 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty and Energy based Loss Guided Semi-Supervised Semantic Segmentation
Jan 03, 2025Semi-supervised (SS) semantic segmentation exploits both labeled and unlabeled images to overcome tedious and costly pixel-level annotation problems. Pseudolabel supervision is one of the core approaches of training networks with both pseudo labels and ground-truth labels. This work uses aleatoric or data uncertainty and energy based modeling in intersection-union pseudo supervised network.The aleatoric uncertainty is modeling the inherent noise variations of the data in a network with two predictive branches. The per-pixel variance parameter obtained from the network gives a quantitative idea about the data uncertainty. Moreover, energy-based loss realizes the potential of generative modeling on the downstream SS segmentation task. The aleatoric and energy loss are applied in conjunction with pseudo-intersection labels, pseudo-union labels, and ground-truth on the respective network branch. The comparative analysis with state-of-the-art methods has shown improvement in performance metrics.
Prb-GAN: A Probabilistic Framework for GAN Modelling
Jul 12, 2021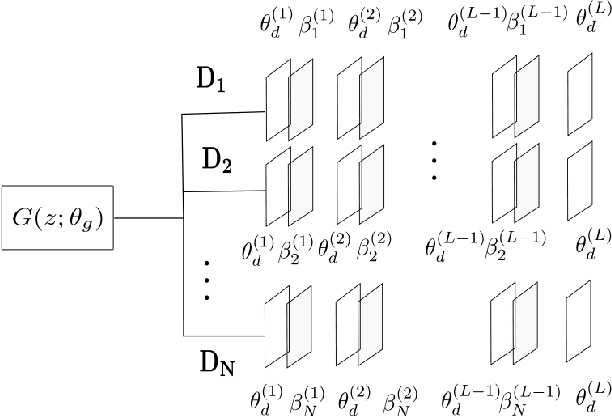
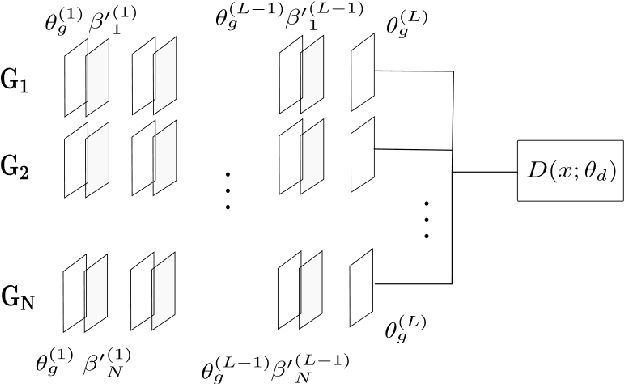
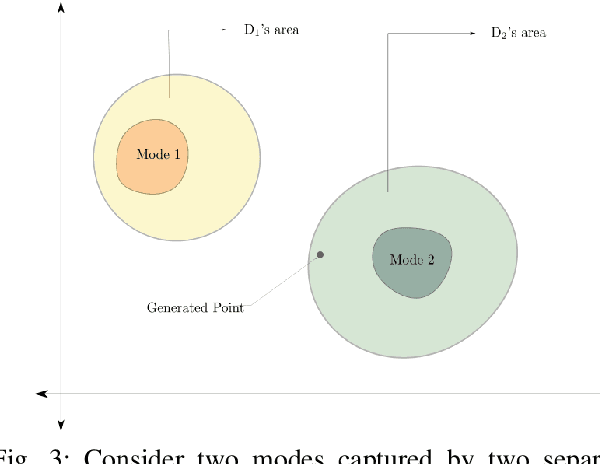
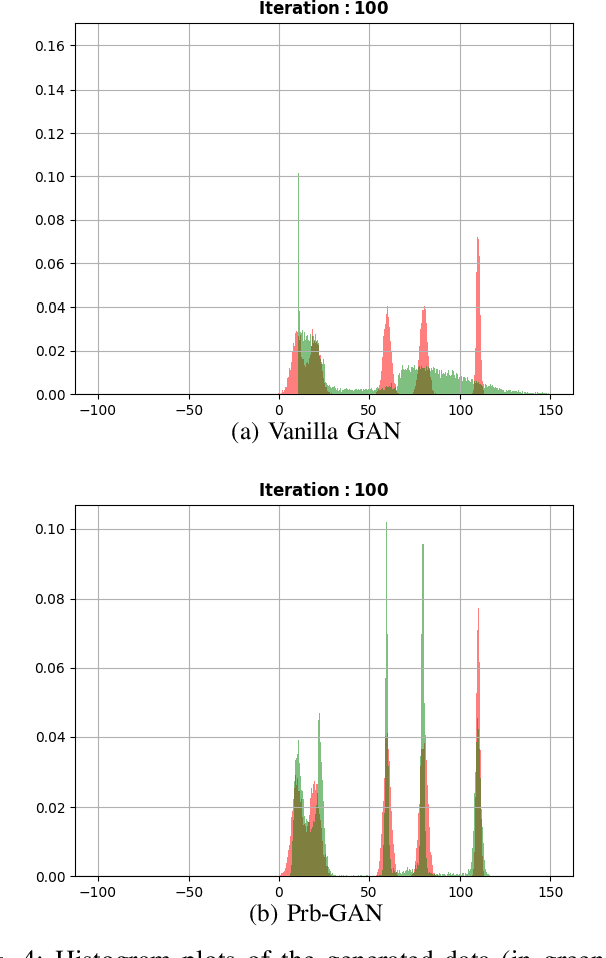
Generative adversarial networks (GANs) are very popular to generate realistic images, but they often suffer from the training instability issues and the phenomenon of mode loss. In order to attain greater diversity in GAN synthesized data, it is critical to solving the problem of mode loss. Our work explores probabilistic approaches to GAN modelling that could allow us to tackle these issues. We present Prb-GANs, a new variation that uses dropout to create a distribution over the network parameters with the posterior learnt using variational inference. We describe theoretically and validate experimentally using simple and complex datasets the benefits of such an approach. We look into further improvements using the concept of uncertainty measures. Through a set of further modifications to the loss functions for each network of the GAN, we are able to get results that show the improvement of GAN performance. Our methods are extremely simple and require very little modification to existing GAN architecture.
Deep Bayesian Network for Visual Question Generation
Jan 23, 2020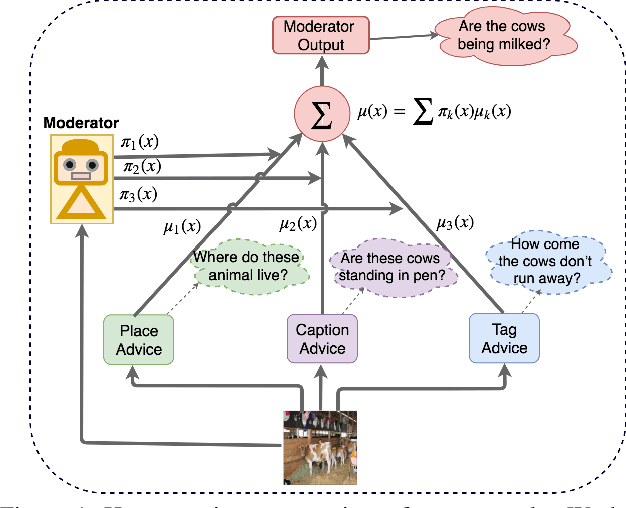
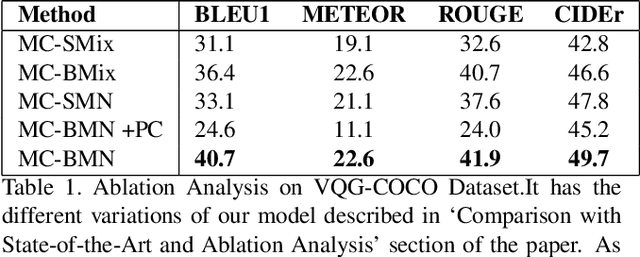
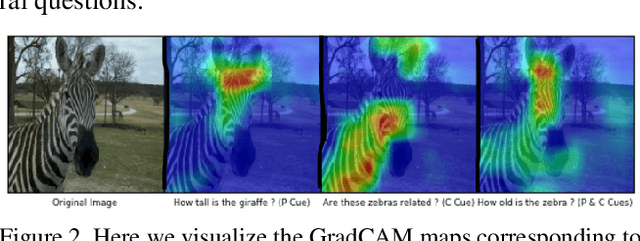
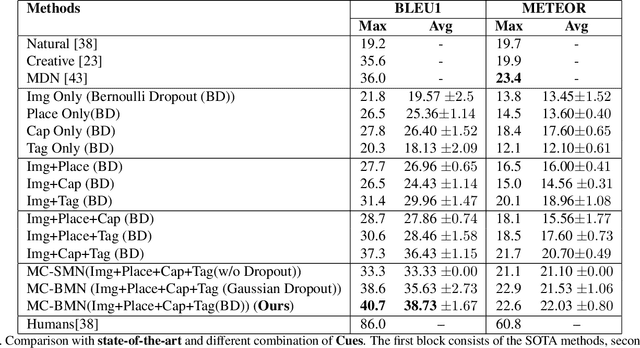
Generating natural questions from an image is a semantic task that requires using vision and language modalities to learn multimodal representations. Images can have multiple visual and language cues such as places, captions, and tags. In this paper, we propose a principled deep Bayesian learning framework that combines these cues to produce natural questions. We observe that with the addition of more cues and by minimizing uncertainty in the among cues, the Bayesian network becomes more confident. We propose a Minimizing Uncertainty of Mixture of Cues (MUMC), that minimizes uncertainty present in a mixture of cues experts for generating probabilistic questions. This is a Bayesian framework and the results show a remarkable similarity to natural questions as validated by a human study. We observe that with the addition of more cues and by minimizing uncertainty among the cues, the Bayesian framework becomes more confident. Ablation studies of our model indicate that a subset of cues is inferior at this task and hence the principled fusion of cues is preferred. Further, we observe that the proposed approach substantially improves over state-of-the-art benchmarks on the quantitative metrics (BLEU-n, METEOR, ROUGE, and CIDEr). Here we provide project link for Deep Bayesian VQG \url{https://delta-lab-iitk.github.io/BVQG/}
Revisiting Paraphrase Question Generator using Pairwise Discriminator
Jan 04, 2020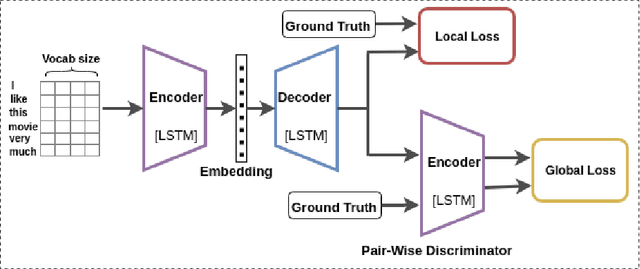
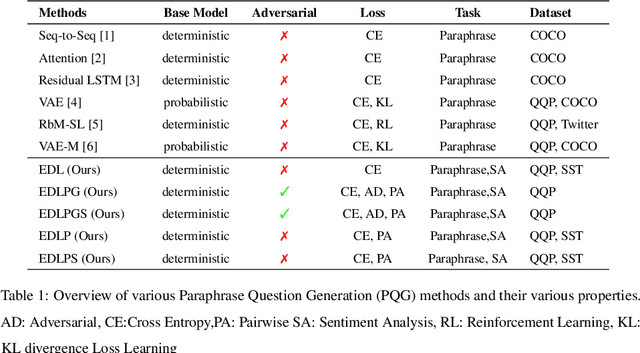
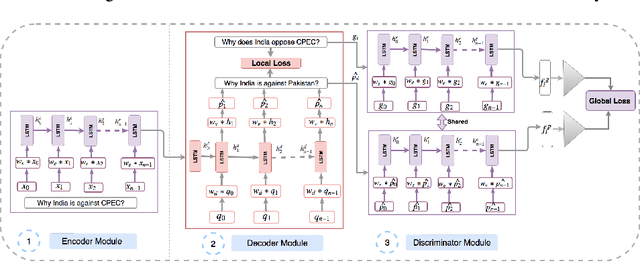
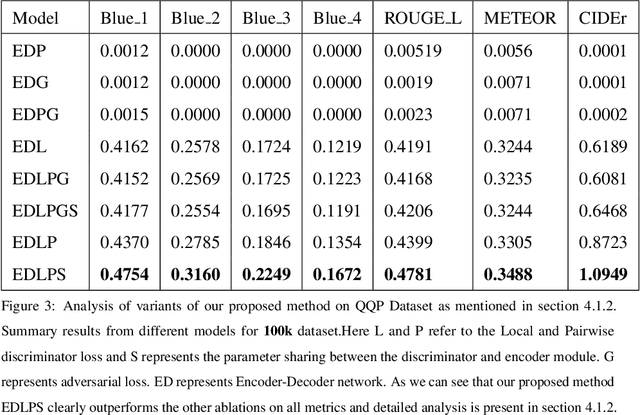
In this paper, we propose a method for obtaining sentence-level embeddings. While the problem of securing word-level embeddings is very well studied, we propose a novel method for obtaining sentence-level embeddings. This is obtained by a simple method in the context of solving the paraphrase generation task. If we use a sequential encoder-decoder model for generating paraphrase, we would like the generated paraphrase to be semantically close to the original sentence. One way to ensure this is by adding constraints for true paraphrase embeddings to be close and unrelated paraphrase candidate sentence embeddings to be far. This is ensured by using a sequential pair-wise discriminator that shares weights with the encoder that is trained with a suitable loss function. Our loss function penalizes paraphrase sentence embedding distances from being too large. This loss is used in combination with a sequential encoder-decoder network. We also validated our method by evaluating the obtained embeddings for a sentiment analysis task. The proposed method results in semantic embeddings and outperforms the state-of-the-art on the paraphrase generation and sentiment analysis task on standard datasets. These results are also shown to be statistically significant.
Multimodal Differential Network for Visual Question Generation
Aug 12, 2018
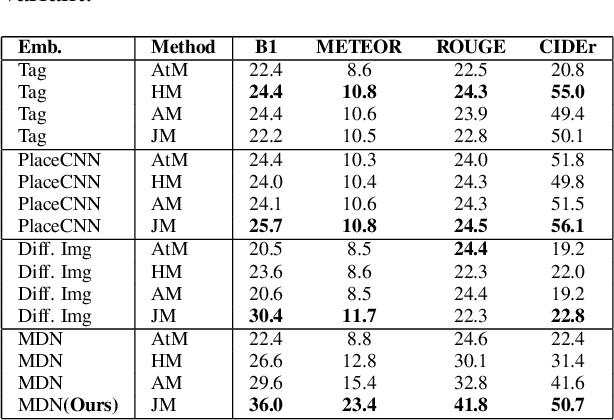
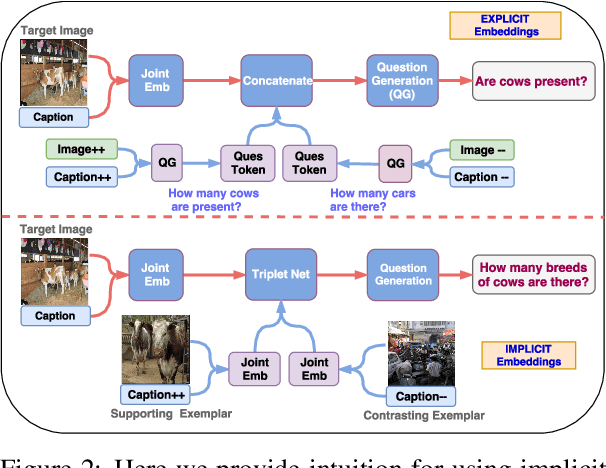
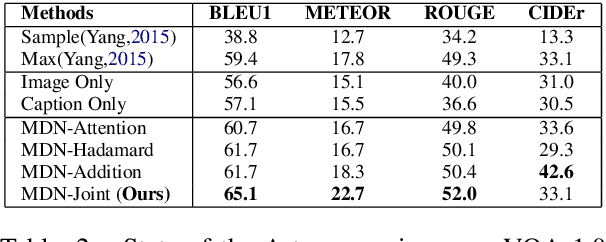
Generating natural questions from an image is a semantic task that requires using visual and language modality to learn multimodal representations. Images can have multiple visual and language contexts that are relevant for generating questions namely places, captions, and tags. In this paper, we propose the use of exemplars for obtaining the relevant context. We obtain this by using a Multimodal Differential Network to produce natural and engaging questions. The generated questions show a remarkable similarity to the natural questions as validated by a human study. Further, we observe that the proposed approach substantially improves over state-of-the-art benchmarks on the quantitative metrics (BLEU, METEOR, ROUGE, and CIDEr).
Learning Semantic Sentence Embeddings using Pair-wise Discriminator
Jul 02, 2018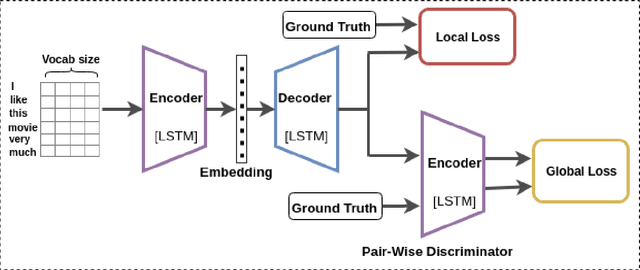
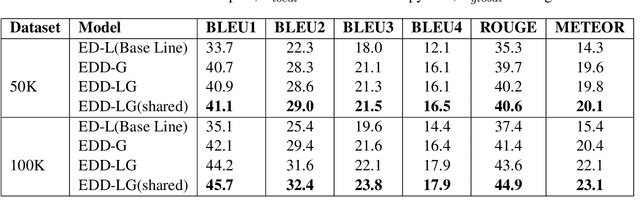
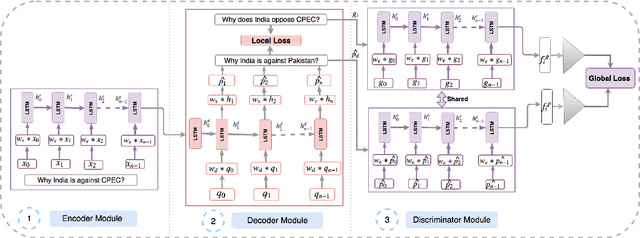
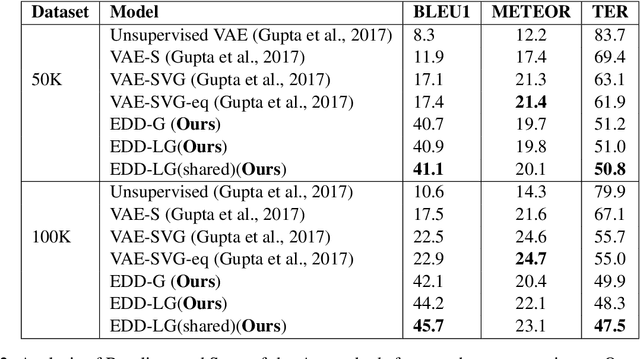
In this paper, we propose a method for obtaining sentence-level embeddings. While the problem of securing word-level embeddings is very well studied, we propose a novel method for obtaining sentence-level embeddings. This is obtained by a simple method in the context of solving the paraphrase generation task. If we use a sequential encoder-decoder model for generating paraphrase, we would like the generated paraphrase to be semantically close to the original sentence. One way to ensure this is by adding constraints for true paraphrase embeddings to be close and unrelated paraphrase candidate sentence embeddings to be far. This is ensured by using a sequential pair-wise discriminator that shares weights with the encoder that is trained with a suitable loss function. Our loss function penalizes paraphrase sentence embedding distances from being too large. This loss is used in combination with a sequential encoder-decoder network. We also validated our method by evaluating the obtained embeddings for a sentiment analysis task. The proposed method results in semantic embeddings and outperforms the state-of-the-art on the paraphrase generation and sentiment analysis task on standard datasets. These results are also shown to be statistically significant.