 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHAMSA: Scanning-Free Vision State Space Models via SpectralPulseNet
Apr 16, 2026Vision State Space Models (SSMs) like Vim, VMamba, and SiMBA rely on complex scanning strategies to adapt sequential SSMs to process 2D images, introducing computational overhead and architectural complexity. We propose HAMSA, a scanning-free SSM operating directly in the spectral domain. HAMSA introduces three key innovations: (1) simplified kernel parameterization-a single Gaussian-initialized complex kernel replacing traditional (A, B, C) matrices, eliminating discretization instabilities; (2) SpectralPulseNet (SPN)-an input-dependent frequency gating mechanism enabling adaptive spectral modulation; and (3) Spectral Adaptive Gating Unit (SAGU)-magnitude-based gating for stable gradient flow in the frequency domain. By leveraging FFT-based convolution, HAMSA eliminates sequential scanning while achieving O(L log L) complexity with superior simplicity and efficiency. On ImageNet-1K, HAMSA reaches 85.7% top-1 accuracy (state-of-the-art among SSMs), with 2.2 X faster inference than transformers (4.2ms vs 9.2ms for DeiT-S) and 1.4-1.9X speedup over scanning-based SSMs, while using less memory (2.1GB vs 3.2-4.5GB) and energy (12.5J vs 18-25J). HAMSA demonstrates strong generalization across transfer learning and dense prediction tasks.
LLMOrbit: A Circular Taxonomy of Large Language Models -From Scaling Walls to Agentic AI Systems
Jan 20, 2026The field of artificial intelligence has undergone a revolution from foundational Transformer architectures to reasoning-capable systems approaching human-level performance. We present LLMOrbit, a comprehensive circular taxonomy navigating the landscape of large language models spanning 2019-2025. This survey examines over 50 models across 15 organizations through eight interconnected orbital dimensions, documenting architectural innovations, training methodologies, and efficiency patterns defining modern LLMs, generative AI, and agentic systems. We identify three critical crises: (1) data scarcity (9-27T tokens depleted by 2026-2028), (2) exponential cost growth ($3M to $300M+ in 5 years), and (3) unsustainable energy consumption (22x increase), establishing the scaling wall limiting brute-force approaches. Our analysis reveals six paradigms breaking this wall: (1) test-time compute (o1, DeepSeek-R1 achieve GPT-4 performance with 10x inference compute), (2) quantization (4-8x compression), (3) distributed edge computing (10x cost reduction), (4) model merging, (5) efficient training (ORPO reduces memory 50%), and (6) small specialized models (Phi-4 14B matches larger models). Three paradigm shifts emerge: (1) post-training gains (RLHF, GRPO, pure RL contribute substantially, DeepSeek-R1 achieving 79.8% MATH), (2) efficiency revolution (MoE routing 18x efficiency, Multi-head Latent Attention 8x KV cache compression enables GPT-4-level performance at <$0.30/M tokens), and (3) democratization (open-source Llama 3 88.6% MMLU surpasses GPT-4 86.4%). We provide insights into techniques (RLHF, PPO, DPO, GRPO, ORPO), trace evolution from passive generation to tool-using agents (ReAct, RAG, multi-agent systems), and analyze post-training innovations.
Spectral Convolutional Transformer: Harmonizing Real vs. Complex Multi-View Spectral Operators for Vision Transformer
Mar 26, 2024



Transformers used in vision have been investigated through diverse architectures - ViT, PVT, and Swin. These have worked to improve the attention mechanism and make it more efficient. Differently, the need for including local information was felt, leading to incorporating convolutions in transformers such as CPVT and CvT. Global information is captured using a complex Fourier basis to achieve global token mixing through various methods, such as AFNO, GFNet, and Spectformer. We advocate combining three diverse views of data - local, global, and long-range dependence. We also investigate the simplest global representation using only the real domain spectral representation - obtained through the Hartley transform. We use a convolutional operator in the initial layers to capture local information. Through these two contributions, we are able to optimize and obtain a spectral convolution transformer (SCT) that provides improved performance over the state-of-the-art methods while reducing the number of parameters. Through extensive experiments, we show that SCT-C-small gives state-of-the-art performance on the ImageNet dataset and reaches 84.5\% top-1 accuracy, while SCT-C-Large reaches 85.9\% and SCT-C-Huge reaches 86.4\%. We evaluate SCT on transfer learning on datasets such as CIFAR-10, CIFAR-100, Oxford Flower, and Stanford Car. We also evaluate SCT on downstream tasks i.e. instance segmentation on the MSCOCO dataset. The project page is available on this webpage.\url{https://github.com/badripatro/sct}
SiMBA: Simplified Mamba-Based Architecture for Vision and Multivariate Time series
Mar 22, 2024Transformers have widely adopted attention networks for sequence mixing and MLPs for channel mixing, playing a pivotal role in achieving breakthroughs across domains. However, recent literature highlights issues with attention networks, including low inductive bias and quadratic complexity concerning input sequence length. State Space Models (SSMs) like S4 and others (Hippo, Global Convolutions, liquid S4, LRU, Mega, and Mamba), have emerged to address the above issues to help handle longer sequence lengths. Mamba, while being the state-of-the-art SSM, has a stability issue when scaled to large networks for computer vision datasets. We propose SiMBA, a new architecture that introduces Einstein FFT (EinFFT) for channel modeling by specific eigenvalue computations and uses the Mamba block for sequence modeling. Extensive performance studies across image and time-series benchmarks demonstrate that SiMBA outperforms existing SSMs, bridging the performance gap with state-of-the-art transformers. Notably, SiMBA establishes itself as the new state-of-the-art SSM on ImageNet and transfer learning benchmarks such as Stanford Car and Flower as well as task learning benchmarks as well as seven time series benchmark datasets. The project page is available on this website ~\url{https://github.com/badripatro/Simba}.
Scattering Vision Transformer: Spectral Mixing Matters
Nov 20, 2023Vision transformers have gained significant attention and achieved state-of-the-art performance in various computer vision tasks, including image classification, instance segmentation, and object detection. However, challenges remain in addressing attention complexity and effectively capturing fine-grained information within images. Existing solutions often resort to down-sampling operations, such as pooling, to reduce computational cost. Unfortunately, such operations are non-invertible and can result in information loss. In this paper, we present a novel approach called Scattering Vision Transformer (SVT) to tackle these challenges. SVT incorporates a spectrally scattering network that enables the capture of intricate image details. SVT overcomes the invertibility issue associated with down-sampling operations by separating low-frequency and high-frequency components. Furthermore, SVT introduces a unique spectral gating network utilizing Einstein multiplication for token and channel mixing, effectively reducing complexity. We show that SVT achieves state-of-the-art performance on the ImageNet dataset with a significant reduction in a number of parameters and FLOPS. SVT shows 2\% improvement over LiTv2 and iFormer. SVT-H-S reaches 84.2\% top-1 accuracy, while SVT-H-B reaches 85.2\% (state-of-art for base versions) and SVT-H-L reaches 85.7\% (again state-of-art for large versions). SVT also shows comparable results in other vision tasks such as instance segmentation. SVT also outperforms other transformers in transfer learning on standard datasets such as CIFAR10, CIFAR100, Oxford Flower, and Stanford Car datasets. The project page is available on this webpage.\url{https://badripatro.github.io/svt/}.
SpectFormer: Frequency and Attention is what you need in a Vision Transformer
Apr 14, 2023

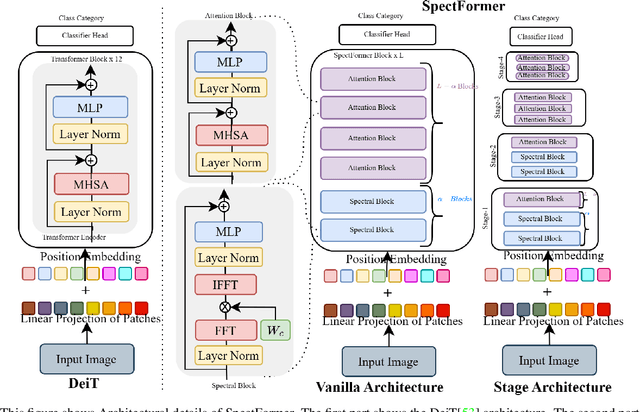
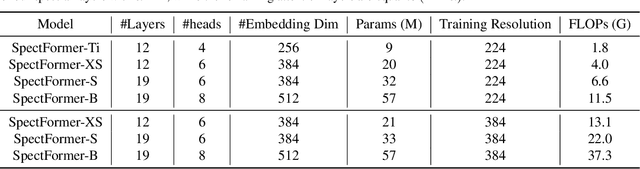
Vision transformers have been applied successfully for image recognition tasks. There have been either multi-headed self-attention based (ViT \cite{dosovitskiy2020image}, DeIT, \cite{touvron2021training}) similar to the original work in textual models or more recently based on spectral layers (Fnet\cite{lee2021fnet}, GFNet\cite{rao2021global}, AFNO\cite{guibas2021efficient}). We hypothesize that both spectral and multi-headed attention plays a major role. We investigate this hypothesis through this work and observe that indeed combining spectral and multi-headed attention layers provides a better transformer architecture. We thus propose the novel Spectformer architecture for transformers that combines spectral and multi-headed attention layers. We believe that the resulting representation allows the transformer to capture the feature representation appropriately and it yields improved performance over other transformer representations. For instance, it improves the top-1 accuracy by 2\% on ImageNet compared to both GFNet-H and LiT. SpectFormer-S reaches 84.25\% top-1 accuracy on ImageNet-1K (state of the art for small version). Further, Spectformer-L achieves 85.7\% that is the state of the art for the comparable base version of the transformers. We further ensure that we obtain reasonable results in other scenarios such as transfer learning on standard datasets such as CIFAR-10, CIFAR-100, Oxford-IIIT-flower, and Standford Car datasets. We then investigate its use in downstream tasks such of object detection and instance segmentation on the MS-COCO dataset and observe that Spectformer shows consistent performance that is comparable to the best backbones and can be further optimized and improved. Hence, we believe that combined spectral and attention layers are what are needed for vision transformers.
Efficiency 360: Efficient Vision Transformers
Feb 23, 2023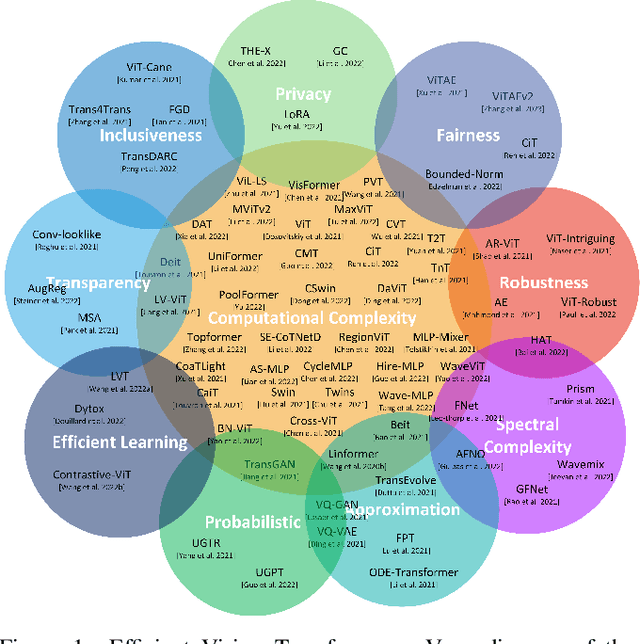
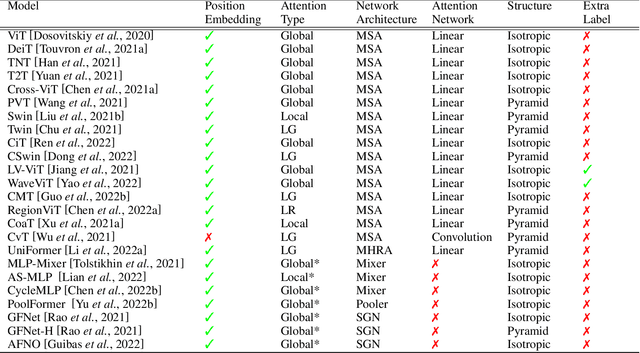
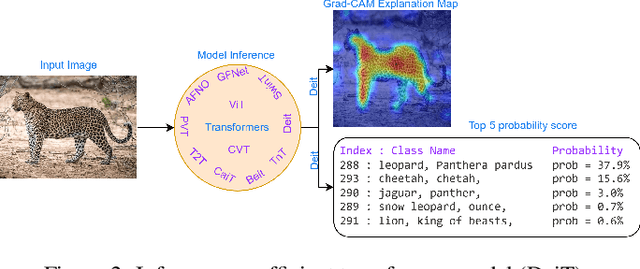
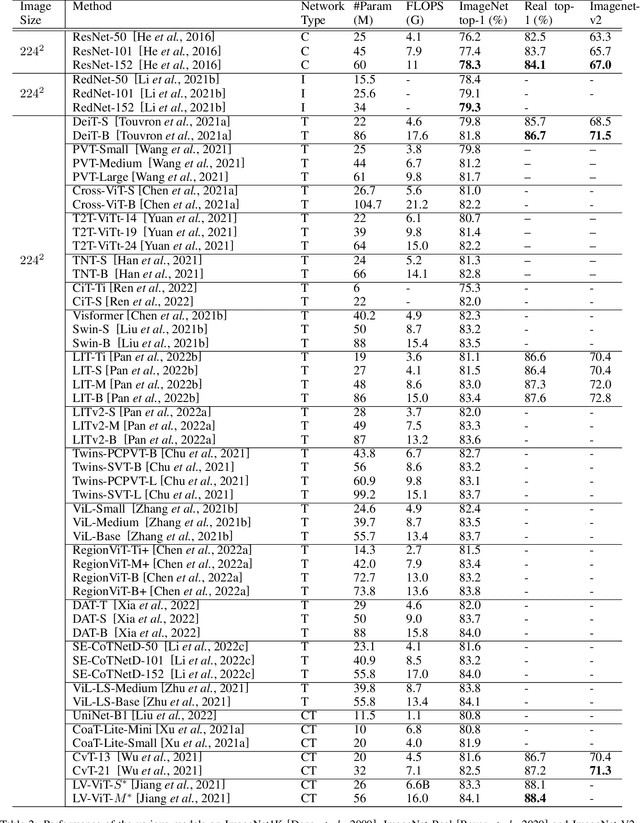
Transformers are widely used for solving tasks in natural language processing, computer vision, speech, and music domains. In this paper, we talk about the efficiency of transformers in terms of memory (the number of parameters), computation cost (number of floating points operations), and performance of models, including accuracy, the robustness of the model, and fair \& bias-free features. We mainly discuss the vision transformer for the image classification task. Our contribution is to introduce an efficient 360 framework, which includes various aspects of the vision transformer, to make it more efficient for industrial applications. By considering those applications, we categorize them into multiple dimensions such as privacy, robustness, transparency, fairness, inclusiveness, continual learning, probabilistic models, approximation, computational complexity, and spectral complexity. We compare various vision transformer models based on their performance, the number of parameters, and the number of floating point operations (FLOPs) on multiple datasets.
Barlow constrained optimization for Visual Question Answering
Mar 07, 2022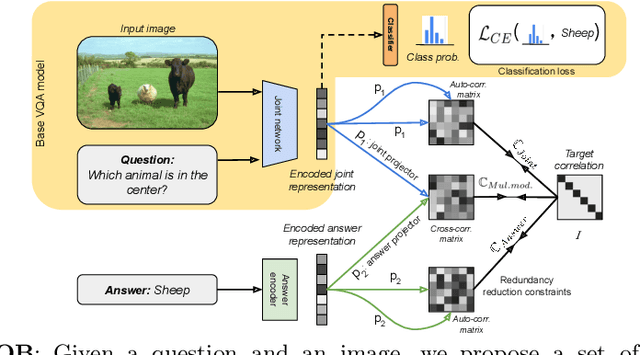
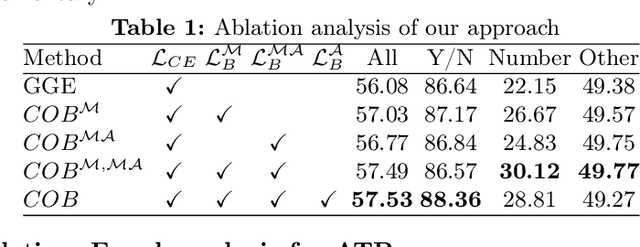
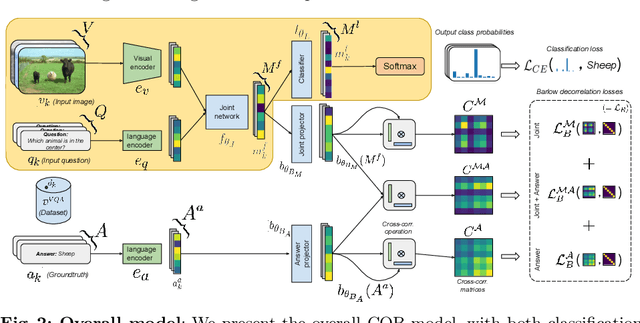
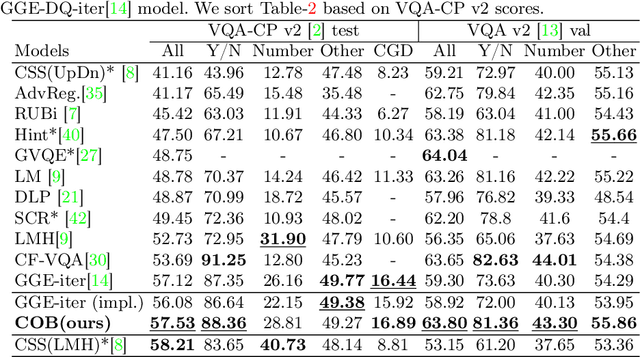
Visual question answering is a vision-and-language multimodal task, that aims at predicting answers given samples from the question and image modalities. Most recent methods focus on learning a good joint embedding space of images and questions, either by improving the interaction between these two modalities, or by making it a more discriminant space. However, how informative this joint space is, has not been well explored. In this paper, we propose a novel regularization for VQA models, Constrained Optimization using Barlow's theory (COB), that improves the information content of the joint space by minimizing the redundancy. It reduces the correlation between the learned feature components and thereby disentangles semantic concepts. Our model also aligns the joint space with the answer embedding space, where we consider the answer and image+question as two different `views' of what in essence is the same semantic information. We propose a constrained optimization policy to balance the categorical and redundancy minimization forces. When built on the state-of-the-art GGE model, the resulting model improves VQA accuracy by 1.4% and 4% on the VQA-CP v2 and VQA v2 datasets respectively. The model also exhibits better interpretability.
Do Not Forget to Attend to Uncertainty while Mitigating Catastrophic Forgetting
Feb 03, 2021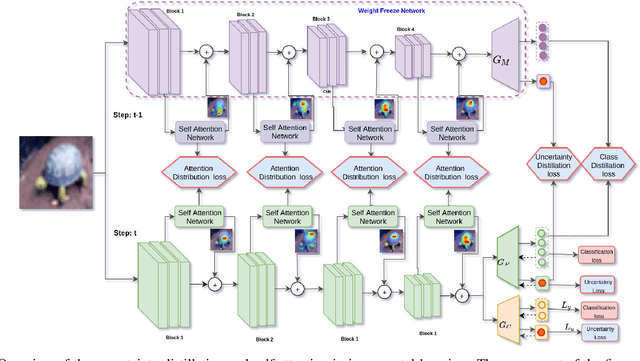

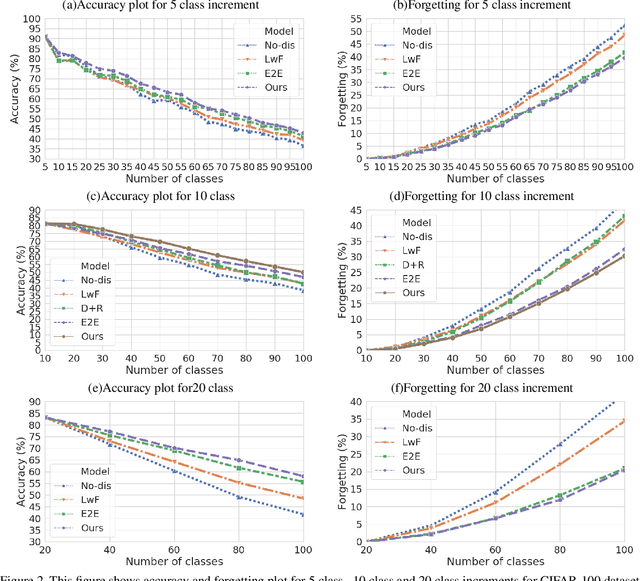

One of the major limitations of deep learning models is that they face catastrophic forgetting in an incremental learning scenario. There have been several approaches proposed to tackle the problem of incremental learning. Most of these methods are based on knowledge distillation and do not adequately utilize the information provided by older task models, such as uncertainty estimation in predictions. The predictive uncertainty provides the distributional information can be applied to mitigate catastrophic forgetting in a deep learning framework. In the proposed work, we consider a Bayesian formulation to obtain the data and model uncertainties. We also incorporate self-attention framework to address the incremental learning problem. We define distillation losses in terms of aleatoric uncertainty and self-attention. In the proposed work, we investigate different ablation analyses on these losses. Furthermore, we are able to obtain better results in terms of accuracy on standard benchmarks.
* Accepted WACV 2021
Uncertainty based Class Activation Maps for Visual Question Answering
Jan 23, 2020
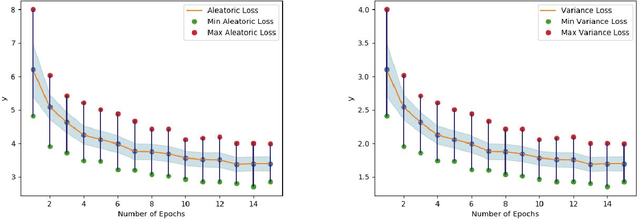
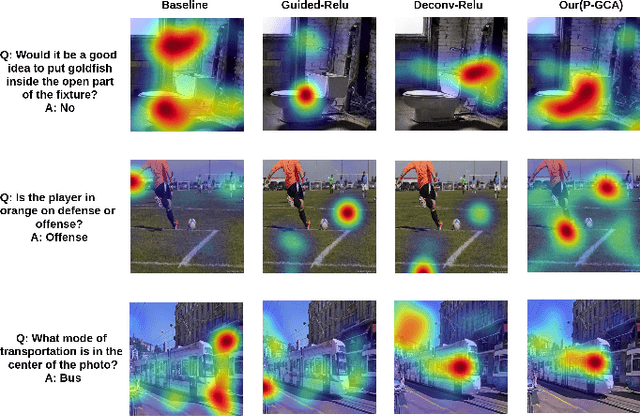

Understanding and explaining deep learning models is an imperative task. Towards this, we propose a method that obtains gradient-based certainty estimates that also provide visual attention maps. Particularly, we solve for visual question answering task. We incorporate modern probabilistic deep learning methods that we further improve by using the gradients for these estimates. These have two-fold benefits: a) improvement in obtaining the certainty estimates that correlate better with misclassified samples and b) improved attention maps that provide state-of-the-art results in terms of correlation with human attention regions. The improved attention maps result in consistent improvement for various methods for visual question answering. Therefore, the proposed technique can be thought of as a recipe for obtaining improved certainty estimates and explanations for deep learning models. We provide detailed empirical analysis for the visual question answering task on all standard benchmarks and comparison with state of the art methods.