 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLangNavBench: Evaluation of Natural Language Understanding in Semantic Navigation
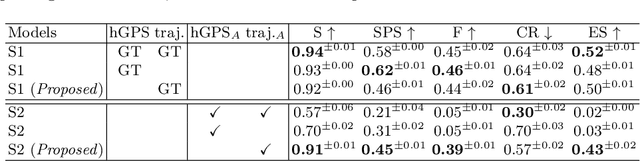
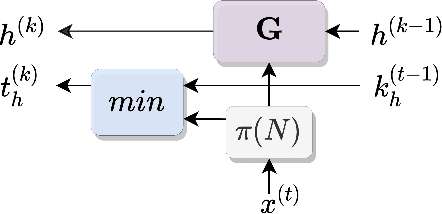
Jul 09, 2025Recent progress in large vision-language models has driven improvements in language-based semantic navigation, where an embodied agent must reach a target object described in natural language. Despite these advances, we still lack a clear, language-focused benchmark for testing how well such agents ground the words in their instructions. We address this gap with LangNav, an open-set dataset specifically created to test an agent's ability to locate objects described at different levels of detail, from broad category names to fine attributes and object-object relations. Every description in LangNav was manually checked, yielding a lower error rate than existing lifelong- and semantic-navigation datasets. On top of LangNav we build LangNavBench, a benchmark that measures how well current semantic-navigation methods understand and act on these descriptions while moving toward their targets. LangNavBench allows us to systematically compare models on their handling of attributes, spatial and relational cues, and category hierarchies, offering the first thorough, language-centric evaluation of embodied navigation systems. We also present Multi-Layered Feature Map (MLFM), a method that builds a queryable multi-layered semantic map, particularly effective when dealing with small objects or instructions involving spatial relations. MLFM outperforms state-of-the-art mapping-based navigation baselines on the LangNav dataset.
Following the Human Thread in Social Navigation
Apr 17, 2024


The success of collaboration between humans and robots in shared environments relies on the robot's real-time adaptation to human motion. Specifically, in Social Navigation, the agent should be close enough to assist but ready to back up to let the human move freely, avoiding collisions. Human trajectories emerge as crucial cues in Social Navigation, but they are partially observable from the robot's egocentric view and computationally complex to process. We propose the first Social Dynamics Adaptation model (SDA) based on the robot's state-action history to infer the social dynamics. We propose a two-stage Reinforcement Learning framework: the first learns to encode the human trajectories into social dynamics and learns a motion policy conditioned on this encoded information, the current status, and the previous action. Here, the trajectories are fully visible, i.e., assumed as privileged information. In the second stage, the trained policy operates without direct access to trajectories. Instead, the model infers the social dynamics solely from the history of previous actions and statuses in real-time. Tested on the novel Habitat 3.0 platform, SDA sets a novel state of the art (SoA) performance in finding and following humans.
Simple and Effective Transfer Learning for Neuro-Symbolic Integration
Feb 21, 2024



Deep Learning (DL) techniques have achieved remarkable successes in recent years. However, their ability to generalize and execute reasoning tasks remains a challenge. A potential solution to this issue is Neuro-Symbolic Integration (NeSy), where neural approaches are combined with symbolic reasoning. Most of these methods exploit a neural network to map perceptions to symbols and a logical reasoner to predict the output of the downstream task. These methods exhibit superior generalization capacity compared to fully neural architectures. However, they suffer from several issues, including slow convergence, learning difficulties with complex perception tasks, and convergence to local minima. This paper proposes a simple yet effective method to ameliorate these problems. The key idea involves pretraining a neural model on the downstream task. Then, a NeSy model is trained on the same task via transfer learning, where the weights of the perceptual part are injected from the pretrained network. The key observation of our work is that the neural network fails to generalize only at the level of the symbolic part while being perfectly capable of learning the mapping from perceptions to symbols. We have tested our training strategy on various SOTA NeSy methods and datasets, demonstrating consistent improvements in the aforementioned problems.
Reduce, Reuse, Recycle: Modular Multi-Object Navigation
Apr 07, 2023



Our work focuses on the Multi-Object Navigation (MultiON) task, where an agent needs to navigate to multiple objects in a given sequence. We systematically investigate the inherent modularity of this task by dividing our approach to contain four modules: (a) an object detection module trained to identify objects from RGB images, (b) a map building module to build a semantic map of the observed objects, (c) an exploration module enabling the agent to explore its surroundings, and finally (d) a navigation module to move to identified target objects. We focus on the navigation and the exploration modules in this work. We show that we can effectively leverage a PointGoal navigation model in the MultiON task instead of learning to navigate from scratch. Our experiments show that a PointGoal agent-based navigation module outperforms analytical path planning on the MultiON task. We also compare exploration strategies and surprisingly find that a random exploration strategy significantly outperforms more advanced exploration methods. We additionally create MultiON 2.0, a new large-scale dataset as a test-bed for our approach.
Exploiting Socially-Aware Tasks for Embodied Social Navigation
Dec 01, 2022Learning how to navigate among humans in an occluded and spatially constrained indoor environment, is a key ability required to embodied agent to be integrated into our society. In this paper, we propose an end-to-end architecture that exploits Socially-Aware Tasks (referred as to Risk and Social Compass) to inject into a reinforcement learning navigation policy the ability to infer common-sense social behaviors. To this end, our tasks exploit the notion of immediate and future dangers of collision. Furthermore, we propose an evaluation protocol specifically designed for the Social Navigation Task in simulated environments. This is done to capture fine-grained features and characteristics of the policy by analyzing the minimal unit of human-robot spatial interaction, called Encounter. We validate our approach on Gibson4+ and Habitat-Matterport3D datasets.
Retrospectives on the Embodied AI Workshop
Oct 17, 2022

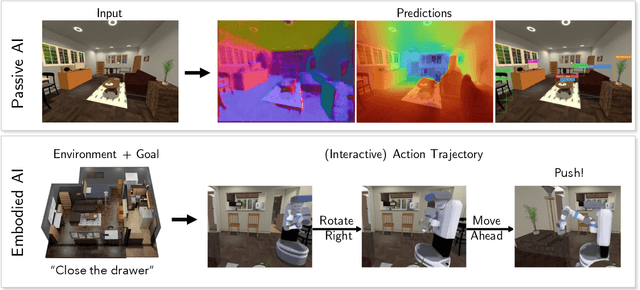
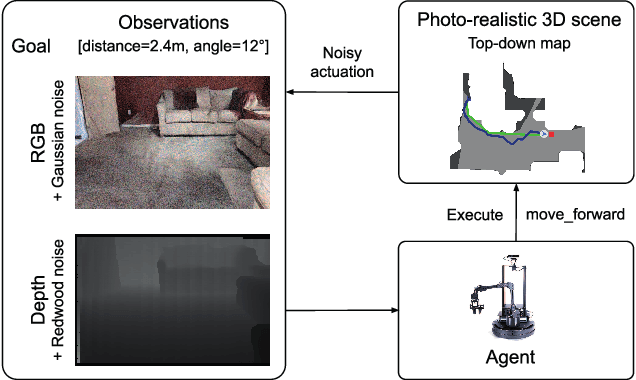
We present a retrospective on the state of Embodied AI research. Our analysis focuses on 13 challenges presented at the Embodied AI Workshop at CVPR. These challenges are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of state-of-the-art models. We highlight commonalities between top approaches to the challenges and identify potential future directions for Embodied AI research.
Deep Symbolic Learning: Discovering Symbols and Rules from Perceptions
Aug 24, 2022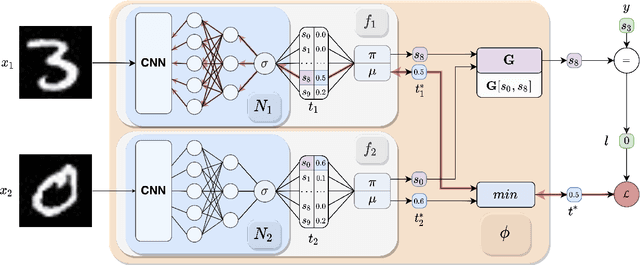

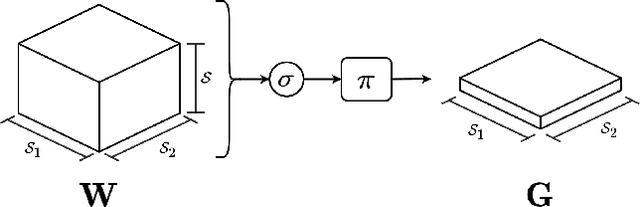
Neuro-Symbolic (NeSy) integration combines symbolic reasoning with Neural Networks (NNs) for tasks requiring perception and reasoning. Most NeSy systems rely on continuous relaxation of logical knowledge and no discrete decisions are made within the model pipeline. Furthermore, these methods assume that the symbolic rules are given. In this paper, we propose Deep Symbolic Learning (DSL), a NeSy system that learns NeSy-functions, i.e., the composition of a (set of) perception functions which map continuous data to discrete symbols, and a symbolic function over the set of symbols. DSL learns simultaneously the perception and symbolic functions, while being trained only on their composition (NeSy-function). The key novelty of DSL is that it can create internal (interpretable) symbolic representations and map them to perception inputs within a differentiable NN learning pipeline. The created symbols are automatically selected to generate symbolic functions that best explain the data. We provide experimental analysis to substantiate the efficacy of DSL in simultaneously learning perception and symbolic functions.
Online Learning of Reusable Abstract Models for Object Goal Navigation
Mar 04, 2022


In this paper, we present a novel approach to incrementally learn an Abstract Model of an unknown environment, and show how an agent can reuse the learned model for tackling the Object Goal Navigation task. The Abstract Model is a finite state machine in which each state is an abstraction of a state of the environment, as perceived by the agent in a certain position and orientation. The perceptions are high-dimensional sensory data (e.g., RGB-D images), and the abstraction is reached by exploiting image segmentation and the Taskonomy model bank. The learning of the Abstract Model is accomplished by executing actions, observing the reached state, and updating the Abstract Model with the acquired information. The learned models are memorized by the agent, and they are reused whenever it recognizes to be in an environment that corresponds to the stored model. We investigate the effectiveness of the proposed approach for the Object Goal Navigation task, relying on public benchmarks. Our results show that the reuse of learned Abstract Models can boost performance on Object Goal Navigation.
Exploiting Scene-specific Features for Object Goal Navigation
Aug 21, 2020
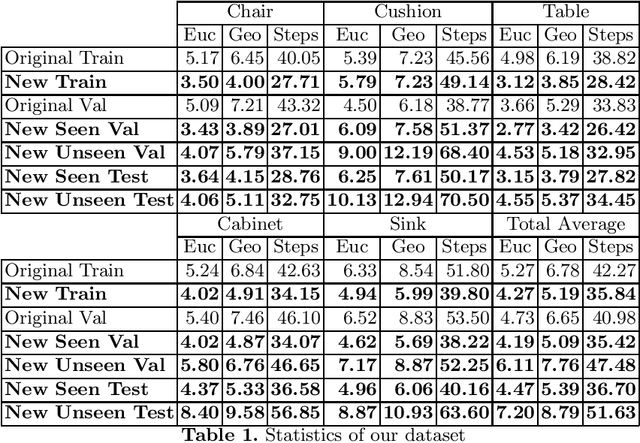
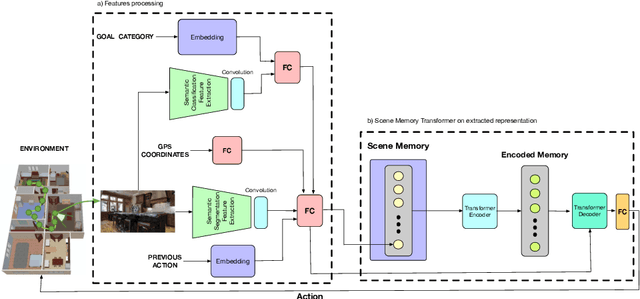
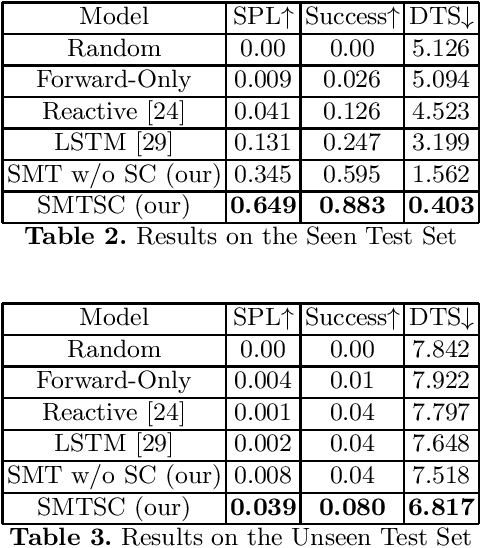
Can the intrinsic relation between an object and the room in which it is usually located help agents in the Visual Navigation Task? We study this question in the context of Object Navigation, a problem in which an agent has to reach an object of a specific class while moving in a complex domestic environment. In this paper, we introduce a new reduced dataset that speeds up the training of navigation models, a notoriously complex task. Our proposed dataset permits the training of models that do not exploit online-built maps in reasonable times even without the use of huge computational resources. Therefore, this reduced dataset guarantees a significant benchmark and it can be used to identify promising models that could be then tried on bigger and more challenging datasets. Subsequently, we propose the SMTSC model, an attention-based model capable of exploiting the correlation between scenes and objects contained in them, highlighting quantitatively how the idea is correct.