 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActing and Planning with Hierarchical Operational Models on a Mobile Robot: A Study with RAE+UPOM
Jul 15, 2025



Robotic task execution faces challenges due to the inconsistency between symbolic planner models and the rich control structures actually running on the robot. In this paper, we present the first physical deployment of an integrated actor-planner system that shares hierarchical operational models for both acting and planning, interleaving the Reactive Acting Engine (RAE) with an anytime UCT-like Monte Carlo planner (UPOM). We implement RAE+UPOM on a mobile manipulator in a real-world deployment for an object collection task. Our experiments demonstrate robust task execution under action failures and sensor noise, and provide empirical insights into the interleaved acting-and-planning decision making process.
HTN Plan Repair Algorithms Compared: Strengths and Weaknesses of Different Methods
Apr 22, 2025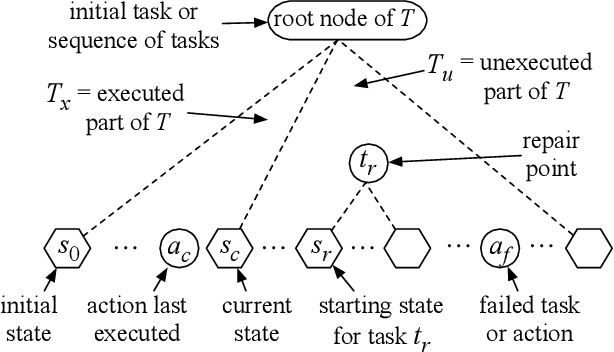

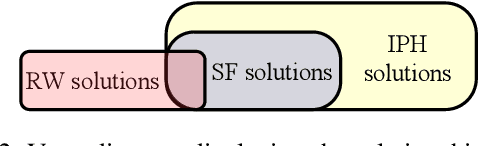

This paper provides theoretical and empirical comparisons of three recent hierarchical plan repair algorithms: SHOPFixer, IPyHOPPER, and Rewrite. Our theoretical results show that the three algorithms correspond to three different definitions of the plan repair problem, leading to differences in the algorithms' search spaces, the repair problems they can solve, and the kinds of repairs they can make. Understanding these distinctions is important when choosing a repair method for any given application. Building on the theoretical results, we evaluate the algorithms empirically in a series of benchmark planning problems. Our empirical results provide more detailed insight into the runtime repair performance of these systems and the coverage of the repair problems solved, based on algorithmic properties such as replanning, chronological backtracking, and backjumping over plan trees.
Automating Curriculum Learning for Reinforcement Learning using a Skill-Based Bayesian Network
Feb 21, 2025



A major challenge for reinforcement learning is automatically generating curricula to reduce training time or improve performance in some target task. We introduce SEBNs (Skill-Environment Bayesian Networks) which model a probabilistic relationship between a set of skills, a set of goals that relate to the reward structure, and a set of environment features to predict policy performance on (possibly unseen) tasks. We develop an algorithm that uses the inferred estimates of agent success from SEBN to weigh the possible next tasks by expected improvement. We evaluate the benefit of the resulting curriculum on three environments: a discrete gridworld, continuous control, and simulated robotics. The results show that curricula constructed using SEBN frequently outperform other baselines.
Automatically Learning HTN Methods from Landmarks
Apr 09, 2024Hierarchical Task Network (HTN) planning usually requires a domain engineer to provide manual input about how to decompose a planning problem. Even HTN-MAKER, a well-known method-learning algorithm, requires a domain engineer to annotate the tasks with information about what to learn. We introduce CURRICULAMA, an HTN method learning algorithm that completely automates the learning process. It uses landmark analysis to compose annotated tasks and leverages curriculum learning to order the learning of methods from simpler to more complex. This eliminates the need for manual input, resolving a core issue with HTN-MAKER. We prove CURRICULAMA's soundness, and show experimentally that it has a substantially similar convergence rate in learning a complete set of methods to HTN-MAKER.
Deliberative Acting, Online Planning and Learning with Hierarchical Operational Models
Oct 02, 2020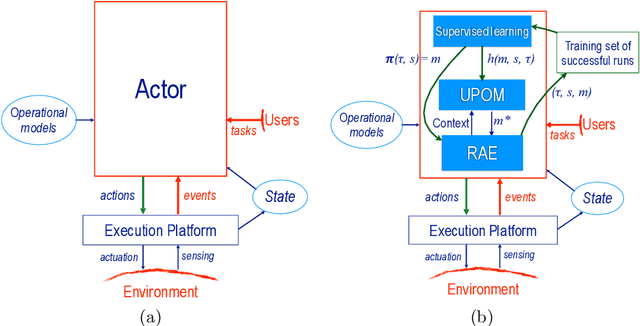
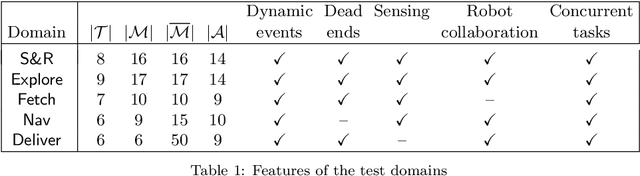

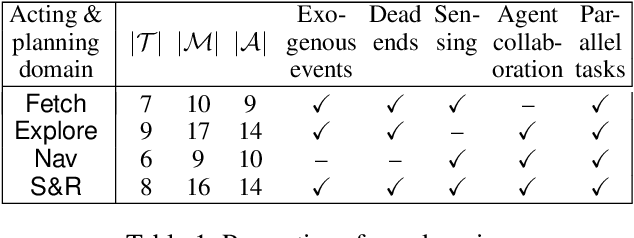
The most common representation formalisms for automated planning are descriptive models that abstractly describe what the actions do and are tailored for effciently computing the next state(s) in a state-transition system. However, real-world acting requires operational models that describe how to do things, with rich control structures for closed-loop online decision-making in a dynamic environment. To use a different action model for planning than the one used for acting causes problems with combining acting and planning, in particular for the development and consistency verification of the different models. As an alternative, we define and implement an integrated acting-and-planning system in which both planning and acting use the same operational models, which are written in a general-purpose hierarchical task-oriented language offering rich control structures. The acting component, called Reactive Acting Engine (RAE), is inspired by the well-known PRS system, except that instead of being purely reactive, it can get advice from the planner. Our planner uses a UCT-like Monte Carlo Tree Search procedure, called UPOM (UCT Procedure for Operational Models), whose rollouts are simulations of the actor's operational models. We also present learning strategies for use with RAE and UPOM that acquire, from online acting experiences and/or simulated planning results, a mapping from decision contexts to method instances as well as a heuristic function to guide UPOM. Our experimental results show that UPOM and our learning strategies significantly improve the acting efficiency and robustness of RAE. We discuss the asymptotic convergence of UPOM by mapping its search space to an MDP.
Integrating Acting, Planning and Learning in Hierarchical Operational Models
Mar 09, 2020
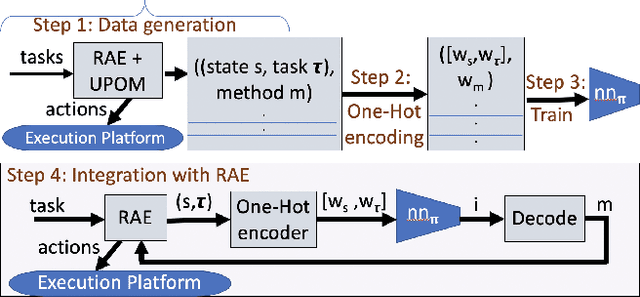

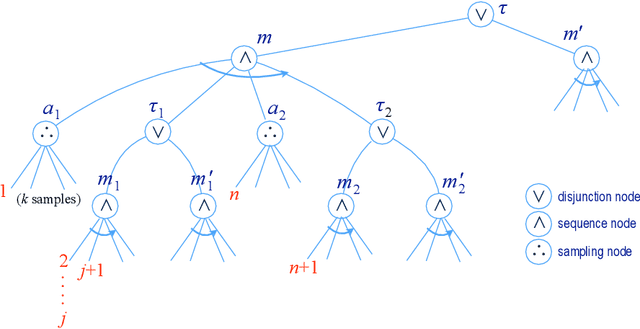
We present new planning and learning algorithms for RAE, the Refinement Acting Engine. RAE uses hierarchical operational models to perform tasks in dynamically changing environments. Our planning procedure, UPOM, does a UCT-like search in the space of operational models in order to find a near-optimal method to use for the task and context at hand. Our learning strategies acquire, from online acting experiences and/or simulated planning results, a mapping from decision contexts to method instances as well as a heuristic function to guide UPOM. Our experimental results show that UPOM and our learning strategies significantly improve RAE's performance in four test domains using two different metrics: efficiency and success ratio.
An Evaluation of Two Alternatives to Minimax
Mar 27, 2013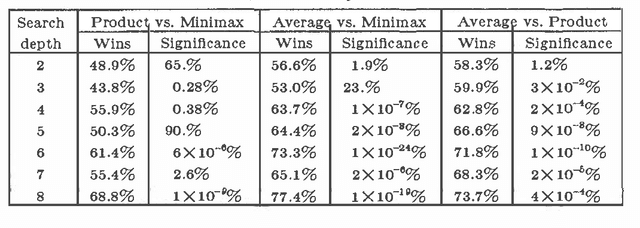
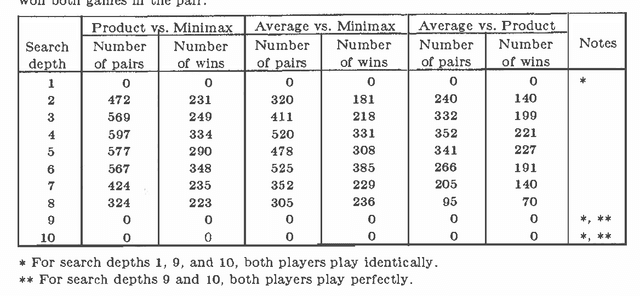
In the field of Artificial Intelligence, traditional approaches to choosing moves in games involve the we of the minimax algorithm. However, recent research results indicate that minimizing may not always be the best approach. In this paper we summarize the results of some measurements on several model games with several different evaluation functions. These measurements, which are presented in detail in [NPT], show that there are some new algorithms that can make significantly better use of evaluation function values than the minimax algorithm does.
Predicting The Performance of Minimax and Product in Game-Tree
Mar 27, 2013

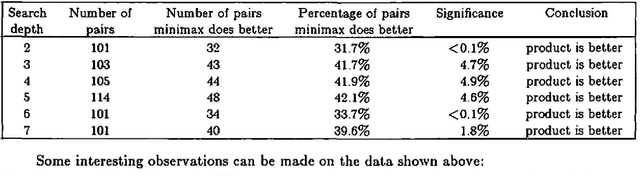
The discovery that the minimax decision rule performs poorly in some games has sparked interest in possible alternatives to minimax. Until recently, the only games in which minimax was known to perform poorly were games which were mainly of theoretical interest. However, this paper reports results showing poor performance of minimax in a more common game called kalah. For the kalah games tested, a non-minimax decision rule called the product rule performs significantly better than minimax. This paper also discusses a possible way to predict whether or not minimax will perform well in a game when compared to product. A parameter called the rate of heuristic flaw (rhf) has been found to correlate positively with the. performance of product against minimax. Both analytical and experimental results are given that appear to support the predictive power of rhf.