 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKL Divergence Between Gaussians: A Step-by-Step Derivation for the Variational Autoencoder Objective
Apr 13, 2026Kullback-Leibler (KL) divergence is a fundamental concept in information theory that quantifies the discrepancy between two probability distributions. In the context of Variational Autoencoders (VAEs), it serves as a central regularization term, imposing structure on the latent space and thereby enabling the model to exhibit generative capabilities. In this work, we present a detailed derivation of the closed-form expression for the KL divergence between Gaussian distributions, a case of particular importance in practical VAE implementations. Starting from the general definition for continuous random variables, we derive the expression for the univariate case and extend it to the multivariate setting under the assumption of diagonal covariance. Finally, we discuss the interpretation of each term in the resulting expression and its impact on the training dynamics of the model.
Hypercone Assisted Contour Generation for Out-of-Distribution Detection
Jan 17, 2025Recent advances in the field of out-of-distribution (OOD) detection have placed great emphasis on learning better representations suited to this task. While there are distance-based approaches, distributional awareness has seldom been exploited for better performance. We present HAC$_k$-OOD, a novel OOD detection method that makes no distributional assumption about the data, but automatically adapts to its distribution. Specifically, HAC$_k$-OOD constructs a set of hypercones by maximizing the angular distance to neighbors in a given data-point's vicinity to approximate the contour within which in-distribution (ID) data-points lie. Experimental results show state-of-the-art FPR@95 and AUROC performance on Near-OOD detection and on Far-OOD detection on the challenging CIFAR-100 benchmark without explicitly training for OOD performance.
Veri-Car: Towards Open-world Vehicle Information Retrieval
Nov 11, 2024Many industrial and service sectors require tools to extract vehicle characteristics from images. This is a complex task not only by the variety of noise, and large number of classes, but also by the constant introduction of new vehicle models to the market. In this paper, we present Veri-Car, an information retrieval integrated approach designed to help on this task. It leverages supervised learning techniques to accurately identify the make, type, model, year, color, and license plate of cars. The approach also addresses the challenge of handling open-world problems, where new car models and variations frequently emerge, by employing a sophisticated combination of pre-trained models, and a hierarchical multi-similarity loss. Veri-Car demonstrates robust performance, achieving high precision and accuracy in classifying both seen and unseen data. Additionally, it integrates an ensemble license plate detection, and an OCR model to extract license plate numbers with impressive accuracy.
Computer User Interface Understanding. A New Dataset and a Learning Framework
Mar 15, 2024User Interface (UI) understanding has been an increasingly popular topic over the last few years. So far, there has been a vast focus solely on web and mobile applications. In this paper, we introduce the harder task of computer UI understanding. With the goal of enabling research in this field, we have generated a dataset with a set of videos where a user is performing a sequence of actions and each image shows the desktop contents at that time point. We also present a framework that is composed of a synthetic sample generation pipeline to augment the dataset with relevant characteristics, and a contrastive learning method to classify images in the videos. We take advantage of the natural conditional, tree-like, relationship of the images' characteristics to regularize the learning of the representations by dealing with multiple partial tasks simultaneously. Experimental results show that the proposed framework outperforms previously proposed hierarchical multi-label contrastive losses in fine-grain UI classification.
Private Optimization Without Constraint Violations
Jul 02, 2020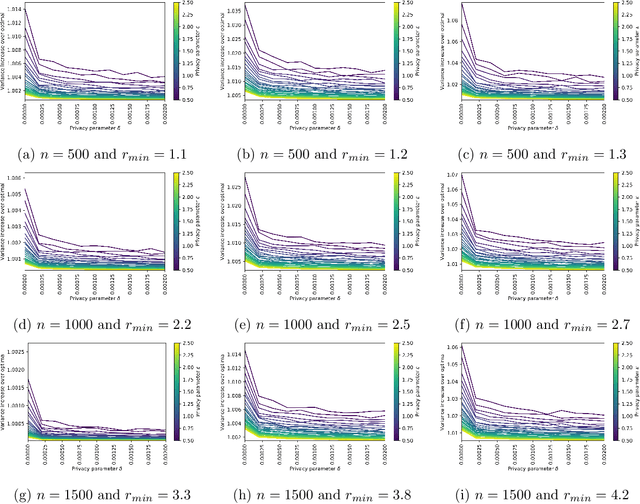
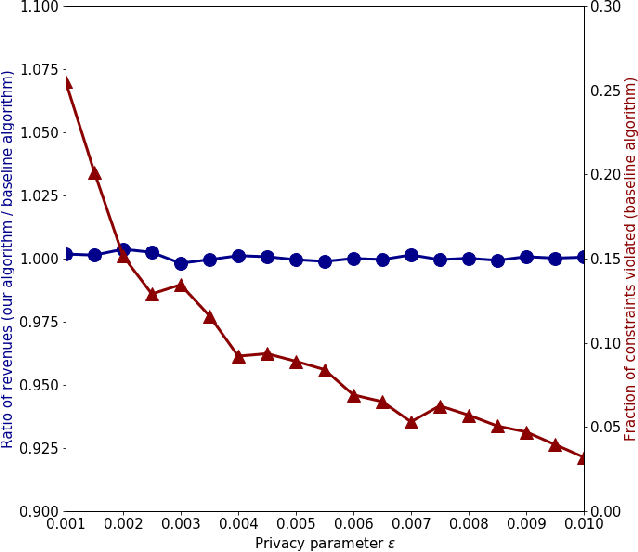
We study the problem of differentially private optimization with linear constraints when the right-hand-side of the constraints depends on private data. This type of problem appears in many applications, especially resource allocation. Previous research provided solutions that retained privacy, but sometimes violated the constraints. In many settings, however, the constraints cannot be violated under any circumstances. To address this hard requirement, we present an algorithm that releases a nearly-optimal solution satisfying the problem's constraints with probability 1. We also prove a lower bound demonstrating that the difference between the objective value of our algorithm's solution and the optimal solution is tight up to logarithmic factors among all differentially private algorithms. We conclude with experiments on real and synthetic datasets demonstrating that our algorithm can achieve nearly optimal performance while preserving privacy.