 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeliberative Acting, Online Planning and Learning with Hierarchical Operational Models
Oct 02, 2020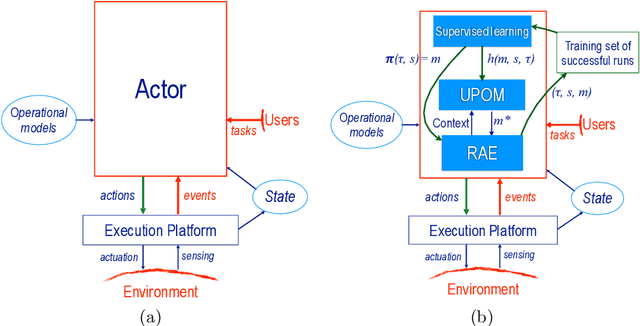
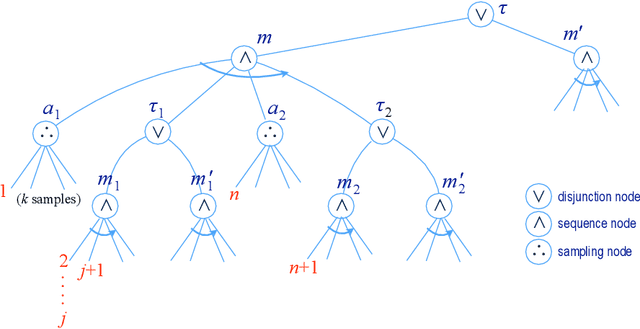

The most common representation formalisms for automated planning are descriptive models that abstractly describe what the actions do and are tailored for effciently computing the next state(s) in a state-transition system. However, real-world acting requires operational models that describe how to do things, with rich control structures for closed-loop online decision-making in a dynamic environment. To use a different action model for planning than the one used for acting causes problems with combining acting and planning, in particular for the development and consistency verification of the different models. As an alternative, we define and implement an integrated acting-and-planning system in which both planning and acting use the same operational models, which are written in a general-purpose hierarchical task-oriented language offering rich control structures. The acting component, called Reactive Acting Engine (RAE), is inspired by the well-known PRS system, except that instead of being purely reactive, it can get advice from the planner. Our planner uses a UCT-like Monte Carlo Tree Search procedure, called UPOM (UCT Procedure for Operational Models), whose rollouts are simulations of the actor's operational models. We also present learning strategies for use with RAE and UPOM that acquire, from online acting experiences and/or simulated planning results, a mapping from decision contexts to method instances as well as a heuristic function to guide UPOM. Our experimental results show that UPOM and our learning strategies significantly improve the acting efficiency and robustness of RAE. We discuss the asymptotic convergence of UPOM by mapping its search space to an MDP.
Integrating Acting, Planning and Learning in Hierarchical Operational Models
Mar 09, 2020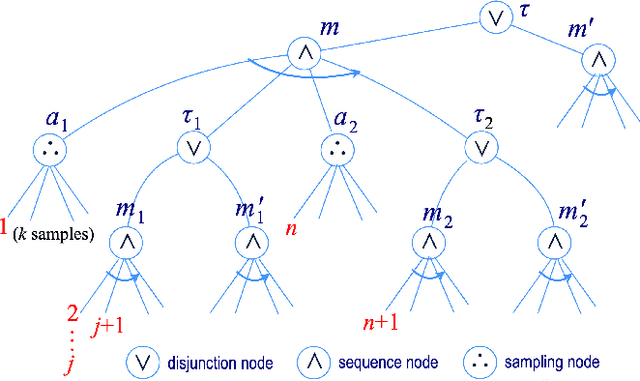
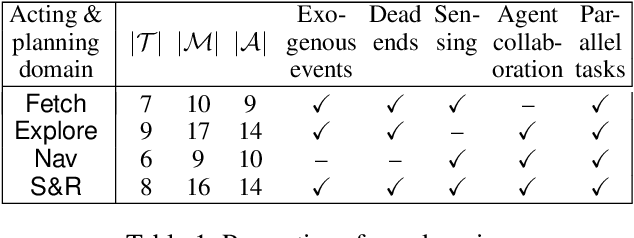
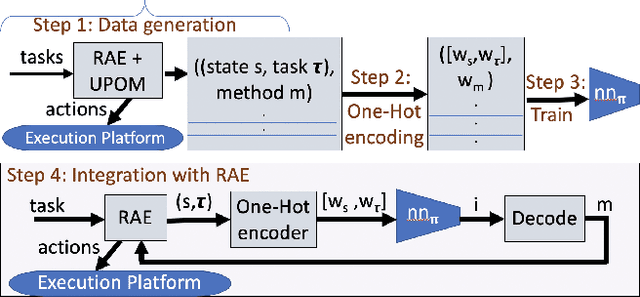

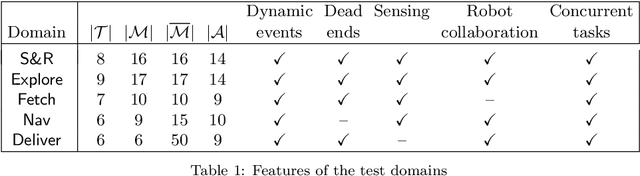
We present new planning and learning algorithms for RAE, the Refinement Acting Engine. RAE uses hierarchical operational models to perform tasks in dynamically changing environments. Our planning procedure, UPOM, does a UCT-like search in the space of operational models in order to find a near-optimal method to use for the task and context at hand. Our learning strategies acquire, from online acting experiences and/or simulated planning results, a mapping from decision contexts to method instances as well as a heuristic function to guide UPOM. Our experimental results show that UPOM and our learning strategies significantly improve RAE's performance in four test domains using two different metrics: efficiency and success ratio.
A Machine Learning Dataset Prepared From the NASA Solar Dynamics Observatory Mission
Mar 11, 2019
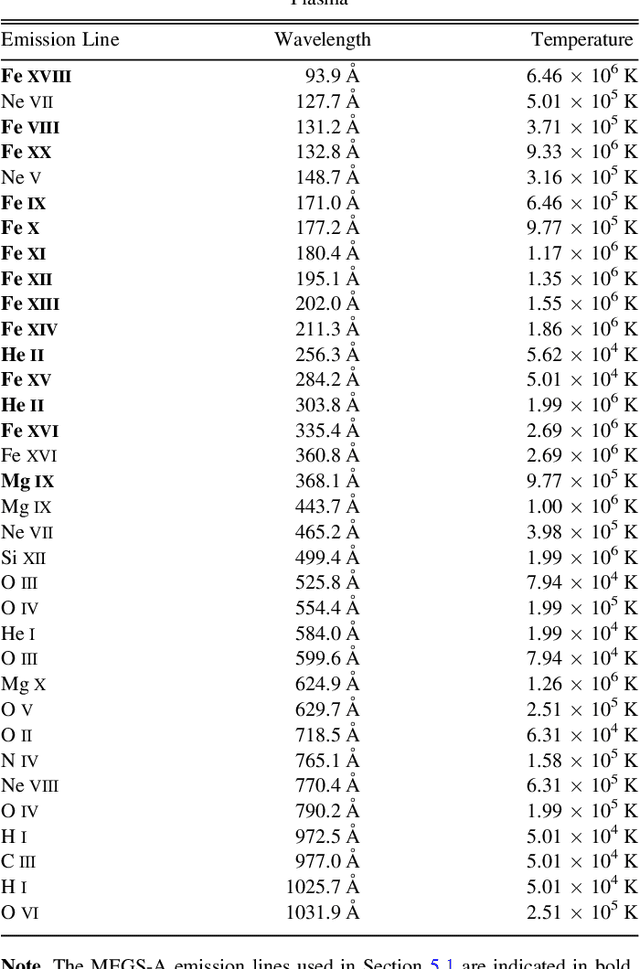
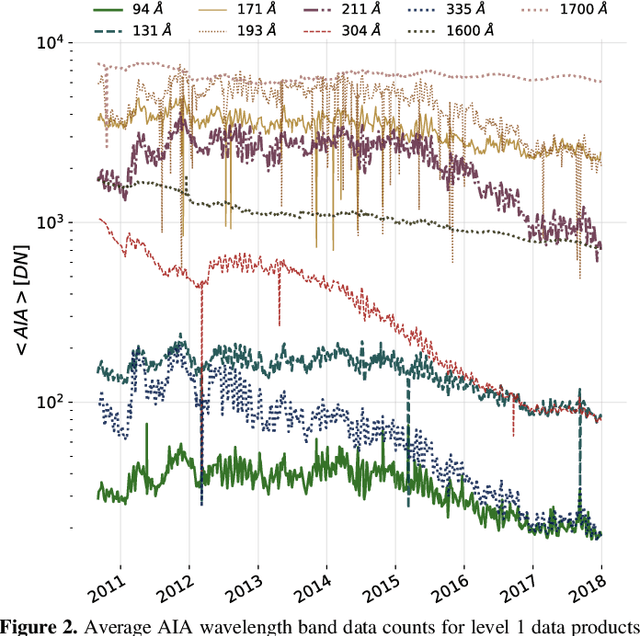

In this paper we present a curated dataset from the NASA Solar Dynamics Observatory (SDO) mission in a format suitable for machine learning research. Beginning from level 1 scientific products we have processed various instrumental corrections, downsampled to manageable spatial and temporal resolutions, and synchronized observations spatially and temporally. We illustrate the use of this dataset with two example applications: forecasting future EVE irradiance from present EVE irradiance and translating HMI observations into AIA observations. For each application we provide metrics and baselines for future model comparison. We anticipate this curated dataset will facilitate machine learning research in heliophysics and the physical sciences generally, increasing the scientific return of the SDO mission. This work is a direct result of the 2018 NASA Frontier Development Laboratory Program. Please see the appendix for access to the dataset.