 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenPlanX. Generation of Plans and Execution
Jun 12, 2025Classical AI Planning techniques generate sequences of actions for complex tasks. However, they lack the ability to understand planning tasks when provided using natural language. The advent of Large Language Models (LLMs) has introduced novel capabilities in human-computer interaction. In the context of planning tasks, LLMs have shown to be particularly good in interpreting human intents among other uses. This paper introduces GenPlanX that integrates LLMs for natural language-based description of planning tasks, with a classical AI planning engine, alongside an execution and monitoring framework. We demonstrate the efficacy of GenPlanX in assisting users with office-related tasks, highlighting its potential to streamline workflows and enhance productivity through seamless human-AI collaboration.
On the Temporal Question-Answering Capabilities of Large Language Models Over Anonymized Data
Apr 10, 2025The applicability of Large Language Models (LLMs) in temporal reasoning tasks over data that is not present during training is still a field that remains to be explored. In this paper we work on this topic, focusing on structured and semi-structured anonymized data. We not only develop a direct LLM pipeline, but also compare various methodologies and conduct an in-depth analysis. We identified and examined seventeen common temporal reasoning tasks in natural language, focusing on their algorithmic components. To assess LLM performance, we created the \textit{Reasoning and Answering Temporal Ability} dataset (RATA), featuring semi-structured anonymized data to ensure reliance on reasoning rather than on prior knowledge. We compared several methodologies, involving SoTA techniques such as Tree-of-Thought, self-reflexion and code execution, tuned specifically for this scenario. Our results suggest that achieving scalable and reliable solutions requires more than just standalone LLMs, highlighting the need for integrated approaches.
TRIM: Token Reduction and Inference Modeling for Cost-Effective Language Generation
Dec 10, 2024



The inference cost of Large Language Models (LLMs) is a significant challenge due to their computational demands, specially on tasks requiring long outputs. However, natural language often contains redundancy, which presents an opportunity for optimization. We have observed that LLMs can generate distilled language-concise outputs that retain essential meaning, when prompted appropriately. We propose a framework for saving computational cost, in which a shorter distilled output from the LLM is reconstructed into a full narrative by a smaller model with lower inference costs. Our experiments show promising results, particularly in general knowledge domains with 20.58% saved tokens on average with tiny decrease in evaluation metrics, hinting that this approach can effectively balance efficiency and accuracy in language processing tasks.
Planning for the Efficient Updating of Mutual Fund Portfolios
Nov 27, 2023


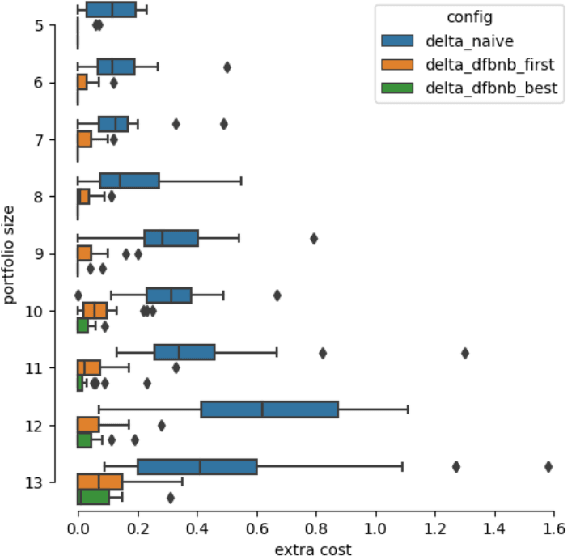
Once there is a decision of rebalancing or updating a portfolio of funds, the process of changing the current portfolio to the target one, involves a set of transactions that are susceptible of being optimized. This is particularly relevant when managers have to handle the implications of different types of instruments. In this work we present linear programming and heuristic search approaches that produce plans for executing the update. The evaluation of our proposals shows cost improvements over the compared based strategy. The models can be easily extended to other realistic scenarios in which a holistic portfolio management is required