 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAFT: A Tendon-Driven Hand with Hybrid Hard-Soft Compliance
Mar 12, 2026We introduce CRAFT hand, a tendon-driven anthropomorphic hand with hybrid hard-soft compliance for contact-rich manipulation. The design is based on a simple idea: contact is not uniform across the hand. Impacts concentrate at joints, while links carry most of the load. CRAFT places soft material at joints and keeps links rigid, and uses rollingcontact joint surfaces to keep flexion on repeatable motion paths. Fifteen motors mounted on the fingers drive the hand through tendons, keeping the form factor compact and the fingers light. In structural tests, CRAFT improves strength and endurance while maintaining comparable repeatability. In teleoperation, CRAFT improves handling of fragile and low-friction items, and the hand covers 33/33 grasps in the Feix taxonomy. The full design costs under $600 and will be released open-source with visionbased teleoperation and simulation integration. Project page: http://craft-hand.github.io/
Robotic Manipulation by Imitating Generated Videos Without Physical Demonstrations
Jul 01, 2025This work introduces Robots Imitating Generated Videos (RIGVid), a system that enables robots to perform complex manipulation tasks--such as pouring, wiping, and mixing--purely by imitating AI-generated videos, without requiring any physical demonstrations or robot-specific training. Given a language command and an initial scene image, a video diffusion model generates potential demonstration videos, and a vision-language model (VLM) automatically filters out results that do not follow the command. A 6D pose tracker then extracts object trajectories from the video, and the trajectories are retargeted to the robot in an embodiment-agnostic fashion. Through extensive real-world evaluations, we show that filtered generated videos are as effective as real demonstrations, and that performance improves with generation quality. We also show that relying on generated videos outperforms more compact alternatives such as keypoint prediction using VLMs, and that strong 6D pose tracking outperforms other ways to extract trajectories, such as dense feature point tracking. These findings suggest that videos produced by a state-of-the-art off-the-shelf model can offer an effective source of supervision for robotic manipulation.
A Real-to-Sim-to-Real Approach to Robotic Manipulation with VLM-Generated Iterative Keypoint Rewards
Feb 12, 2025Task specification for robotic manipulation in open-world environments is challenging, requiring flexible and adaptive objectives that align with human intentions and can evolve through iterative feedback. We introduce Iterative Keypoint Reward (IKER), a visually grounded, Python-based reward function that serves as a dynamic task specification. Our framework leverages VLMs to generate and refine these reward functions for multi-step manipulation tasks. Given RGB-D observations and free-form language instructions, we sample keypoints in the scene and generate a reward function conditioned on these keypoints. IKER operates on the spatial relationships between keypoints, leveraging commonsense priors about the desired behaviors, and enabling precise SE(3) control. We reconstruct real-world scenes in simulation and use the generated rewards to train reinforcement learning (RL) policies, which are then deployed into the real world-forming a real-to-sim-to-real loop. Our approach demonstrates notable capabilities across diverse scenarios, including both prehensile and non-prehensile tasks, showcasing multi-step task execution, spontaneous error recovery, and on-the-fly strategy adjustments. The results highlight IKER's effectiveness in enabling robots to perform multi-step tasks in dynamic environments through iterative reward shaping.
Interpretation of Emergent Communication in Heterogeneous Collaborative Embodied Agents
Oct 12, 2021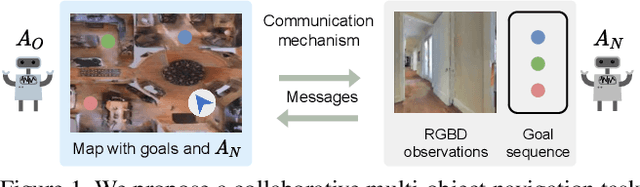
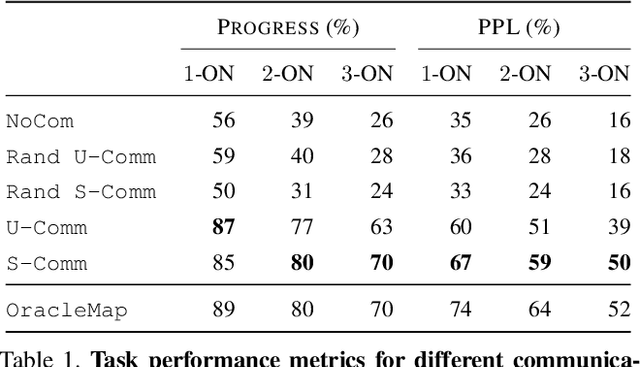
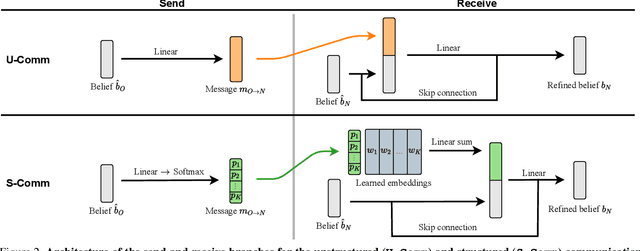
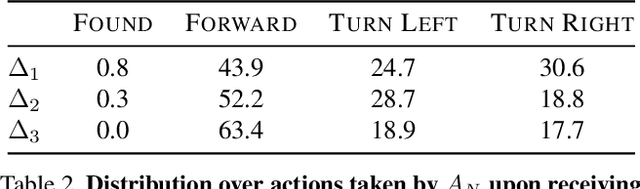
Communication between embodied AI agents has received increasing attention in recent years. Despite its use, it is still unclear whether the learned communication is interpretable and grounded in perception. To study the grounding of emergent forms of communication, we first introduce the collaborative multi-object navigation task CoMON. In this task, an oracle agent has detailed environment information in the form of a map. It communicates with a navigator agent that perceives the environment visually and is tasked to find a sequence of goals. To succeed at the task, effective communication is essential. CoMON hence serves as a basis to study different communication mechanisms between heterogeneous agents, that is, agents with different capabilities and roles. We study two common communication mechanisms and analyze their communication patterns through an egocentric and spatial lens. We show that the emergent communication can be grounded to the agent observations and the spatial structure of the 3D environment. Video summary: https://youtu.be/kLv2rxO9t0g
Language-Aligned Waypoint (LAW) Supervision for Vision-and-Language Navigation in Continuous Environments
Sep 30, 2021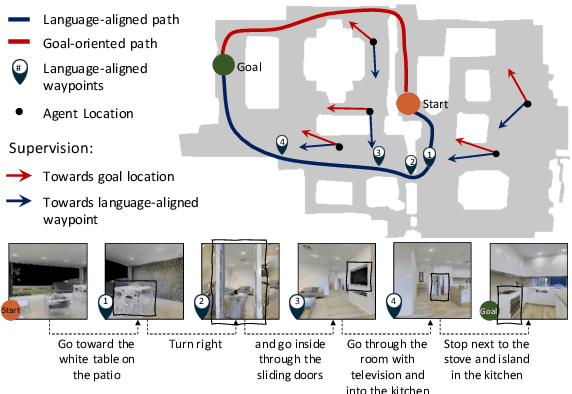

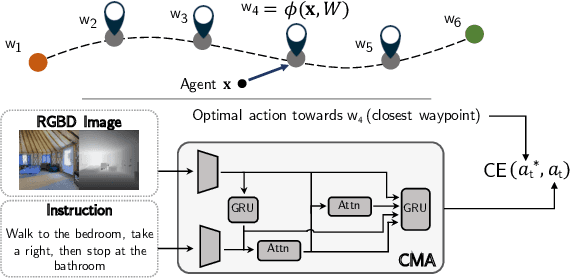
In the Vision-and-Language Navigation (VLN) task an embodied agent navigates a 3D environment, following natural language instructions. A challenge in this task is how to handle 'off the path' scenarios where an agent veers from a reference path. Prior work supervises the agent with actions based on the shortest path from the agent's location to the goal, but such goal-oriented supervision is often not in alignment with the instruction. Furthermore, the evaluation metrics employed by prior work do not measure how much of a language instruction the agent is able to follow. In this work, we propose a simple and effective language-aligned supervision scheme, and a new metric that measures the number of sub-instructions the agent has completed during navigation.
MultiON: Benchmarking Semantic Map Memory using Multi-Object Navigation
Dec 07, 2020
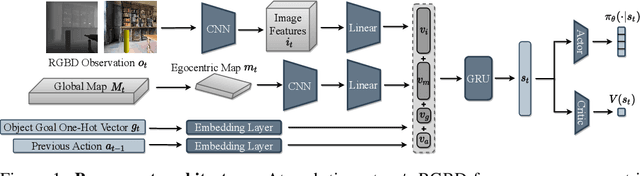


Navigation tasks in photorealistic 3D environments are challenging because they require perception and effective planning under partial observability. Recent work shows that map-like memory is useful for long-horizon navigation tasks. However, a focused investigation of the impact of maps on navigation tasks of varying complexity has not yet been performed. We propose the multiON task, which requires navigation to an episode-specific sequence of objects in a realistic environment. MultiON generalizes the ObjectGoal navigation task and explicitly tests the ability of navigation agents to locate previously observed goal objects. We perform a set of multiON experiments to examine how a variety of agent models perform across a spectrum of navigation task complexities. Our experiments show that: i) navigation performance degrades dramatically with escalating task complexity; ii) a simple semantic map agent performs surprisingly well relative to more complex neural image feature map agents; and iii) even oracle map agents achieve relatively low performance, indicating the potential for future work in training embodied navigation agents using maps. Video summary: https://youtu.be/yqTlHNIcgnY
Granular Multimodal Attention Networks for Visual Dialog
Oct 13, 2019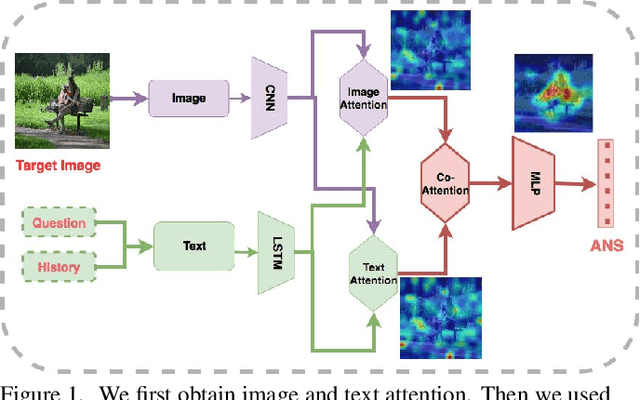
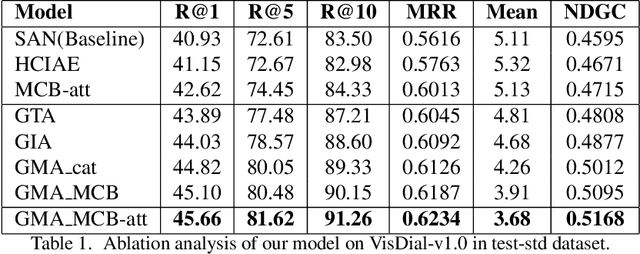
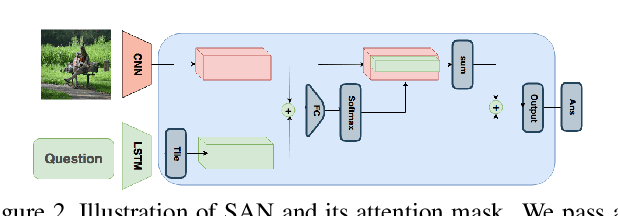
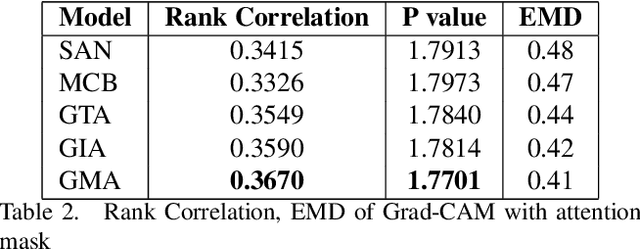
Vision and language tasks have benefited from attention. There have been a number of different attention models proposed. However, the scale at which attention needs to be applied has not been well examined. Particularly, in this work, we propose a new method Granular Multi-modal Attention, where we aim to particularly address the question of the right granularity at which one needs to attend while solving the Visual Dialog task. The proposed method shows improvement in both image and text attention networks. We then propose a granular Multi-modal Attention network that jointly attends on the image and text granules and shows the best performance. With this work, we observe that obtaining granular attention and doing exhaustive Multi-modal Attention appears to be the best way to attend while solving visual dialog.
U-CAM: Visual Explanation using Uncertainty based Class Activation Maps
Sep 16, 2019
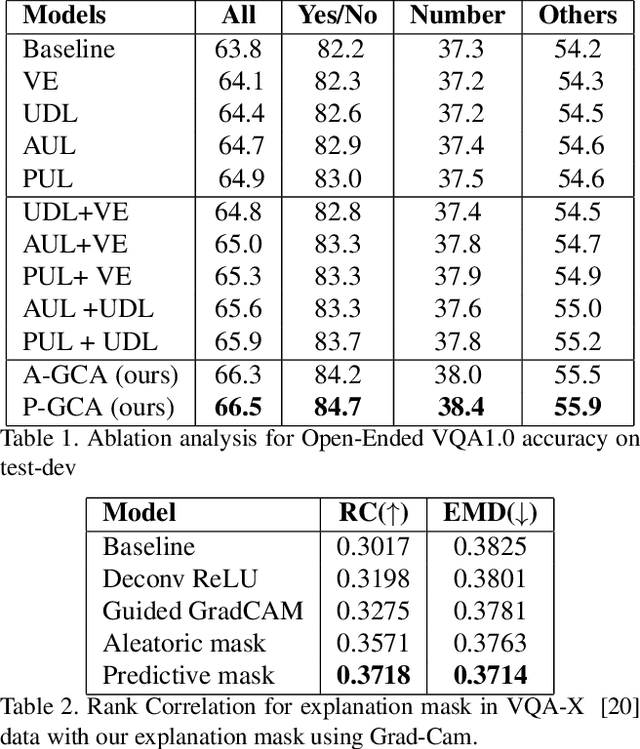
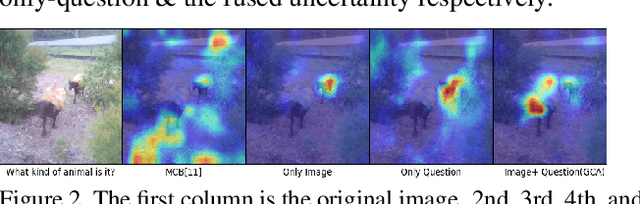
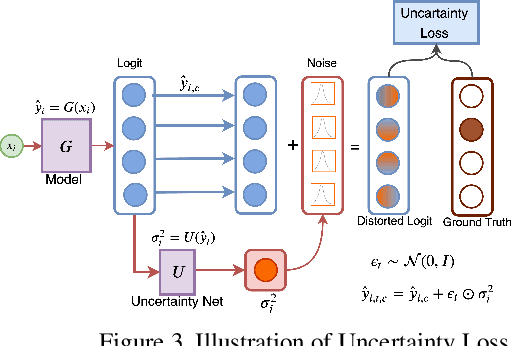
Understanding and explaining deep learning models is an imperative task. Towards this, we propose a method that obtains gradient-based certainty estimates that also provide visual attention maps. Particularly, we solve for visual question answering task. We incorporate modern probabilistic deep learning methods that we further improve by using the gradients for these estimates. These have two-fold benefits: a) improvement in obtaining the certainty estimates that correlate better with misclassified samples and b) improved attention maps that provide state-of-the-art results in terms of correlation with human attention regions. The improved attention maps result in consistent improvement for various methods for visual question answering. Therefore, the proposed technique can be thought of as a recipe for obtaining improved certainty estimates and explanation for deep learning models. We provide detailed empirical analysis for the visual question answering task on all standard benchmarks and comparison with state of the art methods.