 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActing and Planning with Hierarchical Operational Models on a Mobile Robot: A Study with RAE+UPOM
Jul 15, 2025



Robotic task execution faces challenges due to the inconsistency between symbolic planner models and the rich control structures actually running on the robot. In this paper, we present the first physical deployment of an integrated actor-planner system that shares hierarchical operational models for both acting and planning, interleaving the Reactive Acting Engine (RAE) with an anytime UCT-like Monte Carlo planner (UPOM). We implement RAE+UPOM on a mobile manipulator in a real-world deployment for an object collection task. Our experiments demonstrate robust task execution under action failures and sensor noise, and provide empirical insights into the interleaved acting-and-planning decision making process.
DIMA: DIffusing Motion Artifacts for unsupervised correction in brain MRI images
Apr 09, 2025



Motion artifacts remain a significant challenge in Magnetic Resonance Imaging (MRI), compromising diagnostic quality and potentially leading to misdiagnosis or repeated scans. Existing deep learning approaches for motion artifact correction typically require paired motion-free and motion-affected images for training, which are rarely available in clinical settings. To overcome this requirement, we present DIMA (DIffusing Motion Artifacts), a novel framework that leverages diffusion models to enable unsupervised motion artifact correction in brain MRI. Our two-phase approach first trains a diffusion model on unpaired motion-affected images to learn the distribution of motion artifacts. This model then generates realistic motion artifacts on clean images, creating paired datasets suitable for supervised training of correction networks. Unlike existing methods, DIMA operates without requiring k-space manipulation or detailed knowledge of MRI sequence parameters, making it adaptable across different scanning protocols and hardware. Comprehensive evaluations across multiple datasets and anatomical planes demonstrate that our method achieves comparable performance to state-of-the-art supervised approaches while offering superior generalizability to real clinical data. DIMA represents a significant advancement in making motion artifact correction more accessible for routine clinical use, potentially reducing the need for repeat scans and improving diagnostic accuracy.
Planning for Learning Object Properties
Jan 15, 2023

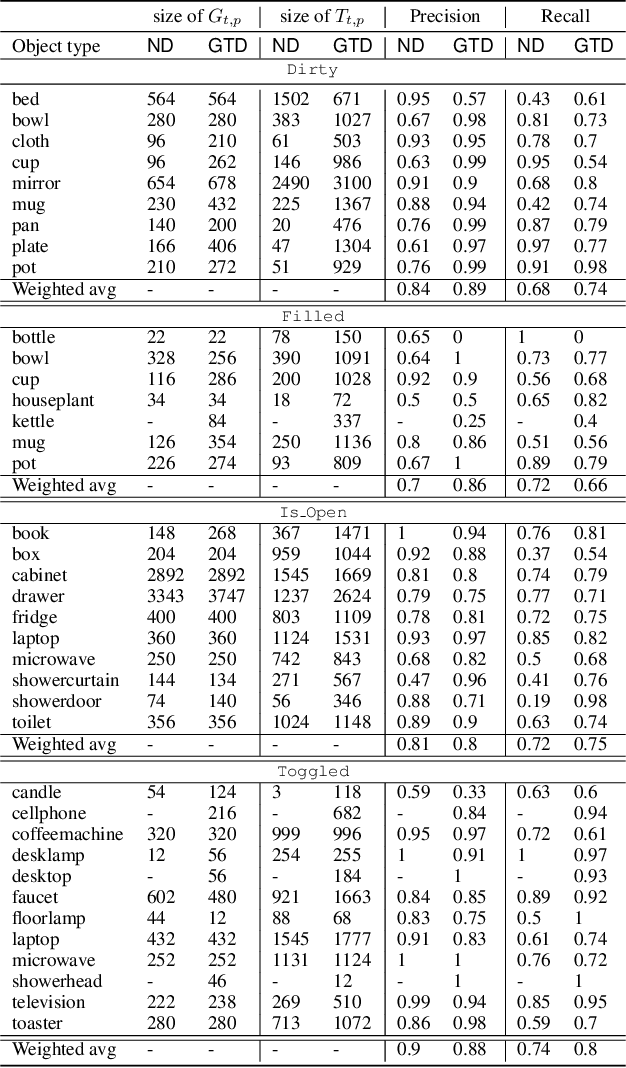
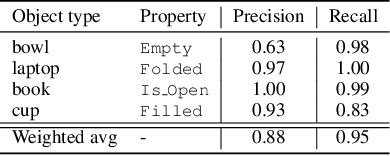
Autonomous agents embedded in a physical environment need the ability to recognize objects and their properties from sensory data. Such a perceptual ability is often implemented by supervised machine learning models, which are pre-trained using a set of labelled data. In real-world, open-ended deployments, however, it is unrealistic to assume to have a pre-trained model for all possible environments. Therefore, agents need to dynamically learn/adapt/extend their perceptual abilities online, in an autonomous way, by exploring and interacting with the environment where they operate. This paper describes a way to do so, by exploiting symbolic planning. Specifically, we formalize the problem of automatically training a neural network to recognize object properties as a symbolic planning problem (using PDDL). We use planning techniques to produce a strategy for automating the training dataset creation and the learning process. Finally, we provide an experimental evaluation in both a simulated and a real environment, which shows that the proposed approach is able to successfully learn how to recognize new object properties.
Online Learning of Reusable Abstract Models for Object Goal Navigation
Mar 04, 2022


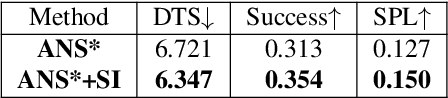
In this paper, we present a novel approach to incrementally learn an Abstract Model of an unknown environment, and show how an agent can reuse the learned model for tackling the Object Goal Navigation task. The Abstract Model is a finite state machine in which each state is an abstraction of a state of the environment, as perceived by the agent in a certain position and orientation. The perceptions are high-dimensional sensory data (e.g., RGB-D images), and the abstraction is reached by exploiting image segmentation and the Taskonomy model bank. The learning of the Abstract Model is accomplished by executing actions, observing the reached state, and updating the Abstract Model with the acquired information. The learned models are memorized by the agent, and they are reused whenever it recognizes to be in an environment that corresponds to the stored model. We investigate the effectiveness of the proposed approach for the Object Goal Navigation task, relying on public benchmarks. Our results show that the reuse of learned Abstract Models can boost performance on Object Goal Navigation.
On some Foundational Aspects of Human-Centered Artificial Intelligence
Dec 29, 2021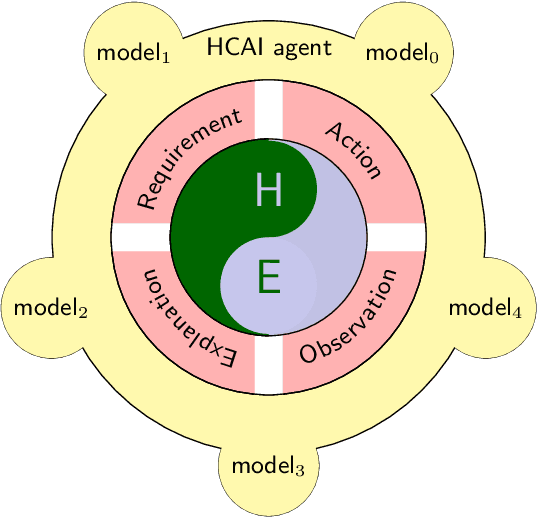
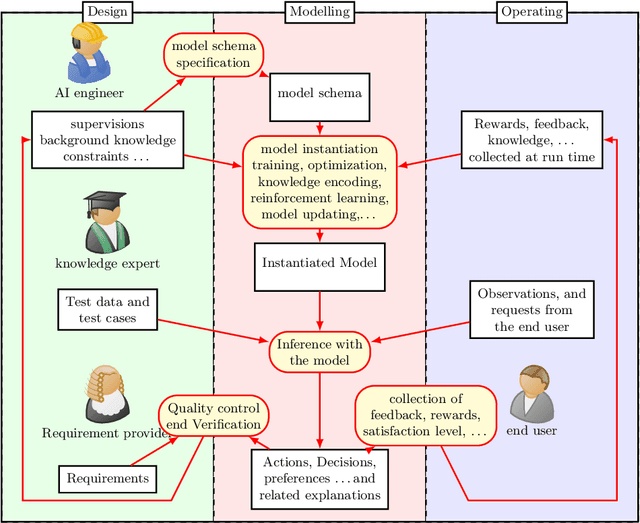
The burgeoning of AI has prompted recommendations that AI techniques should be "human-centered". However, there is no clear definition of what is meant by Human Centered Artificial Intelligence, or for short, HCAI. This paper aims to improve this situation by addressing some foundational aspects of HCAI. To do so, we introduce the term HCAI agent to refer to any physical or software computational agent equipped with AI components and that interacts and/or collaborates with humans. This article identifies five main conceptual components that participate in an HCAI agent: Observations, Requirements, Actions, Explanations and Models. We see the notion of HCAI agent, together with its components and functions, as a way to bridge the technical and non-technical discussions on human-centered AI. In this paper, we focus our analysis on scenarios consisting of a single agent operating in dynamic environments in presence of humans.
Online Grounding of PDDL Domains by Acting and Sensing in Unknown Environments
Dec 18, 2021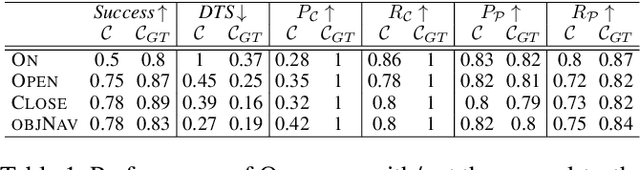
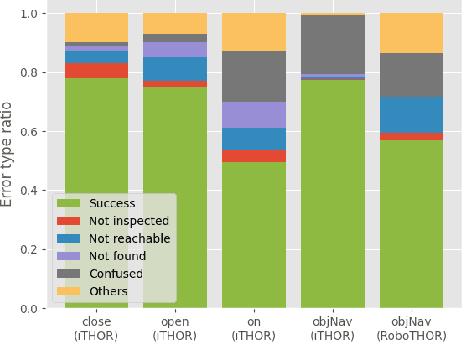

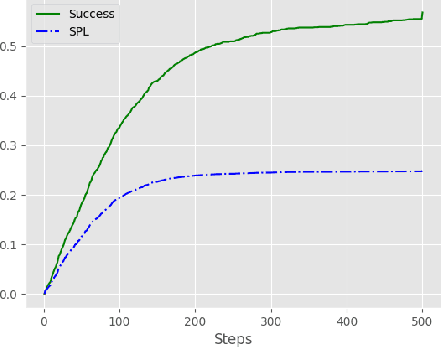
To effectively use an abstract (PDDL) planning domain to achieve goals in an unknown environment, an agent must instantiate such a domain with the objects of the environment and their properties. If the agent has an egocentric and partial view of the environment, it needs to act, sense, and abstract the perceived data in the planning domain. Furthermore, the agent needs to compile the plans computed by a symbolic planner into low level actions executable by its actuators. This paper proposes a framework that aims to accomplish the aforementioned perspective and allows an agent to perform different tasks. For this purpose, we integrate machine learning models to abstract the sensory data, symbolic planning for goal achievement and path planning for navigation. We evaluate the proposed method in accurate simulated environments, where the sensors are RGB-D on-board camera, GPS and compass.
Deliberative Acting, Online Planning and Learning with Hierarchical Operational Models
Oct 02, 2020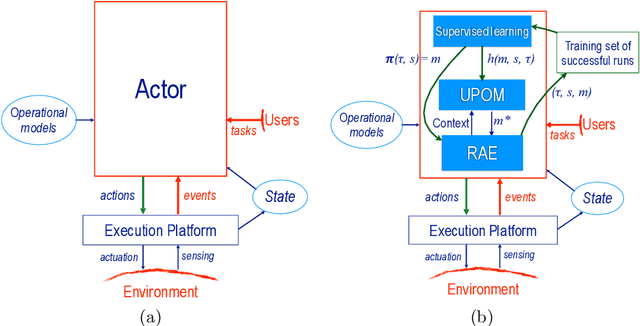
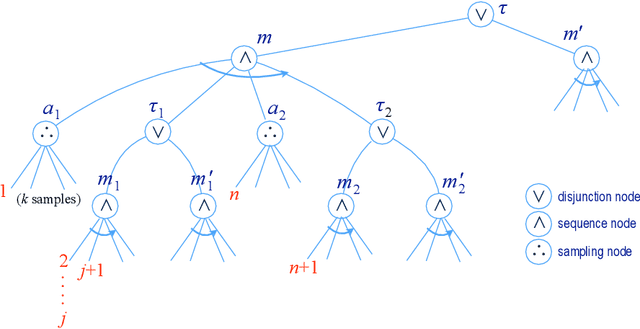

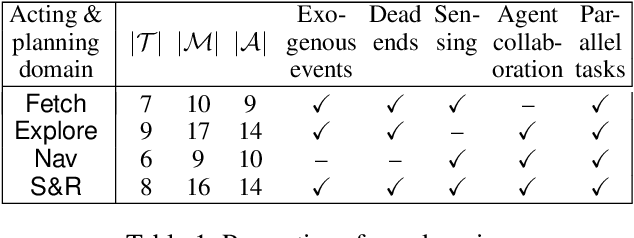
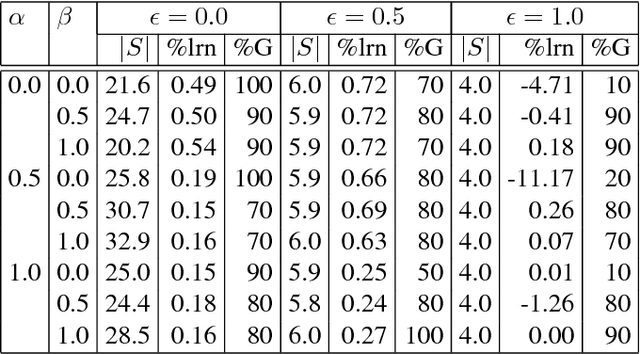
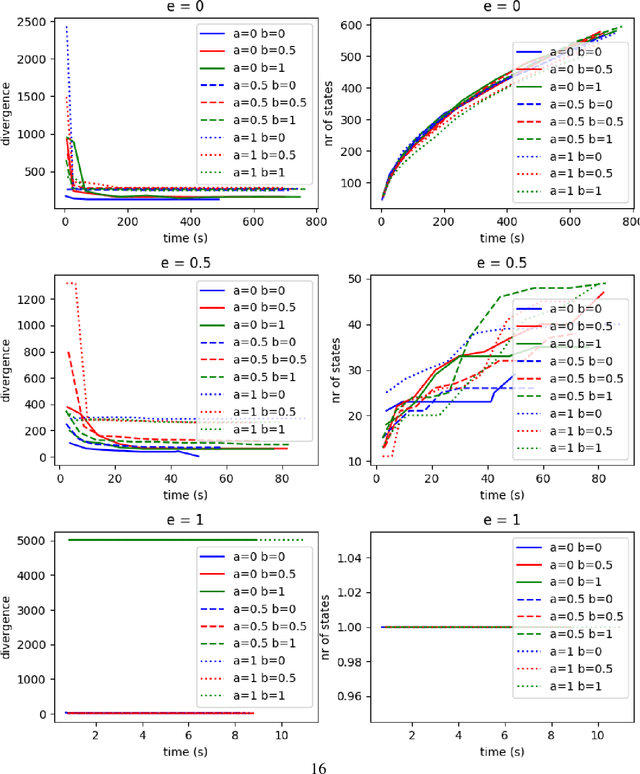
The most common representation formalisms for automated planning are descriptive models that abstractly describe what the actions do and are tailored for effciently computing the next state(s) in a state-transition system. However, real-world acting requires operational models that describe how to do things, with rich control structures for closed-loop online decision-making in a dynamic environment. To use a different action model for planning than the one used for acting causes problems with combining acting and planning, in particular for the development and consistency verification of the different models. As an alternative, we define and implement an integrated acting-and-planning system in which both planning and acting use the same operational models, which are written in a general-purpose hierarchical task-oriented language offering rich control structures. The acting component, called Reactive Acting Engine (RAE), is inspired by the well-known PRS system, except that instead of being purely reactive, it can get advice from the planner. Our planner uses a UCT-like Monte Carlo Tree Search procedure, called UPOM (UCT Procedure for Operational Models), whose rollouts are simulations of the actor's operational models. We also present learning strategies for use with RAE and UPOM that acquire, from online acting experiences and/or simulated planning results, a mapping from decision contexts to method instances as well as a heuristic function to guide UPOM. Our experimental results show that UPOM and our learning strategies significantly improve the acting efficiency and robustness of RAE. We discuss the asymptotic convergence of UPOM by mapping its search space to an MDP.
Integrating Acting, Planning and Learning in Hierarchical Operational Models
Mar 09, 2020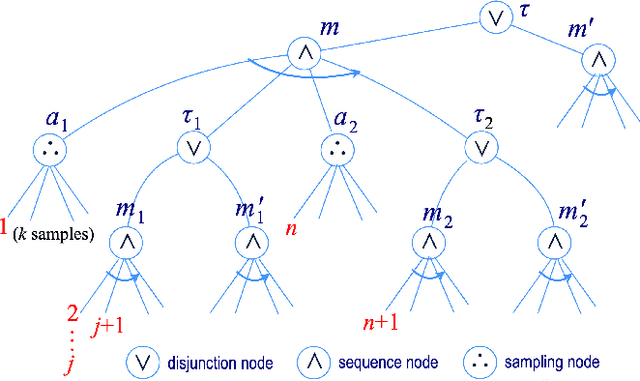
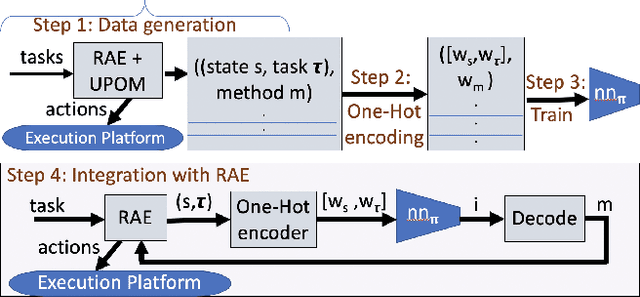

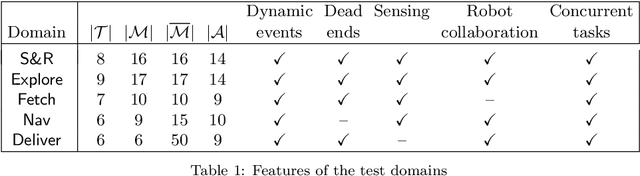
We present new planning and learning algorithms for RAE, the Refinement Acting Engine. RAE uses hierarchical operational models to perform tasks in dynamically changing environments. Our planning procedure, UPOM, does a UCT-like search in the space of operational models in order to find a near-optimal method to use for the task and context at hand. Our learning strategies acquire, from online acting experiences and/or simulated planning results, a mapping from decision contexts to method instances as well as a heuristic function to guide UPOM. Our experimental results show that UPOM and our learning strategies significantly improve RAE's performance in four test domains using two different metrics: efficiency and success ratio.
Incremental Learning of Discrete Planning Domains from Continuous Perceptions
Mar 14, 2019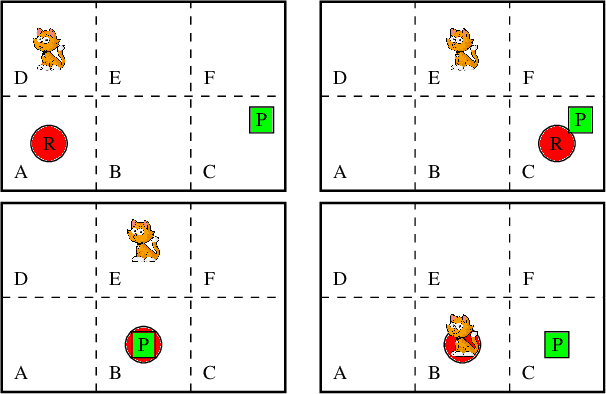
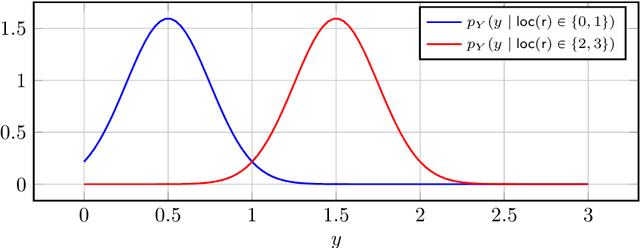
We propose a framework for learning discrete deterministic planning domains. In this framework, an agent learns the domain by observing the action effects through continuous features that describe the state of the environment after the execution of each action. Besides, the agent learns its perception function, i.e., a probabilistic mapping between state variables and sensor data represented as a vector of continuous random variables called perception variables. We define an algorithm that updates the planning domain and the perception function by (i) introducing new states, either by extending the possible values of state variables, or by weakening their constraints; (ii) adapts the perception function to fit the observed data (iii) adapts the transition function on the basis of the executed actions and the effects observed via the perception function. The framework is able to deal with exogenous events that happen in the environment.
Learning abstract planning domains and mappings to real world perceptions
Oct 16, 2018
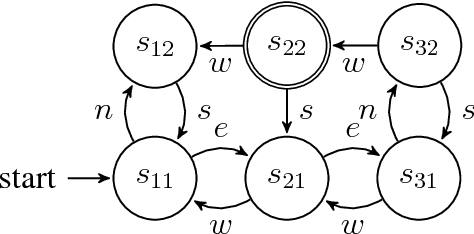
Most of the works on planning and learning, e.g., planning by (model based) reinforcement learning, are based on two main assumptions: (i) the set of states of the planning domain is fixed; (ii) the mapping between the observations from the real word and the states is implicitly assumed, and is not part of the planning domain. Consequently, the focus is on learning the transitions between states. Current approaches address neither the problem of learning new states of the planning domain, nor the problem of representing and updating the mapping between the real world perceptions and the states. In this paper, we drop such assumptions. We provide a formal framework in which (i) the agent can learn dynamically new states of the planning domain; (ii) the mapping between abstract states and the perception from the real world, represented by continuous variables, is part of the planning domain; (iii) such mapping is learned and updated along the "life" of the agent. We define and develop an algorithm that interleaves planning, acting, and learning. We provide a first experimental evaluation that shows how this novel framework can effectively learn coherent abstract planning models.