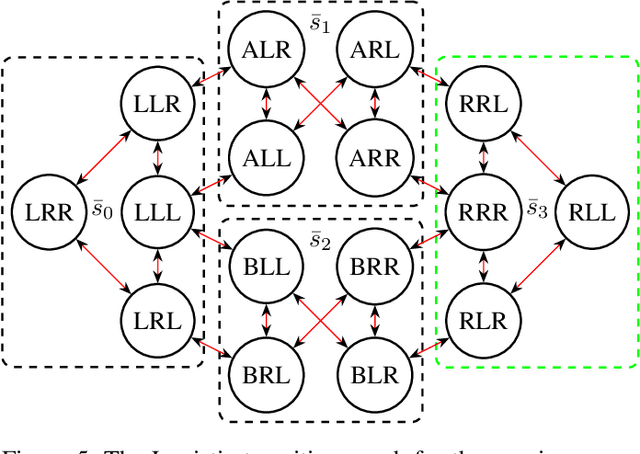
The concept of abstraction has been independently developed both in the context of AI Planning and discounted Markov Decision Processes (MDPs). However, the way abstractions are built and used in the context of Planning and MDPs is different even though lots of commonalities can be highlighted. To this day there is no work trying to relate and unify the two fields on the matter of abstractions unraveling all the different assumptions and their effect on the way they can be used. Therefore, in this paper we aim to do so by looking at projection abstractions in Planning through the lenses of discounted MDPs. Starting from a projection abstraction built according to Classical or Probabilistic Planning techniques, we will show how the same abstraction can be obtained under the abstraction frameworks available for discounted MDPs. Along the way, we will focus on computational as well as representational advantages and disadvantages of both worlds pointing out new research directions that are of interest for both fields.