 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVISOR: VIsual Spatial Object Reasoning for Language-driven Object Navigation
Feb 07, 2026Language-driven object navigation requires agents to interpret natural language descriptions of target objects, which combine intrinsic and extrinsic attributes for instance recognition and commonsense navigation. Existing methods either (i) use end-to-end trained models with vision-language embeddings, which struggle to generalize beyond training data and lack action-level explainability, or (ii) rely on modular zero-shot pipelines with large language models (LLMs) and open-set object detectors, which suffer from error propagation, high computational cost, and difficulty integrating their reasoning back into the navigation policy. To this end, we propose a compact 3B-parameter Vision-Language-Action (VLA) agent that performs human-like embodied reasoning for both object recognition and action selection, removing the need for stitched multi-model pipelines. Instead of raw embedding matching, our agent employs explicit image-grounded reasoning to directly answer "Is this the target object?" and "Why should I take this action?" The reasoning process unfolds in three stages: "think", "think summary", and "action", yielding improved explainability, stronger generalization, and more efficient navigation. Code and dataset available upon acceptance.
LangNavBench: Evaluation of Natural Language Understanding in Semantic Navigation
Jul 09, 2025Recent progress in large vision-language models has driven improvements in language-based semantic navigation, where an embodied agent must reach a target object described in natural language. Despite these advances, we still lack a clear, language-focused benchmark for testing how well such agents ground the words in their instructions. We address this gap with LangNav, an open-set dataset specifically created to test an agent's ability to locate objects described at different levels of detail, from broad category names to fine attributes and object-object relations. Every description in LangNav was manually checked, yielding a lower error rate than existing lifelong- and semantic-navigation datasets. On top of LangNav we build LangNavBench, a benchmark that measures how well current semantic-navigation methods understand and act on these descriptions while moving toward their targets. LangNavBench allows us to systematically compare models on their handling of attributes, spatial and relational cues, and category hierarchies, offering the first thorough, language-centric evaluation of embodied navigation systems. We also present Multi-Layered Feature Map (MLFM), a method that builds a queryable multi-layered semantic map, particularly effective when dealing with small objects or instructions involving spatial relations. MLFM outperforms state-of-the-art mapping-based navigation baselines on the LangNav dataset.
Semantic Mapping in Indoor Embodied AI -- A Comprehensive Survey and Future Directions
Jan 10, 2025



Intelligent embodied agents (e.g. robots) need to perform complex semantic tasks in unfamiliar environments. Among many skills that the agents need to possess, building and maintaining a semantic map of the environment is most crucial in long-horizon tasks. A semantic map captures information about the environment in a structured way, allowing the agent to reference it for advanced reasoning throughout the task. While existing surveys in embodied AI focus on general advancements or specific tasks like navigation and manipulation, this paper provides a comprehensive review of semantic map-building approaches in embodied AI, specifically for indoor navigation. We categorize these approaches based on their structural representation (spatial grids, topological graphs, dense point-clouds or hybrid maps) and the type of information they encode (implicit features or explicit environmental data). We also explore the strengths and limitations of the map building techniques, highlight current challenges, and propose future research directions. We identify that the field is moving towards developing open-vocabulary, queryable, task-agnostic map representations, while high memory demands and computational inefficiency still remaining to be open challenges. This survey aims to guide current and future researchers in advancing semantic mapping techniques for embodied AI systems.
NL-SLAM for OC-VLN: Natural Language Grounded SLAM for Object-Centric VLN
Nov 12, 2024



Landmark-based navigation (e.g. go to the wooden desk) and relative positional navigation (e.g. move 5 meters forward) are distinct navigation challenges solved very differently in existing robotics navigation methodology. We present a new dataset, OC-VLN, in order to distinctly evaluate grounding object-centric natural language navigation instructions in a method for performing landmark-based navigation. We also propose Natural Language grounded SLAM (NL-SLAM), a method to ground natural language instruction to robot observations and poses. We actively perform NL-SLAM in order to follow object-centric natural language navigation instructions. Our methods leverage pre-trained vision and language foundation models and require no task-specific training. We construct two strong baselines from state-of-the-art methods on related tasks, Object Goal Navigation and Vision Language Navigation, and we show that our approach, NL-SLAM, outperforms these baselines across all our metrics of success on OC-VLN. Finally, we successfully demonstrate the effectiveness of NL-SLAM for performing navigation instruction following in the real world on a Boston Dynamics Spot robot.
R3DS: Reality-linked 3D Scenes for Panoramic Scene Understanding
Mar 18, 2024



We introduce the Reality-linked 3D Scenes (R3DS) dataset of synthetic 3D scenes mirroring the real-world scene arrangements from Matterport3D panoramas. Compared to prior work, R3DS has more complete and densely populated scenes with objects linked to real-world observations in panoramas. R3DS also provides an object support hierarchy, and matching object sets (e.g., same chairs around a dining table) for each scene. Overall, R3DS contains 19K objects represented by 3,784 distinct CAD models from over 100 object categories. We demonstrate the effectiveness of R3DS on the Panoramic Scene Understanding task. We find that: 1) training on R3DS enables better generalization; 2) support relation prediction trained with R3DS improves performance compared to heuristically calculated support; and 3) R3DS offers a challenging benchmark for future work on panoramic scene understanding.
Reduce, Reuse, Recycle: Modular Multi-Object Navigation
Apr 07, 2023



Our work focuses on the Multi-Object Navigation (MultiON) task, where an agent needs to navigate to multiple objects in a given sequence. We systematically investigate the inherent modularity of this task by dividing our approach to contain four modules: (a) an object detection module trained to identify objects from RGB images, (b) a map building module to build a semantic map of the observed objects, (c) an exploration module enabling the agent to explore its surroundings, and finally (d) a navigation module to move to identified target objects. We focus on the navigation and the exploration modules in this work. We show that we can effectively leverage a PointGoal navigation model in the MultiON task instead of learning to navigate from scratch. Our experiments show that a PointGoal agent-based navigation module outperforms analytical path planning on the MultiON task. We also compare exploration strategies and surprisingly find that a random exploration strategy significantly outperforms more advanced exploration methods. We additionally create MultiON 2.0, a new large-scale dataset as a test-bed for our approach.
Retrospectives on the Embodied AI Workshop
Oct 17, 2022

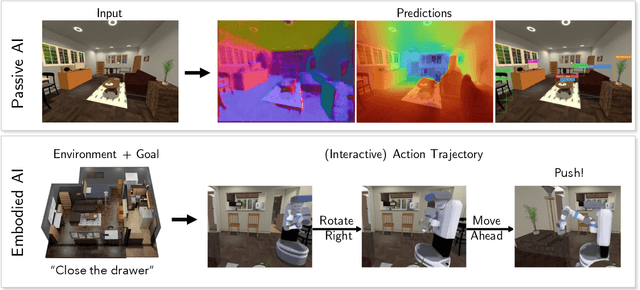
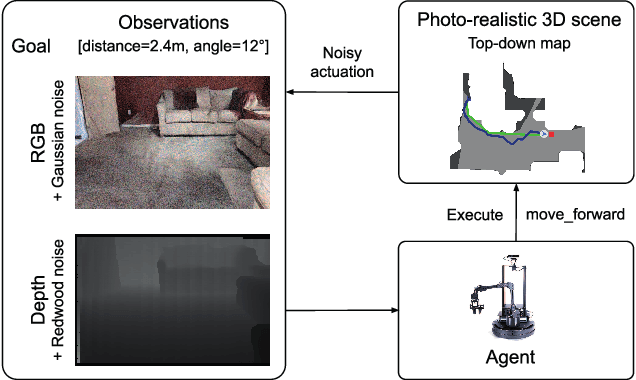
We present a retrospective on the state of Embodied AI research. Our analysis focuses on 13 challenges presented at the Embodied AI Workshop at CVPR. These challenges are grouped into three themes: (1) visual navigation, (2) rearrangement, and (3) embodied vision-and-language. We discuss the dominant datasets within each theme, evaluation metrics for the challenges, and the performance of state-of-the-art models. We highlight commonalities between top approaches to the challenges and identify potential future directions for Embodied AI research.
Language-Aligned Waypoint (LAW) Supervision for Vision-and-Language Navigation in Continuous Environments
Sep 30, 2021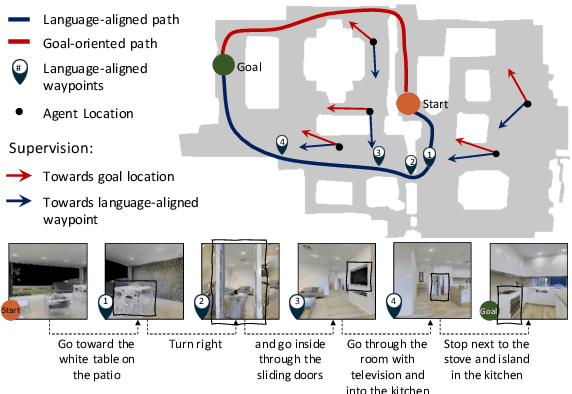

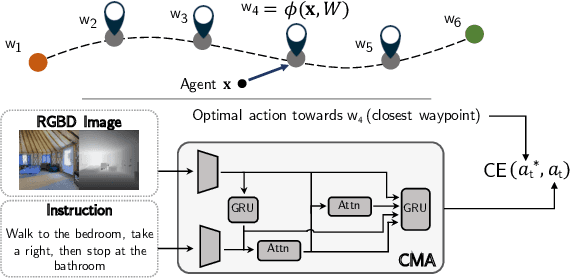
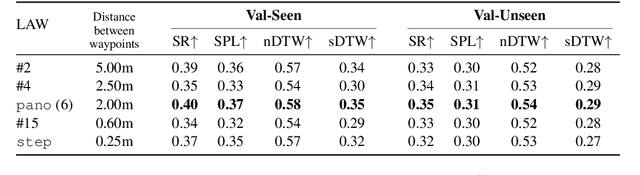
In the Vision-and-Language Navigation (VLN) task an embodied agent navigates a 3D environment, following natural language instructions. A challenge in this task is how to handle 'off the path' scenarios where an agent veers from a reference path. Prior work supervises the agent with actions based on the shortest path from the agent's location to the goal, but such goal-oriented supervision is often not in alignment with the instruction. Furthermore, the evaluation metrics employed by prior work do not measure how much of a language instruction the agent is able to follow. In this work, we propose a simple and effective language-aligned supervision scheme, and a new metric that measures the number of sub-instructions the agent has completed during navigation.
Video Moment Localization using Object Evidence and Reverse Captioning
Jun 18, 2020
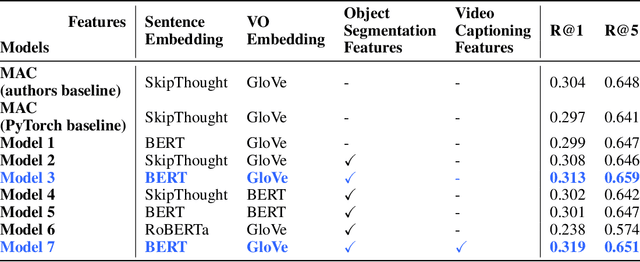
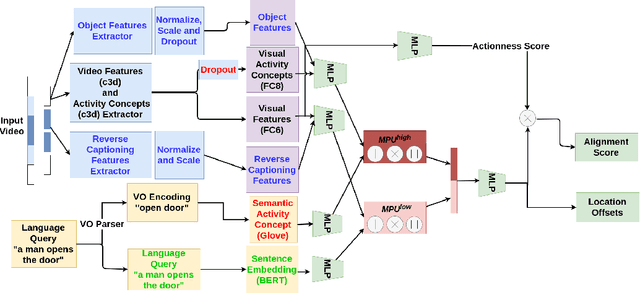

We address the problem of language-based temporal localization of moments in untrimmed videos. Compared to temporal localization with fixed categories, this problem is more challenging as the language-based queries have no predefined activity classes and may also contain complex descriptions. Current state-of-the-art model MAC addresses it by mining activity concepts from both video and language modalities. This method encodes the semantic activity concepts from the verb/object pair in a language query and leverages visual activity concepts from video activity classification prediction scores. We propose "Multi-faceted VideoMoment Localizer" (MML), an extension of MAC model by the introduction of visual object evidence via object segmentation masks and video understanding features via video captioning. Furthermore, we improve language modelling in sentence embedding. We experimented on Charades-STA dataset and identified that MML outperforms MAC baseline by 4.93% and 1.70% on R@1 and R@5metrics respectively. Our code and pre-trained model are publicly available at https://github.com/madhawav/MML.