 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenePlan: Evolving Better Generalized PDDL Plans using Large Language Models
Mar 10, 2026We present GenePlan (GENeralized Evolutionary Planner), a novel framework that leverages large language model (LLM) assisted evolutionary algorithms to generate domain-dependent generalized planners for classical planning tasks described in PDDL. By casting generalized planning as an optimization problem, GenePlan iteratively evolves interpretable Python planners that minimize plan length across diverse problem instances. In empirical evaluation across six existing benchmark domains and two new domains, GenePlan achieved an average SAT score of 0.91, closely matching the performance of the state-of-the-art planners (SAT score 0.93), and significantly outperforming other LLM-based baselines such as chain-of-thought (CoT) prompting (average SAT score 0.64). The generated planners solve new instances rapidly (average 0.49 seconds per task) and at low cost (average $1.82 per domain using GPT-4o).
Semantic Partial Grounding via LLMs
Feb 25, 2026Grounding is a critical step in classical planning, yet it often becomes a computational bottleneck due to the exponential growth in grounded actions and atoms as task size increases. Recent advances in partial grounding have addressed this challenge by incrementally grounding only the most promising operators, guided by predictive models. However, these approaches primarily rely on relational features or learned embeddings and do not leverage the textual and structural cues present in PDDL descriptions. We propose SPG-LLM, which uses LLMs to analyze the domain and problem files to heuristically identify potentially irrelevant objects, actions, and predicates prior to grounding, significantly reducing the size of the grounded task. Across seven hard-to-ground benchmarks, SPG-LLM achieves faster grounding-often by orders of magnitude-while delivering comparable or better plan costs in some domains.
GenPlanX. Generation of Plans and Execution
Jun 12, 2025Classical AI Planning techniques generate sequences of actions for complex tasks. However, they lack the ability to understand planning tasks when provided using natural language. The advent of Large Language Models (LLMs) has introduced novel capabilities in human-computer interaction. In the context of planning tasks, LLMs have shown to be particularly good in interpreting human intents among other uses. This paper introduces GenPlanX that integrates LLMs for natural language-based description of planning tasks, with a classical AI planning engine, alongside an execution and monitoring framework. We demonstrate the efficacy of GenPlanX in assisting users with office-related tasks, highlighting its potential to streamline workflows and enhance productivity through seamless human-AI collaboration.
The Value of Goal Commitment in Planning
Mar 12, 2025
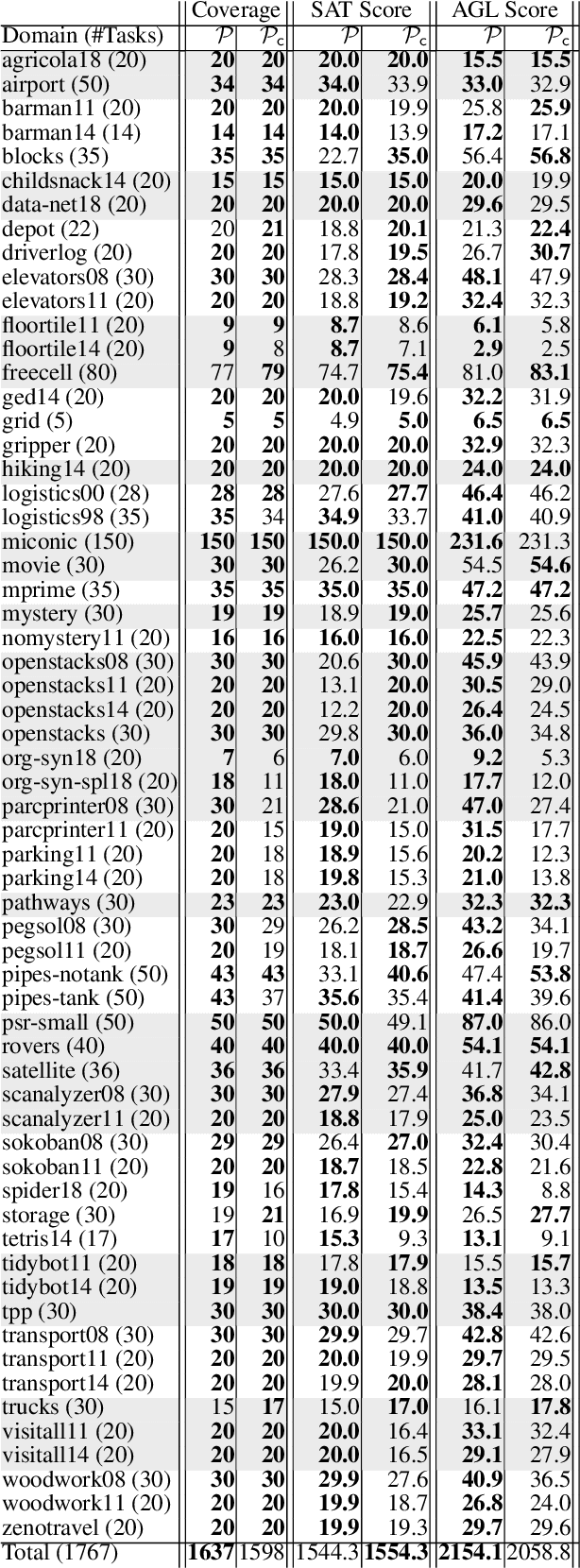
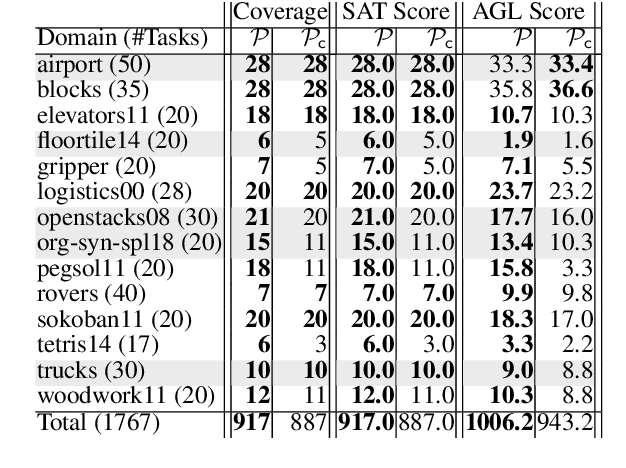
In this paper, we revisit the concept of goal commitment from early planners in the presence of current forward chaining heuristic planners. We present a compilation that extends the original planning task with commit actions that enforce the persistence of specific goals once achieved, thereby committing to them in the search sub-tree. This approach imposes a specific goal achievement order in parts of the search tree, potentially introducing dead-end states. This can reduce search effort if the goal achievement order is correct. Otherwise, the search algorithm can expand nodes in the open list where goals do not persist. Experimental results demonstrate that the reformulated tasks suit state-of-the-art agile planners, enabling them to find better
Projection Abstractions in Planning Under the Lenses of Abstractions for MDPs
Dec 03, 2024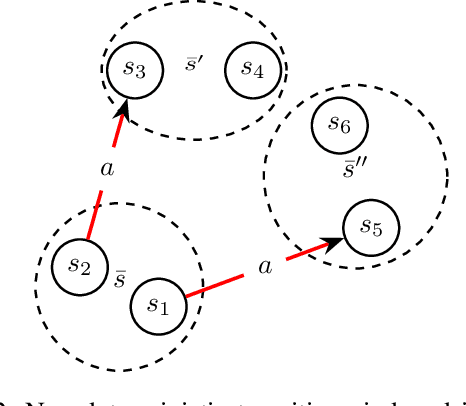
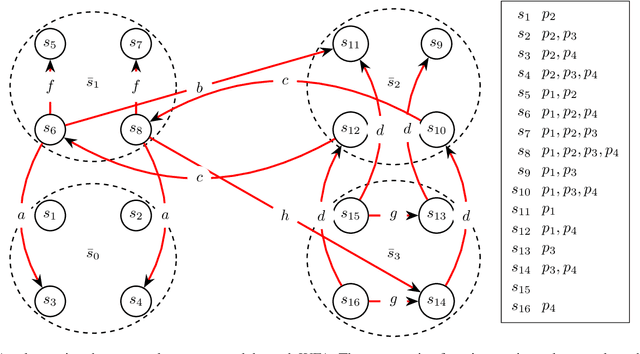
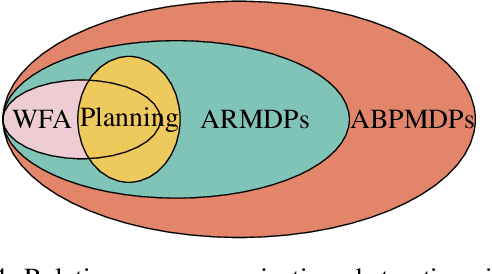
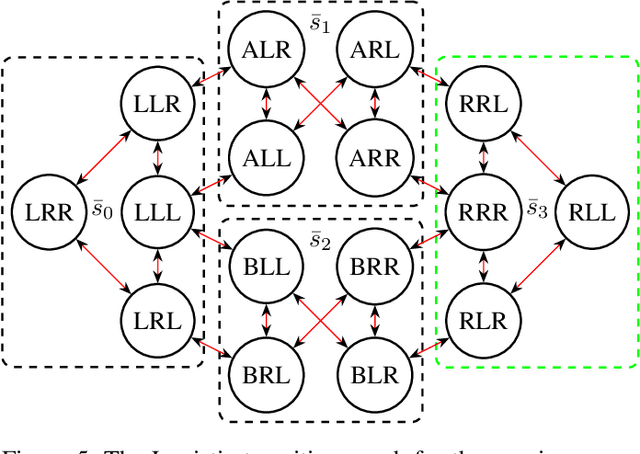
The concept of abstraction has been independently developed both in the context of AI Planning and discounted Markov Decision Processes (MDPs). However, the way abstractions are built and used in the context of Planning and MDPs is different even though lots of commonalities can be highlighted. To this day there is no work trying to relate and unify the two fields on the matter of abstractions unraveling all the different assumptions and their effect on the way they can be used. Therefore, in this paper we aim to do so by looking at projection abstractions in Planning through the lenses of discounted MDPs. Starting from a projection abstraction built according to Classical or Probabilistic Planning techniques, we will show how the same abstraction can be obtained under the abstraction frameworks available for discounted MDPs. Along the way, we will focus on computational as well as representational advantages and disadvantages of both worlds pointing out new research directions that are of interest for both fields.
On Learning Action Costs from Input Plans
Aug 20, 2024Most of the work on learning action models focus on learning the actions' dynamics from input plans. This allows us to specify the valid plans of a planning task. However, very little work focuses on learning action costs, which in turn allows us to rank the different plans. In this paper we introduce a new problem: that of learning the costs of a set of actions such that a set of input plans are optimal under the resulting planning model. To solve this problem we present $LACFIP^k$, an algorithm to learn action's costs from unlabeled input plans. We provide theoretical and empirical results showing how $LACFIP^k$ can successfully solve this task.
TRIP-PAL: Travel Planning with Guarantees by Combining Large Language Models and Automated Planners
Jun 14, 2024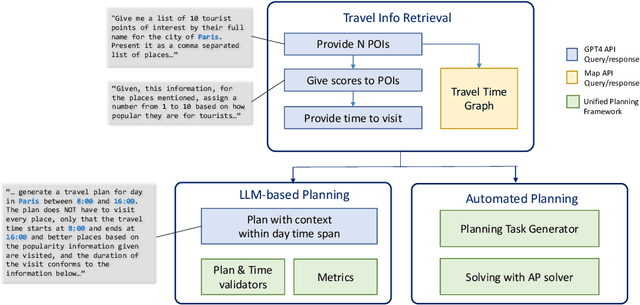

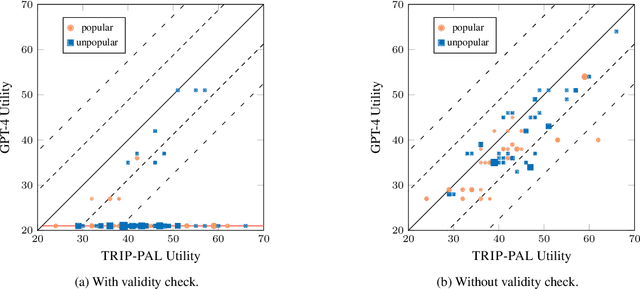
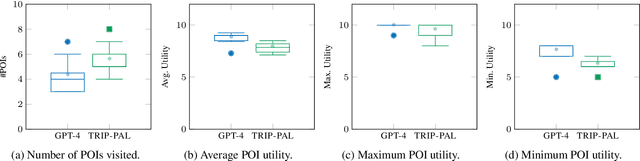
Travel planning is a complex task that involves generating a sequence of actions related to visiting places subject to constraints and maximizing some user satisfaction criteria. Traditional approaches rely on problem formulation in a given formal language, extracting relevant travel information from web sources, and use an adequate problem solver to generate a valid solution. As an alternative, recent Large Language Model (LLM) based approaches directly output plans from user requests using language. Although LLMs possess extensive travel domain knowledge and provide high-level information like points of interest and potential routes, current state-of-the-art models often generate plans that lack coherence, fail to satisfy constraints fully, and do not guarantee the generation of high-quality solutions. We propose TRIP-PAL, a hybrid method that combines the strengths of LLMs and automated planners, where (i) LLMs get and translate travel information and user information into data structures that can be fed into planners; and (ii) automated planners generate travel plans that guarantee constraint satisfaction and optimize for users' utility. Our experiments across various travel scenarios show that TRIP-PAL outperforms an LLM when generating travel plans.
On the Sample Efficiency of Abstractions and Potential-Based Reward Shaping in Reinforcement Learning
Apr 11, 2024
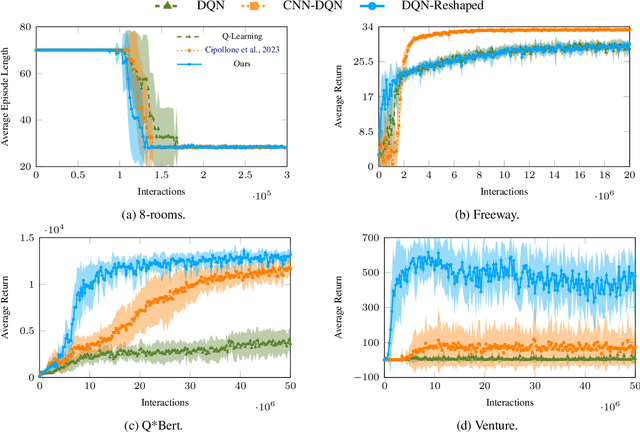
The use of Potential Based Reward Shaping (PBRS) has shown great promise in the ongoing research effort to tackle sample inefficiency in Reinforcement Learning (RL). However, the choice of the potential function is critical for this technique to be effective. Additionally, RL techniques are usually constrained to use a finite horizon for computational limitations. This introduces a bias when using PBRS, thus adding an additional layer of complexity. In this paper, we leverage abstractions to automatically produce a "good" potential function. We analyse the bias induced by finite horizons in the context of PBRS producing novel insights. Finally, to asses sample efficiency and performance impact, we evaluate our approach on four environments including a goal-oriented navigation task and three Arcade Learning Environments (ALE) games demonstrating that we can reach the same level of performance as CNN-based solutions with a simple fully-connected network.
On Computing Plans with Uniform Action Costs
Feb 15, 2024In many real-world planning applications, agents might be interested in finding plans whose actions have costs that are as uniform as possible. Such plans provide agents with a sense of stability and predictability, which are key features when humans are the agents executing plans suggested by planning tools. This paper adapts three uniformity metrics to automated planning, and introduce planning-based compilations that allow to lexicographically optimize sum of action costs and action costs uniformity. Experimental results both in well-known and novel planning benchmarks show that the reformulated tasks can be effectively solved in practice to generate uniform plans.
Generalising Planning Environment Redesign
Feb 14, 2024
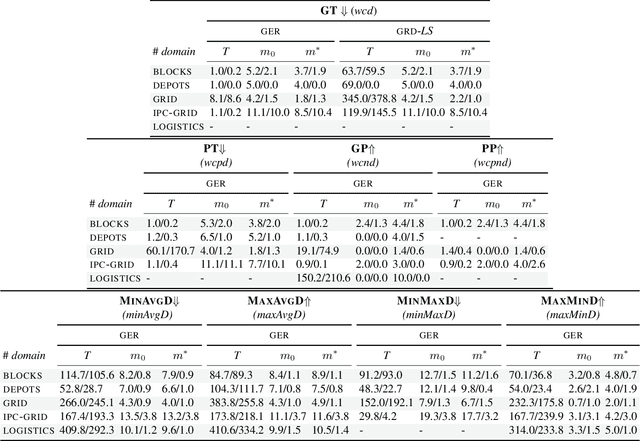

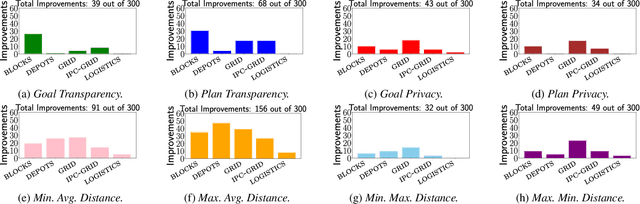
In Environment Design, one interested party seeks to affect another agent's decisions by applying changes to the environment. Most research on planning environment (re)design assumes the interested party's objective is to facilitate the recognition of goals and plans, and search over the space of environment modifications to find the minimal set of changes that simplify those tasks and optimise a particular metric. This search space is usually intractable, so existing approaches devise metric-dependent pruning techniques for performing search more efficiently. This results in approaches that are not able to generalise across different objectives and/or metrics. In this paper, we argue that the interested party could have objectives and metrics that are not necessarily related to recognising agents' goals or plans. Thus, to generalise the task of Planning Environment Redesign, we develop a general environment redesign approach that is metric-agnostic and leverages recent research on top-quality planning to efficiently redesign planning environments according to any interested party's objective and metric. Experiments over a set of environment redesign benchmarks show that our general approach outperforms existing approaches when using well-known metrics, such as facilitating the recognition of goals, as well as its effectiveness when solving environment redesign tasks that optimise a novel set of different metrics.