 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNurtureNet: A Multi-task Video-based Approach for Newborn Anthropometry
May 09, 2024Malnutrition among newborns is a top public health concern in developing countries. Identification and subsequent growth monitoring are key to successful interventions. However, this is challenging in rural communities where health systems tend to be inaccessible and under-equipped, with poor adherence to protocol. Our goal is to equip health workers and public health systems with a solution for contactless newborn anthropometry in the community. We propose NurtureNet, a multi-task model that fuses visual information (a video taken with a low-cost smartphone) with tabular inputs to regress multiple anthropometry estimates including weight, length, head circumference, and chest circumference. We show that visual proxy tasks of segmentation and keypoint prediction further improve performance. We establish the efficacy of the model through several experiments and achieve a relative error of 3.9% and mean absolute error of 114.3 g for weight estimation. Model compression to 15 MB also allows offline deployment to low-cost smartphones.
COBRA: Contrastive Bi-Modal Representation Algorithm
May 24, 2020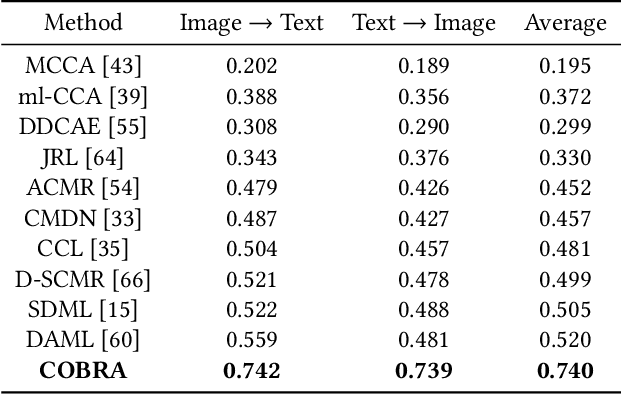
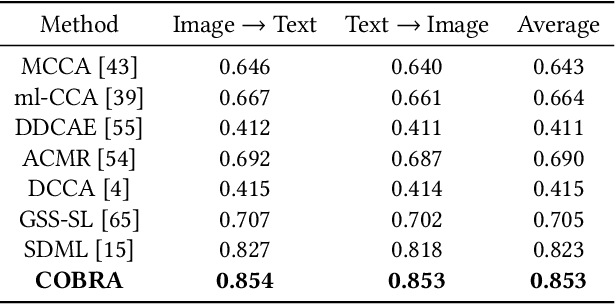
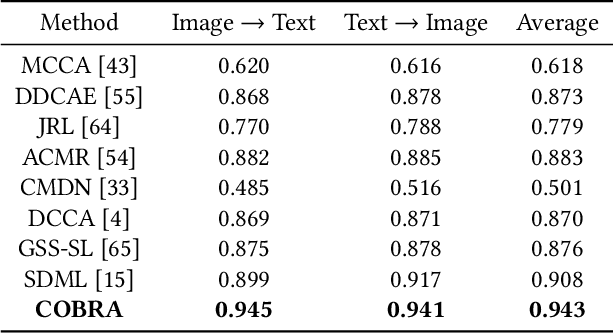
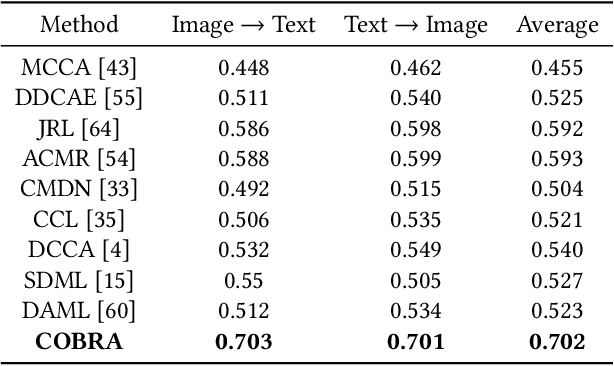
There are a wide range of applications that involve multi-modal data, such as cross-modal retrieval, visual question-answering, and image captioning. Such applications are primarily dependent on aligned distributions of the different constituent modalities. Existing approaches generate latent embeddings for each modality in a joint fashion by representing them in a common manifold. However these joint embedding spaces fail to sufficiently reduce the modality gap, which affects the performance in downstream tasks. We hypothesize that these embeddings retain the intra-class relationships but are unable to preserve the inter-class dynamics. In this paper, we present a novel framework COBRA that aims to train two modalities (image and text) in a joint fashion inspired by the Contrastive Predictive Coding (CPC) and Noise Contrastive Estimation (NCE) paradigms which preserve both inter and intra-class relationships. We empirically show that this framework reduces the modality gap significantly and generates a robust and task agnostic joint-embedding space. We outperform existing work on four diverse downstream tasks spanning across seven benchmark cross-modal datasets.