 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Learning with a Multi-Task Latent Space Objective
Feb 05, 2026Self-supervised learning (SSL) methods based on Siamese networks learn visual representations by aligning different views of the same image. The multi-crop strategy, which incorporates small local crops to global ones, enhances many SSL frameworks but causes instability in predictor-based architectures such as BYOL, SimSiam, and MoCo v3. We trace this failure to the shared predictor used across all views and demonstrate that assigning a separate predictor to each view type stabilizes multi-crop training, resulting in significant performance gains. Extending this idea, we treat each spatial transformation as a distinct alignment task and add cutout views, where part of the image is masked before encoding. This yields a simple multi-task formulation of asymmetric Siamese SSL that combines global, local, and masked views into a single framework. The approach is stable, generally applicable across backbones, and consistently improves the performance of ResNet and ViT models on ImageNet.
Unsupervised Parameter Efficient Source-free Post-pretraining
Feb 28, 2025



Following the success in NLP, the best vision models are now in the billion parameter ranges. Adapting these large models to a target distribution has become computationally and economically prohibitive. Addressing this challenge, we introduce UpStep, an Unsupervised Parameter-efficient Source-free post-pretraining approach, designed to efficiently adapt a base model from a source domain to a target domain: i) we design a self-supervised training scheme to adapt a pretrained model on an unlabeled target domain in a setting where source domain data is unavailable. Such source-free setting comes with the risk of catastrophic forgetting, hence, ii) we propose center vector regularization (CVR), a set of auxiliary operations that minimize catastrophic forgetting and additionally reduces the computational cost by skipping backpropagation in 50\% of the training iterations. Finally iii) we perform this adaptation process in a parameter-efficient way by adapting the pretrained model through low-rank adaptation methods, resulting in a fraction of parameters to optimize. We utilize various general backbone architectures, both supervised and unsupervised, trained on Imagenet as our base model and adapt them to a diverse set of eight target domains demonstrating the adaptability and generalizability of our proposed approach.
Maximally Separated Active Learning
Nov 26, 2024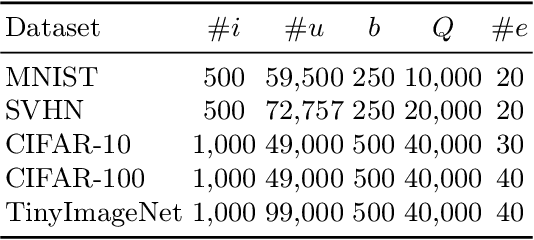
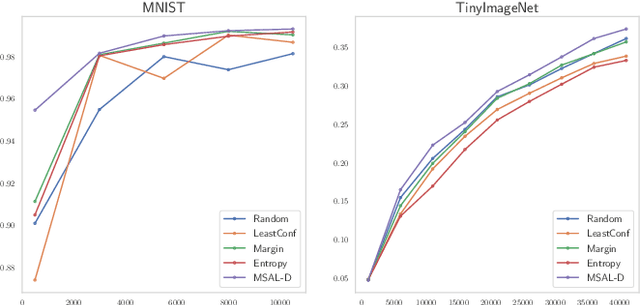
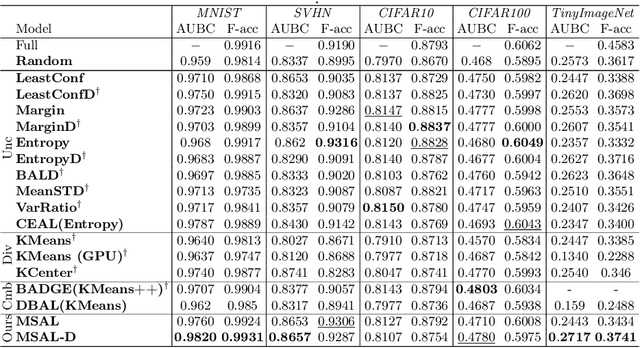
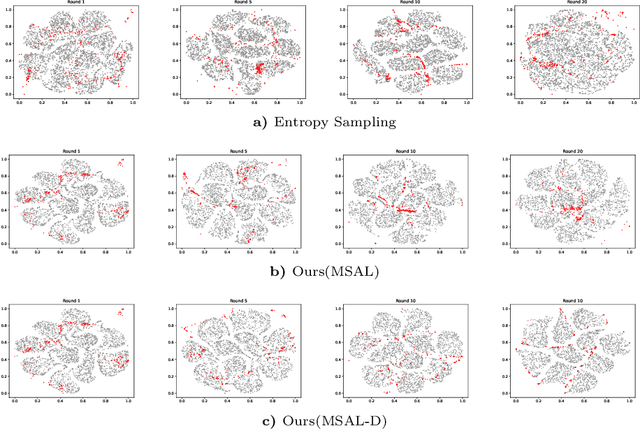
Active Learning aims to optimize performance while minimizing annotation costs by selecting the most informative samples from an unlabelled pool. Traditional uncertainty sampling often leads to sampling bias by choosing similar uncertain samples. We propose an active learning method that utilizes fixed equiangular hyperspherical points as class prototypes, ensuring consistent inter-class separation and robust feature representations. Our approach introduces Maximally Separated Active Learning (MSAL) for uncertainty sampling and a combined strategy (MSAL-D) for incorporating diversity. This method eliminates the need for costly clustering steps, while maintaining diversity through hyperspherical uniformity. We demonstrate strong performance over existing active learning techniques across five benchmark datasets, highlighting the method's effectiveness and integration ease. The code is available on GitHub.
Analysis of Spatial augmentation in Self-supervised models in the purview of training and test distributions
Sep 26, 2024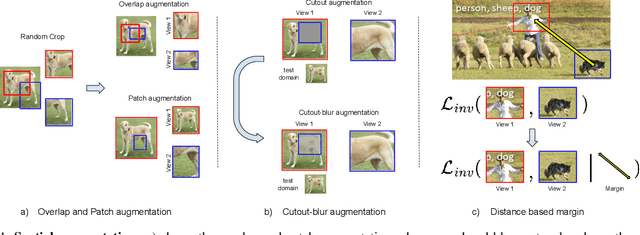
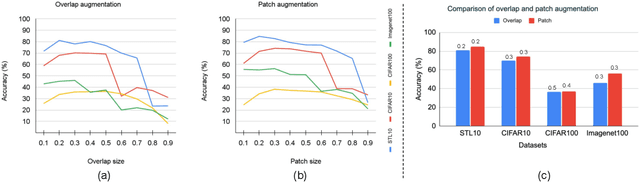
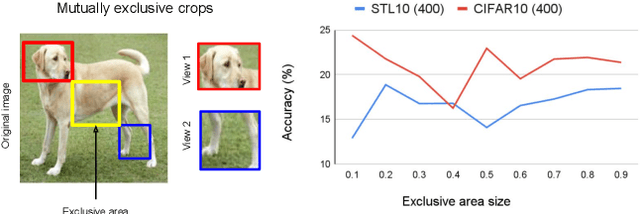
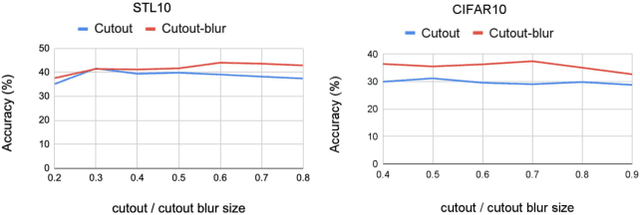
In this paper, we present an empirical study of typical spatial augmentation techniques used in self-supervised representation learning methods (both contrastive and non-contrastive), namely random crop and cutout. Our contributions are: (a) we dissociate random cropping into two separate augmentations, overlap and patch, and provide a detailed analysis on the effect of area of overlap and patch size to the accuracy on down stream tasks. (b) We offer an insight into why cutout augmentation does not learn good representation, as reported in earlier literature. Finally, based on these analysis, (c) we propose a distance-based margin to the invariance loss for learning scene-centric representations for the downstream task on object-centric distribution, showing that as simple as a margin proportional to the pixel distance between the two spatial views in the scence-centric images can improve the learned representation. Our study furthers the understanding of the spatial augmentations, and the effect of the domain-gap between the training augmentations and the test distribution.
Decentralized Safe and Scalable Multi-Agent Control under Limited Actuation
Sep 15, 2024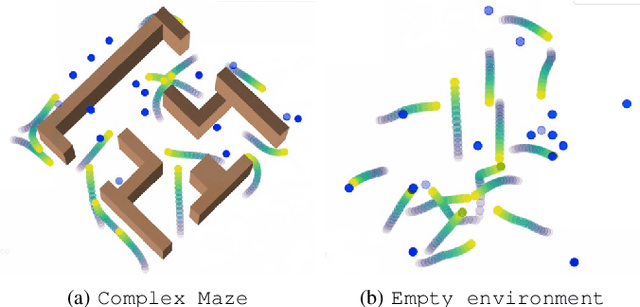
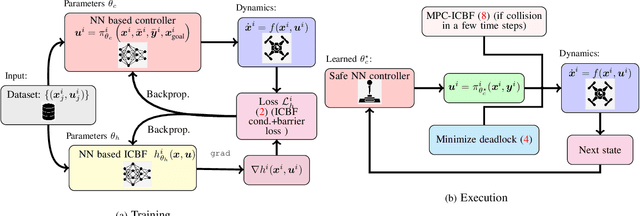
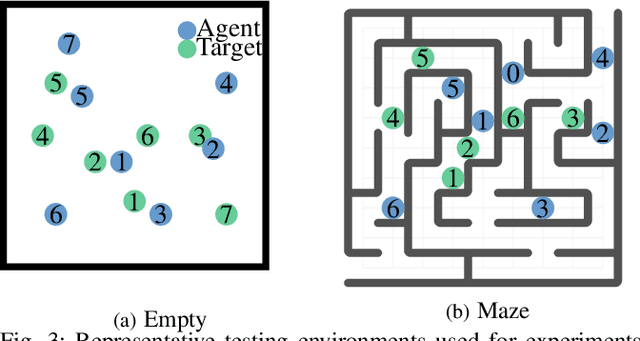
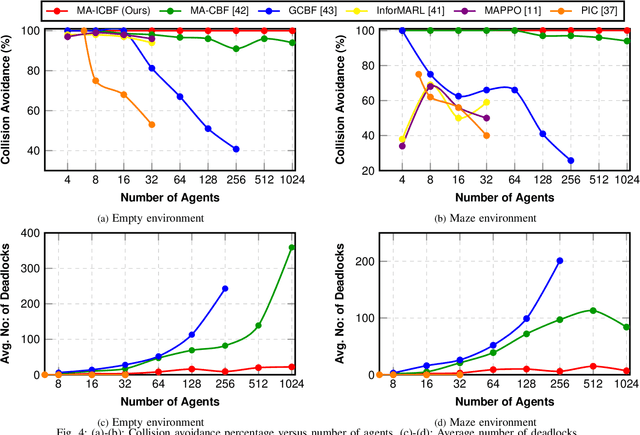
To deploy safe and agile robots in cluttered environments, there is a need to develop fully decentralized controllers that guarantee safety, respect actuation limits, prevent deadlocks, and scale to thousands of agents. Current approaches fall short of meeting all these goals: optimization-based methods ensure safety but lack scalability, while learning-based methods scale but do not guarantee safety. We propose a novel algorithm to achieve safe and scalable control for multiple agents under limited actuation. Specifically, our approach includes: $(i)$ learning a decentralized neural Integral Control Barrier function (neural ICBF) for scalable, input-constrained control, $(ii)$ embedding a lightweight decentralized Model Predictive Control-based Integral Control Barrier Function (MPC-ICBF) into the neural network policy to ensure safety while maintaining scalability, and $(iii)$ introducing a novel method to minimize deadlocks based on gradient-based optimization techniques from machine learning to address local minima in deadlocks. Our numerical simulations show that this approach outperforms state-of-the-art multi-agent control algorithms in terms of safety, input constraint satisfaction, and minimizing deadlocks. Additionally, we demonstrate strong generalization across scenarios with varying agent counts, scaling up to 1000 agents.
Strategic Pseudo-Goal Perturbation for Deadlock-Free Multi-Agent Navigation in Social Mini-Games
Jul 25, 2024This work introduces a Strategic Pseudo-Goal Perturbation (SPGP) technique, a novel approach to resolve deadlock situations in multi-agent navigation scenarios. Leveraging the robust framework of Safety Barrier Certificates, our method integrates a strategic perturbation mechanism that guides agents through social mini-games where deadlock and collision occur frequently. The method adopts a strategic calculation process where agents, upon encountering a deadlock select a pseudo goal within a predefined radius around the current position to resolve the deadlock among agents. The calculation is based on controlled strategic algorithm, ensuring that deviation towards pseudo-goal is both purposeful and effective in resolution of deadlock. Once the agent reaches the pseudo goal, it resumes the path towards the original goal, thereby enhancing navigational efficiency and safety. Experimental results demonstrates SPGP's efficacy in reducing deadlock instances and improving overall system throughput in variety of multi-agent navigation scenarios.
PV-S3: Advancing Automatic Photovoltaic Defect Detection using Semi-Supervised Semantic Segmentation of Electroluminescence Images
Apr 21, 2024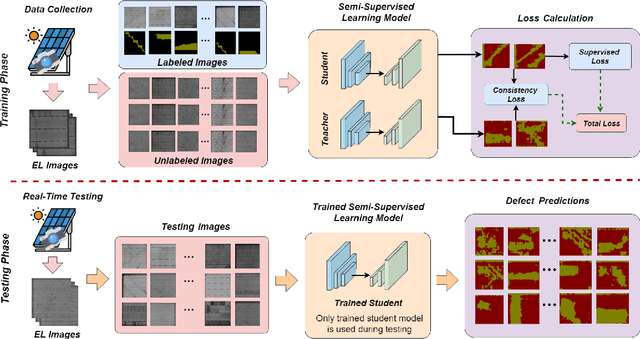
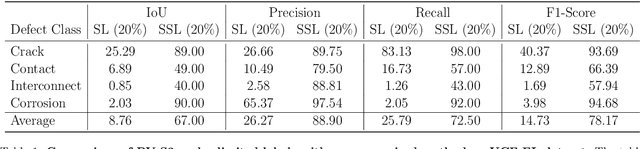
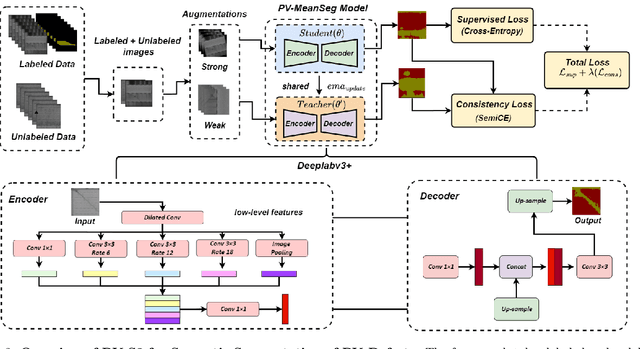
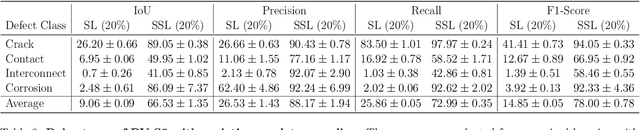
Photovoltaic (PV) systems allow us to tap into all abundant solar energy, however they require regular maintenance for high efficiency and to prevent degradation. Traditional manual health check, using Electroluminescence (EL) imaging, is expensive and logistically challenging making automated defect detection essential. Current automation approaches require extensive manual expert labeling, which is time-consuming, expensive, and prone to errors. We propose PV-S3 (Photovoltaic-Semi Supervised Segmentation), a Semi-Supervised Learning approach for semantic segmentation of defects in EL images that reduces reliance on extensive labeling. PV-S3 is a Deep learning model trained using a few labeled images along with numerous unlabeled images. We introduce a novel Semi Cross-Entropy loss function to train PV-S3 which addresses the challenges specific to automated PV defect detection, such as diverse defect types and class imbalance. We evaluate PV-S3 on multiple datasets and demonstrate its effectiveness and adaptability. With merely 20% labeled samples, we achieve an absolute improvement of 9.7% in IoU, 29.9% in Precision, 12.75% in Recall, and 20.42% in F1-Score over prior state-of-the-art supervised method (which uses 100% labeled samples) on UCF-EL dataset (largest dataset available for semantic segmentation of EL images) showing improvement in performance while reducing the annotation costs by 80%.
The Common Stability Mechanism behind most Self-Supervised Learning Approaches
Feb 22, 2024



Last couple of years have witnessed a tremendous progress in self-supervised learning (SSL), the success of which can be attributed to the introduction of useful inductive biases in the learning process to learn meaningful visual representations while avoiding collapse. These inductive biases and constraints manifest themselves in the form of different optimization formulations in the SSL techniques, e.g. by utilizing negative examples in a contrastive formulation, or exponential moving average and predictor in BYOL and SimSiam. In this paper, we provide a framework to explain the stability mechanism of these different SSL techniques: i) we discuss the working mechanism of contrastive techniques like SimCLR, non-contrastive techniques like BYOL, SWAV, SimSiam, Barlow Twins, and DINO; ii) we provide an argument that despite different formulations these methods implicitly optimize a similar objective function, i.e. minimizing the magnitude of the expected representation over all data samples, or the mean of the data distribution, while maximizing the magnitude of the expected representation of individual samples over different data augmentations; iii) we provide mathematical and empirical evidence to support our framework. We formulate different hypotheses and test them using the Imagenet100 dataset.
Weakly Supervised Detection of Pheochromocytomas and Paragangliomas in CT
Feb 12, 2024Pheochromocytomas and Paragangliomas (PPGLs) are rare adrenal and extra-adrenal tumors which have the potential to metastasize. For the management of patients with PPGLs, CT is the preferred modality of choice for precise localization and estimation of their progression. However, due to the myriad variations in size, morphology, and appearance of the tumors in different anatomical regions, radiologists are posed with the challenge of accurate detection of PPGLs. Since clinicians also need to routinely measure their size and track their changes over time across patient visits, manual demarcation of PPGLs is quite a time-consuming and cumbersome process. To ameliorate the manual effort spent for this task, we propose an automated method to detect PPGLs in CT studies via a proxy segmentation task. As only weak annotations for PPGLs in the form of prospectively marked 2D bounding boxes on an axial slice were available, we extended these 2D boxes into weak 3D annotations and trained a 3D full-resolution nnUNet model to directly segment PPGLs. We evaluated our approach on a dataset consisting of chest-abdomen-pelvis CTs of 255 patients with confirmed PPGLs. We obtained a precision of 70% and sensitivity of 64.1% with our proposed approach when tested on 53 CT studies. Our findings highlight the promising nature of detecting PPGLs via segmentation, and furthers the state-of-the-art in this exciting yet challenging area of rare cancer management.
Barlow constrained optimization for Visual Question Answering
Mar 07, 2022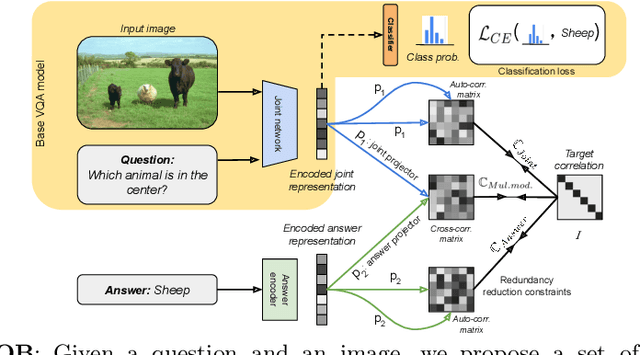
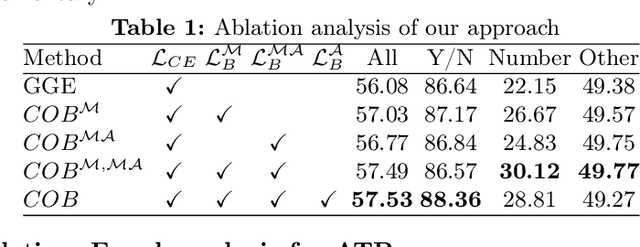
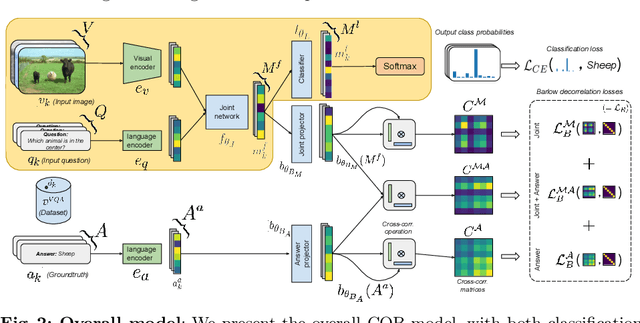
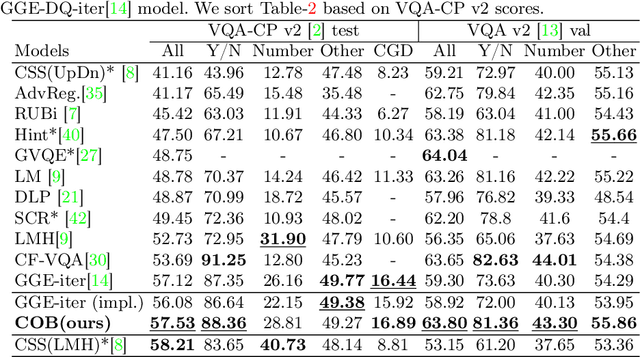
Visual question answering is a vision-and-language multimodal task, that aims at predicting answers given samples from the question and image modalities. Most recent methods focus on learning a good joint embedding space of images and questions, either by improving the interaction between these two modalities, or by making it a more discriminant space. However, how informative this joint space is, has not been well explored. In this paper, we propose a novel regularization for VQA models, Constrained Optimization using Barlow's theory (COB), that improves the information content of the joint space by minimizing the redundancy. It reduces the correlation between the learned feature components and thereby disentangles semantic concepts. Our model also aligns the joint space with the answer embedding space, where we consider the answer and image+question as two different `views' of what in essence is the same semantic information. We propose a constrained optimization policy to balance the categorical and redundancy minimization forces. When built on the state-of-the-art GGE model, the resulting model improves VQA accuracy by 1.4% and 4% on the VQA-CP v2 and VQA v2 datasets respectively. The model also exhibits better interpretability.