 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning abstract planning domains and mappings to real world perceptions
Paper and Code
Oct 16, 2018
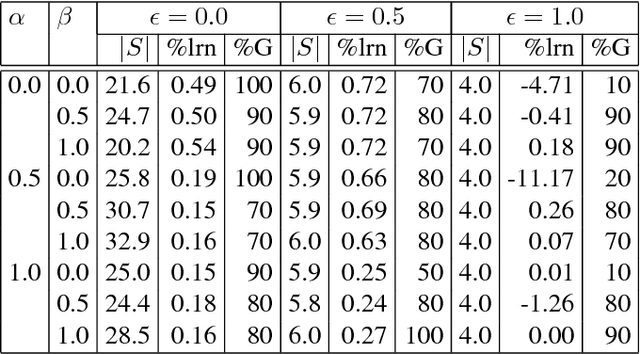
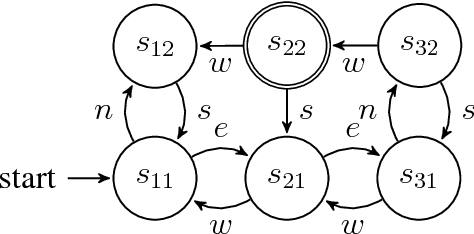
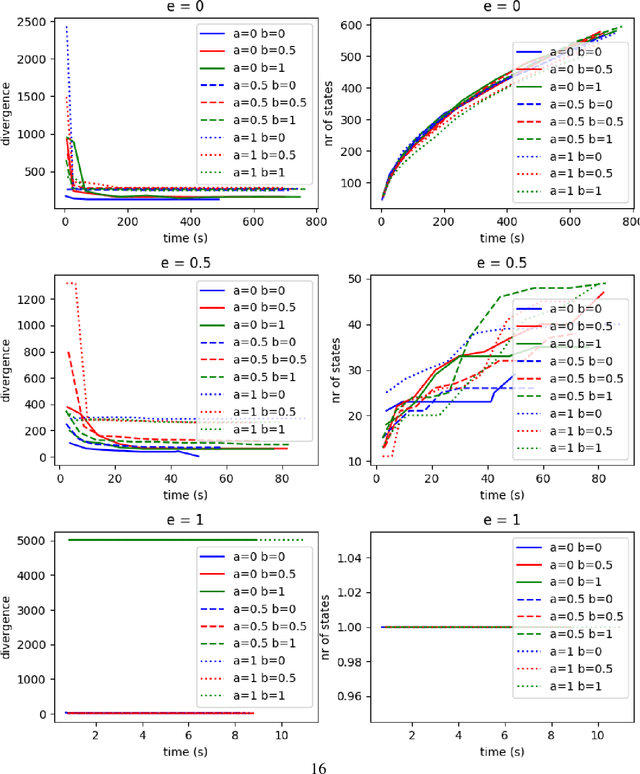
Most of the works on planning and learning, e.g., planning by (model based) reinforcement learning, are based on two main assumptions: (i) the set of states of the planning domain is fixed; (ii) the mapping between the observations from the real word and the states is implicitly assumed, and is not part of the planning domain. Consequently, the focus is on learning the transitions between states. Current approaches address neither the problem of learning new states of the planning domain, nor the problem of representing and updating the mapping between the real world perceptions and the states. In this paper, we drop such assumptions. We provide a formal framework in which (i) the agent can learn dynamically new states of the planning domain; (ii) the mapping between abstract states and the perception from the real world, represented by continuous variables, is part of the planning domain; (iii) such mapping is learned and updated along the "life" of the agent. We define and develop an algorithm that interleaves planning, acting, and learning. We provide a first experimental evaluation that shows how this novel framework can effectively learn coherent abstract planning models.