 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActing and Planning with Hierarchical Operational Models on a Mobile Robot: A Study with RAE+UPOM
Jul 15, 2025



Robotic task execution faces challenges due to the inconsistency between symbolic planner models and the rich control structures actually running on the robot. In this paper, we present the first physical deployment of an integrated actor-planner system that shares hierarchical operational models for both acting and planning, interleaving the Reactive Acting Engine (RAE) with an anytime UCT-like Monte Carlo planner (UPOM). We implement RAE+UPOM on a mobile manipulator in a real-world deployment for an object collection task. Our experiments demonstrate robust task execution under action failures and sensor noise, and provide empirical insights into the interleaved acting-and-planning decision making process.
Capacity Planning and Scheduling for Jobs with Uncertainty in Resource Usage and Duration
Jul 01, 2025Organizations around the world schedule jobs (programs) regularly to perform various tasks dictated by their end users. With the major movement towards using a cloud computing infrastructure, our organization follows a hybrid approach with both cloud and on-prem servers. The objective of this work is to perform capacity planning, i.e., estimate resource requirements, and job scheduling for on-prem grid computing environments. A key contribution of our approach is handling uncertainty in both resource usage and duration of the jobs, a critical aspect in the finance industry where stochastic market conditions significantly influence job characteristics. For capacity planning and scheduling, we simultaneously balance two conflicting objectives: (a) minimize resource usage, and (b) provide high quality-of-service to the end users by completing jobs by their requested deadlines. We propose approximate approaches using deterministic estimators and pair sampling-based constraint programming. Our best approach (pair sampling-based) achieves much lower peak resource usage compared to manual scheduling without compromising on the quality-of-service.
* Please cite as: Sunandita Patra, Mehtab Pathan, Mahmoud Mahfouz, Parisa Zehtabi, Wided Ouaja, Daniele Magazzeni, and Manuela Veloso. "Capacity planning and scheduling for jobs with uncertainty in resource usage and duration." The Journal of Supercomputing 80, no. 15 (2024): 22428-22461
GenPlanX. Generation of Plans and Execution
Jun 12, 2025Classical AI Planning techniques generate sequences of actions for complex tasks. However, they lack the ability to understand planning tasks when provided using natural language. The advent of Large Language Models (LLMs) has introduced novel capabilities in human-computer interaction. In the context of planning tasks, LLMs have shown to be particularly good in interpreting human intents among other uses. This paper introduces GenPlanX that integrates LLMs for natural language-based description of planning tasks, with a classical AI planning engine, alongside an execution and monitoring framework. We demonstrate the efficacy of GenPlanX in assisting users with office-related tasks, highlighting its potential to streamline workflows and enhance productivity through seamless human-AI collaboration.
QBD-RankedDataGen: Generating Custom Ranked Datasets for Improving Query-By-Document Search Using LLM-Reranking with Reduced Human Effort
May 07, 2025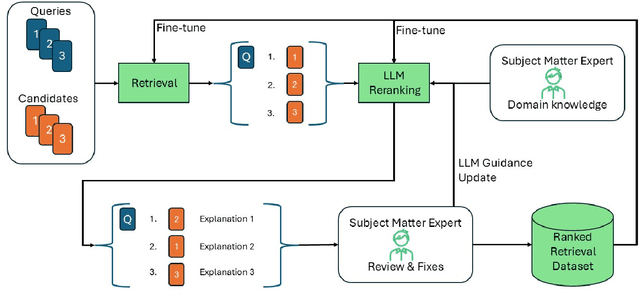
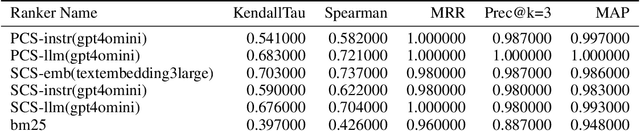
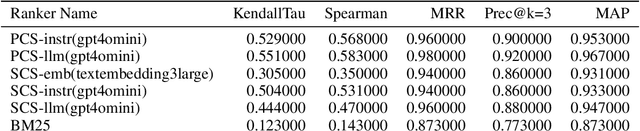
The Query-By-Document (QBD) problem is an information retrieval problem where the query is a document, and the retrieved candidates are documents that match the query document, often in a domain or query specific manner. This can be crucial for tasks such as patent matching, legal or compliance case retrieval, and academic literature review. Existing retrieval methods, including keyword search and document embeddings, can be optimized with domain-specific datasets to improve QBD search performance. However, creating these domain-specific datasets is often costly and time-consuming. Our work introduces a process to generate custom QBD-search datasets and compares a set of methods to use in this problem, which we refer to as QBD-RankedDatagen. We provide a comparative analysis of our proposed methods in terms of cost, speed, and the human interface with the domain experts. The methods we compare leverage Large Language Models (LLMs) which can incorporate domain expert input to produce document scores and rankings, as well as explanations for human review. The process and methods for it that we present can significantly reduce human effort in dataset creation for custom domains while still obtaining sufficient expert knowledge for tuning retrieval models. We evaluate our methods on QBD datasets from the Text Retrieval Conference (TREC) and finetune the parameters of the BM25 model -- which is used in many industrial-strength search engines like OpenSearch -- using the generated data.
On Creating a Causally Grounded Usable Rating Method for Assessing the Robustness of Foundation Models Supporting Time Series
Feb 17, 2025Foundation Models (FMs) have improved time series forecasting in various sectors, such as finance, but their vulnerability to input disturbances can hinder their adoption by stakeholders, such as investors and analysts. To address this, we propose a causally grounded rating framework to study the robustness of Foundational Models for Time Series (FMTS) with respect to input perturbations. We evaluate our approach to the stock price prediction problem, a well-studied problem with easily accessible public data, evaluating six state-of-the-art (some multi-modal) FMTS across six prominent stocks spanning three industries. The ratings proposed by our framework effectively assess the robustness of FMTS and also offer actionable insights for model selection and deployment. Within the scope of our study, we find that (1) multi-modal FMTS exhibit better robustness and accuracy compared to their uni-modal versions and, (2) FMTS pre-trained on time series forecasting task exhibit better robustness and forecasting accuracy compared to general-purpose FMTS pre-trained across diverse settings. Further, to validate our framework's usability, we conduct a user study showcasing FMTS prediction errors along with our computed ratings. The study confirmed that our ratings reduced the difficulty for users in comparing the robustness of different systems.
Rating Multi-Modal Time-Series Forecasting Models (MM-TSFM) for Robustness Through a Causal Lens
Jun 12, 2024



AI systems are notorious for their fragility; minor input changes can potentially cause major output swings. When such systems are deployed in critical areas like finance, the consequences of their uncertain behavior could be severe. In this paper, we focus on multi-modal time-series forecasting, where imprecision due to noisy or incorrect data can lead to erroneous predictions, impacting stakeholders such as analysts, investors, and traders. Recently, it has been shown that beyond numeric data, graphical transformations can be used with advanced visual models to achieve better performance. In this context, we introduce a rating methodology to assess the robustness of Multi-Modal Time-Series Forecasting Models (MM-TSFM) through causal analysis, which helps us understand and quantify the isolated impact of various attributes on the forecasting accuracy of MM-TSFM. We apply our novel rating method on a variety of numeric and multi-modal forecasting models in a large experimental setup (six input settings of control and perturbations, ten data distributions, time series from six leading stocks in three industries over a year of data, and five time-series forecasters) to draw insights on robust forecasting models and the context of their strengths. Within the scope of our study, our main result is that multi-modal (numeric + visual) forecasting, which was found to be more accurate than numeric forecasting in previous studies, can also be more robust in diverse settings. Our work will help different stakeholders of time-series forecasting understand the models` behaviors along trust (robustness) and accuracy dimensions to select an appropriate model for forecasting using our rating method, leading to improved decision-making.
SafeAR: Towards Safer Algorithmic Recourse by Risk-Aware Policies
Aug 23, 2023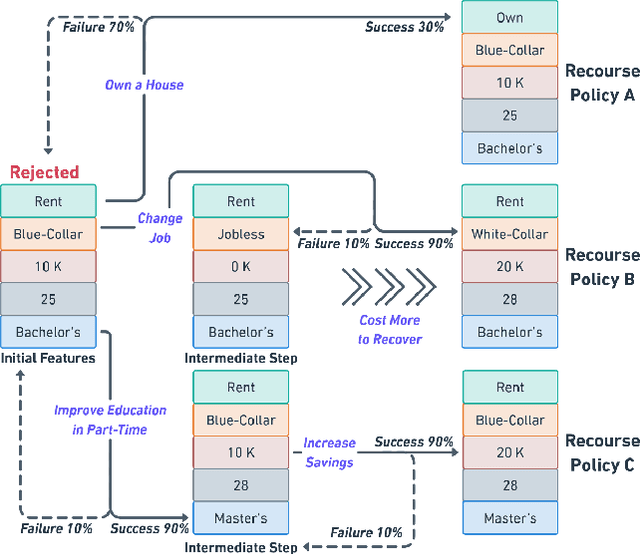
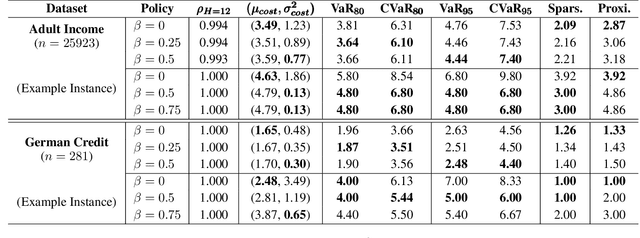
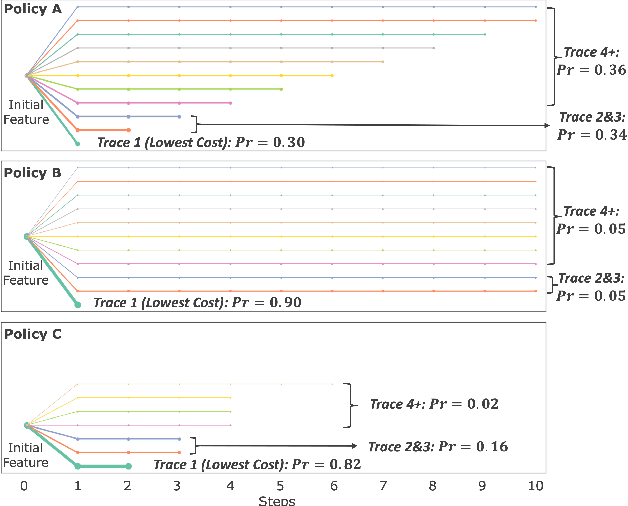

With the growing use of machine learning (ML) models in critical domains such as finance and healthcare, the need to offer recourse for those adversely affected by the decisions of ML models has become more important; individuals ought to be provided with recommendations on actions to take for improving their situation and thus receive a favorable decision. Prior work on sequential algorithmic recourse -- which recommends a series of changes -- focuses on action feasibility and uses the proximity of feature changes to determine action costs. However, the uncertainties of feature changes and the risk of higher than average costs in recourse have not been considered. It is undesirable if a recourse could (with some probability) result in a worse situation from which recovery requires an extremely high cost. It is essential to incorporate risks when computing and evaluating recourse. We call the recourse computed with such risk considerations as Safer Algorithmic Recourse (SafeAR). The objective is to empower people to choose a recourse based on their risk tolerance. In this work, we discuss and show how existing recourse desiderata can fail to capture the risk of higher costs. We present a method to compute recourse policies that consider variability in cost and connect algorithmic recourse literature with risk-sensitive reinforcement learning. We also adopt measures ``Value at Risk'' and ``Conditional Value at Risk'' from the financial literature to summarize risk concisely. We apply our method to two real-world datasets and compare policies with different levels of risk-aversion using risk measures and recourse desiderata (sparsity and proximity).
Deliberative Acting, Online Planning and Learning with Hierarchical Operational Models
Oct 02, 2020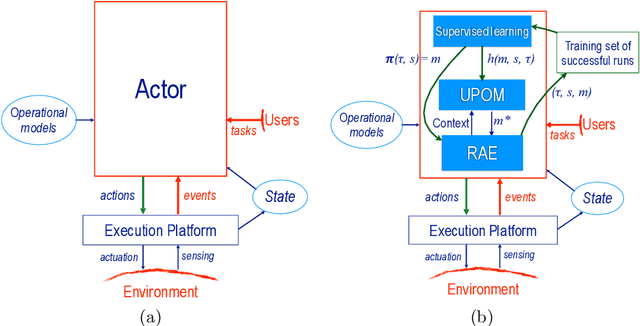
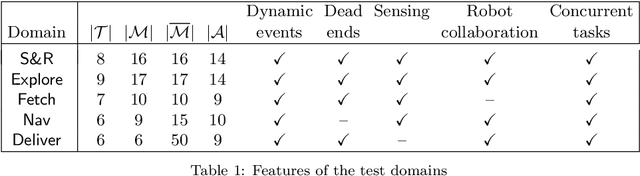

The most common representation formalisms for automated planning are descriptive models that abstractly describe what the actions do and are tailored for effciently computing the next state(s) in a state-transition system. However, real-world acting requires operational models that describe how to do things, with rich control structures for closed-loop online decision-making in a dynamic environment. To use a different action model for planning than the one used for acting causes problems with combining acting and planning, in particular for the development and consistency verification of the different models. As an alternative, we define and implement an integrated acting-and-planning system in which both planning and acting use the same operational models, which are written in a general-purpose hierarchical task-oriented language offering rich control structures. The acting component, called Reactive Acting Engine (RAE), is inspired by the well-known PRS system, except that instead of being purely reactive, it can get advice from the planner. Our planner uses a UCT-like Monte Carlo Tree Search procedure, called UPOM (UCT Procedure for Operational Models), whose rollouts are simulations of the actor's operational models. We also present learning strategies for use with RAE and UPOM that acquire, from online acting experiences and/or simulated planning results, a mapping from decision contexts to method instances as well as a heuristic function to guide UPOM. Our experimental results show that UPOM and our learning strategies significantly improve the acting efficiency and robustness of RAE. We discuss the asymptotic convergence of UPOM by mapping its search space to an MDP.
Integrating Acting, Planning and Learning in Hierarchical Operational Models
Mar 09, 2020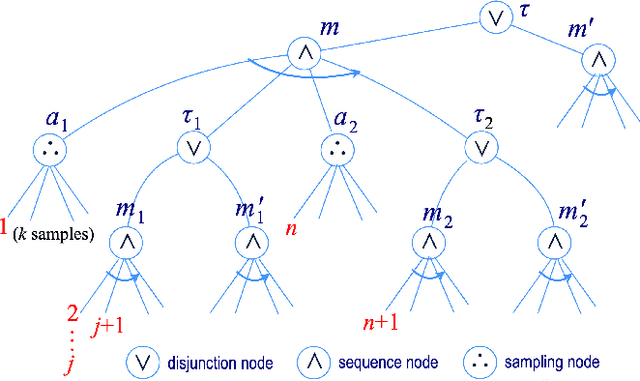
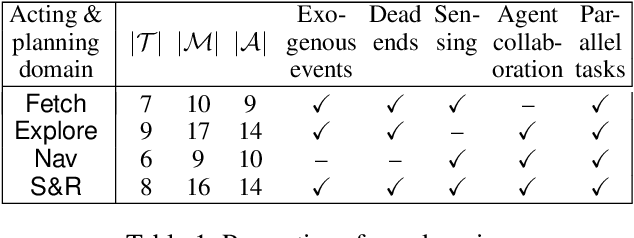
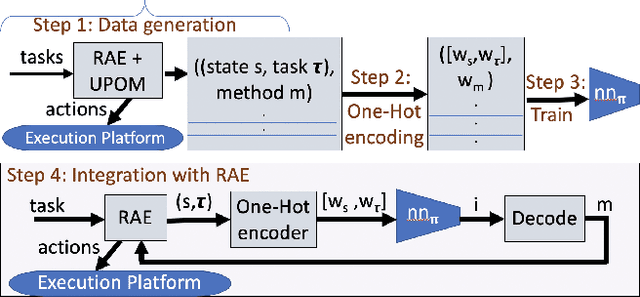

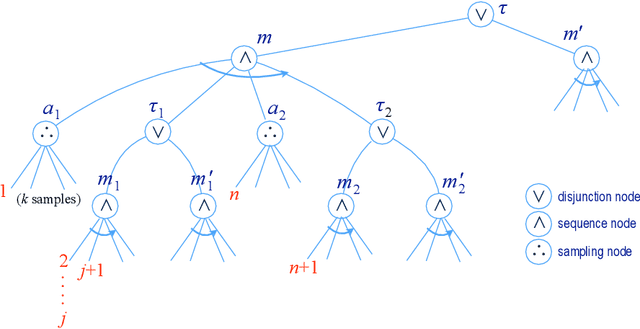
We present new planning and learning algorithms for RAE, the Refinement Acting Engine. RAE uses hierarchical operational models to perform tasks in dynamically changing environments. Our planning procedure, UPOM, does a UCT-like search in the space of operational models in order to find a near-optimal method to use for the task and context at hand. Our learning strategies acquire, from online acting experiences and/or simulated planning results, a mapping from decision contexts to method instances as well as a heuristic function to guide UPOM. Our experimental results show that UPOM and our learning strategies significantly improve RAE's performance in four test domains using two different metrics: efficiency and success ratio.