 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNurtureNet: A Multi-task Video-based Approach for Newborn Anthropometry
May 09, 2024Malnutrition among newborns is a top public health concern in developing countries. Identification and subsequent growth monitoring are key to successful interventions. However, this is challenging in rural communities where health systems tend to be inaccessible and under-equipped, with poor adherence to protocol. Our goal is to equip health workers and public health systems with a solution for contactless newborn anthropometry in the community. We propose NurtureNet, a multi-task model that fuses visual information (a video taken with a low-cost smartphone) with tabular inputs to regress multiple anthropometry estimates including weight, length, head circumference, and chest circumference. We show that visual proxy tasks of segmentation and keypoint prediction further improve performance. We establish the efficacy of the model through several experiments and achieve a relative error of 3.9% and mean absolute error of 114.3 g for weight estimation. Model compression to 15 MB also allows offline deployment to low-cost smartphones.
FSD: Fast Self-Supervised Single RGB-D to Categorical 3D Objects
Oct 19, 2023



In this work, we address the challenging task of 3D object recognition without the reliance on real-world 3D labeled data. Our goal is to predict the 3D shape, size, and 6D pose of objects within a single RGB-D image, operating at the category level and eliminating the need for CAD models during inference. While existing self-supervised methods have made strides in this field, they often suffer from inefficiencies arising from non-end-to-end processing, reliance on separate models for different object categories, and slow surface extraction during the training of implicit reconstruction models; thus hindering both the speed and real-world applicability of the 3D recognition process. Our proposed method leverages a multi-stage training pipeline, designed to efficiently transfer synthetic performance to the real-world domain. This approach is achieved through a combination of 2D and 3D supervised losses during the synthetic domain training, followed by the incorporation of 2D supervised and 3D self-supervised losses on real-world data in two additional learning stages. By adopting this comprehensive strategy, our method successfully overcomes the aforementioned limitations and outperforms existing self-supervised 6D pose and size estimation baselines on the NOCS test-set with a 16.4% absolute improvement in mAP for 6D pose estimation while running in near real-time at 5 Hz.
Lifelong Wandering: A realistic few-shot online continual learning setting
Jun 16, 2022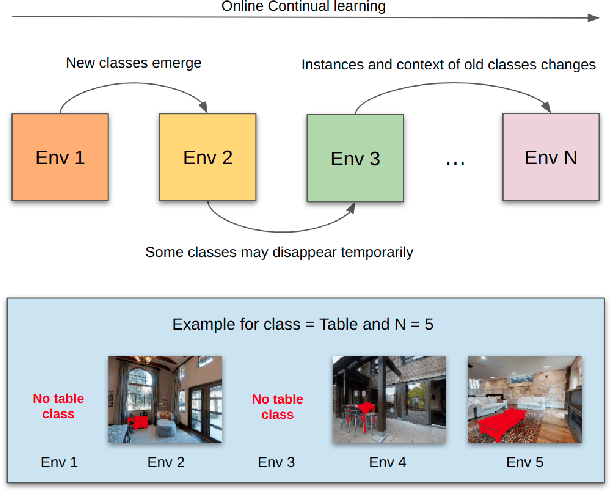
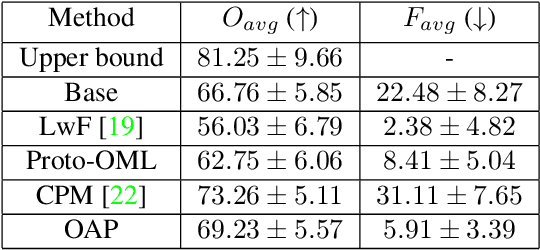
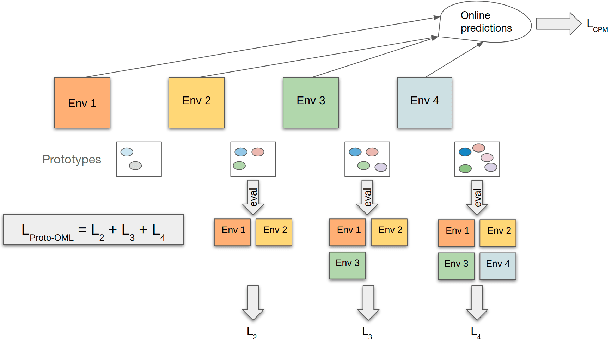
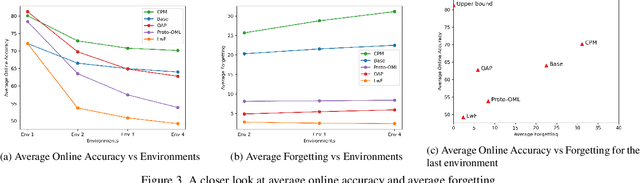
Online few-shot learning describes a setting where models are trained and evaluated on a stream of data while learning emerging classes. While prior work in this setting has achieved very promising performance on instance classification when learning from data-streams composed of a single indoor environment, we propose to extend this setting to consider object classification on a series of several indoor environments, which is likely to occur in applications such as robotics. Importantly, our setting, which we refer to as online few-shot continual learning, injects the well-studied issue of catastrophic forgetting into the few-shot online learning paradigm. In this work, we benchmark several existing methods and adapted baselines within our setting, and show there exists a trade-off between catastrophic forgetting and online performance. Our findings motivate the need for future work in this setting, which can achieve better online performance without catastrophic forgetting.
Uncertainty based Class Activation Maps for Visual Question Answering
Jan 23, 2020
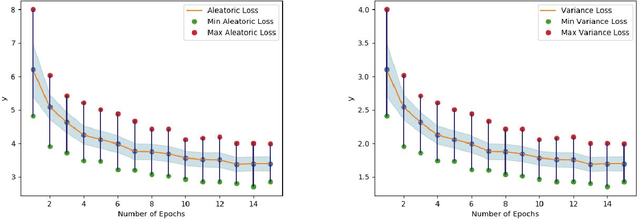
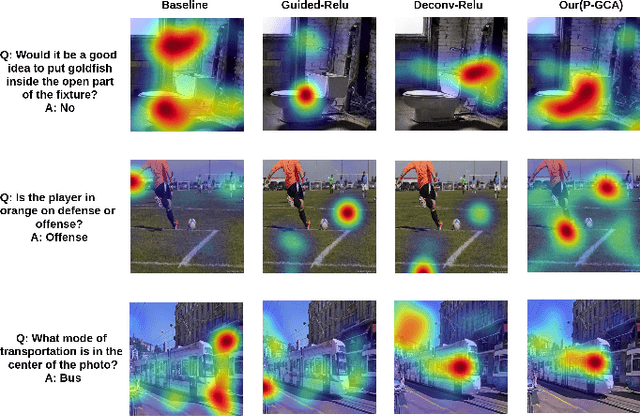

Understanding and explaining deep learning models is an imperative task. Towards this, we propose a method that obtains gradient-based certainty estimates that also provide visual attention maps. Particularly, we solve for visual question answering task. We incorporate modern probabilistic deep learning methods that we further improve by using the gradients for these estimates. These have two-fold benefits: a) improvement in obtaining the certainty estimates that correlate better with misclassified samples and b) improved attention maps that provide state-of-the-art results in terms of correlation with human attention regions. The improved attention maps result in consistent improvement for various methods for visual question answering. Therefore, the proposed technique can be thought of as a recipe for obtaining improved certainty estimates and explanations for deep learning models. We provide detailed empirical analysis for the visual question answering task on all standard benchmarks and comparison with state of the art methods.
U-CAM: Visual Explanation using Uncertainty based Class Activation Maps
Sep 16, 2019
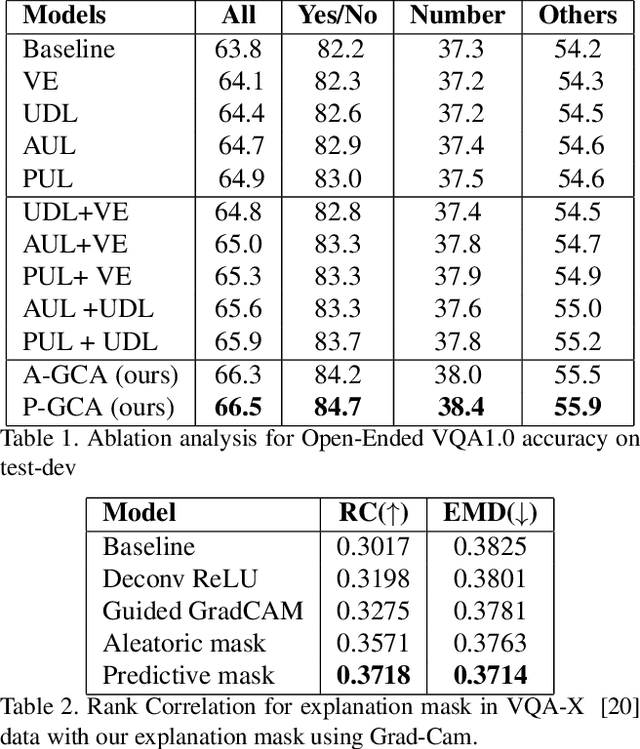
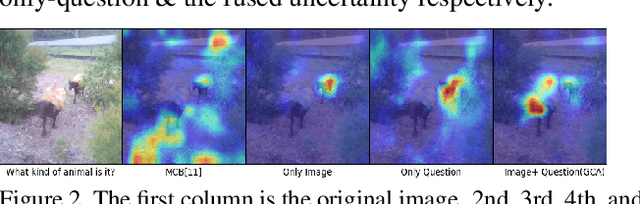
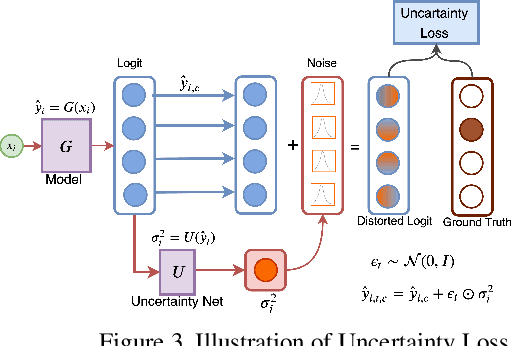
Understanding and explaining deep learning models is an imperative task. Towards this, we propose a method that obtains gradient-based certainty estimates that also provide visual attention maps. Particularly, we solve for visual question answering task. We incorporate modern probabilistic deep learning methods that we further improve by using the gradients for these estimates. These have two-fold benefits: a) improvement in obtaining the certainty estimates that correlate better with misclassified samples and b) improved attention maps that provide state-of-the-art results in terms of correlation with human attention regions. The improved attention maps result in consistent improvement for various methods for visual question answering. Therefore, the proposed technique can be thought of as a recipe for obtaining improved certainty estimates and explanation for deep learning models. We provide detailed empirical analysis for the visual question answering task on all standard benchmarks and comparison with state of the art methods.