 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentially Private Synthetic High-dimensional Tabular Stream
Aug 31, 2024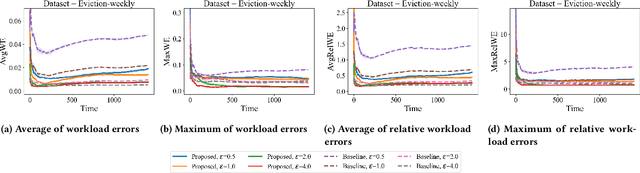
While differentially private synthetic data generation has been explored extensively in the literature, how to update this data in the future if the underlying private data changes is much less understood. We propose an algorithmic framework for streaming data that generates multiple synthetic datasets over time, tracking changes in the underlying private data. Our algorithm satisfies differential privacy for the entire input stream (continual differential privacy) and can be used for high-dimensional tabular data. Furthermore, we show the utility of our method via experiments on real-world datasets. The proposed algorithm builds upon a popular select, measure, fit, and iterate paradigm (used by offline synthetic data generation algorithms) and private counters for streams.
Strategic Pseudo-Goal Perturbation for Deadlock-Free Multi-Agent Navigation in Social Mini-Games
Jul 25, 2024This work introduces a Strategic Pseudo-Goal Perturbation (SPGP) technique, a novel approach to resolve deadlock situations in multi-agent navigation scenarios. Leveraging the robust framework of Safety Barrier Certificates, our method integrates a strategic perturbation mechanism that guides agents through social mini-games where deadlock and collision occur frequently. The method adopts a strategic calculation process where agents, upon encountering a deadlock select a pseudo goal within a predefined radius around the current position to resolve the deadlock among agents. The calculation is based on controlled strategic algorithm, ensuring that deviation towards pseudo-goal is both purposeful and effective in resolution of deadlock. Once the agent reaches the pseudo goal, it resumes the path towards the original goal, thereby enhancing navigational efficiency and safety. Experimental results demonstrates SPGP's efficacy in reducing deadlock instances and improving overall system throughput in variety of multi-agent navigation scenarios.
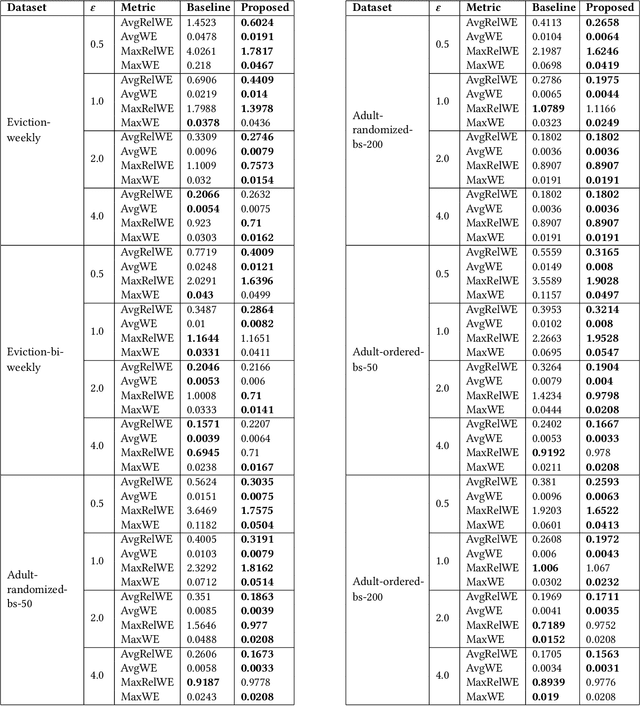
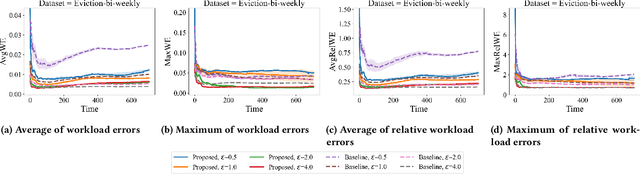
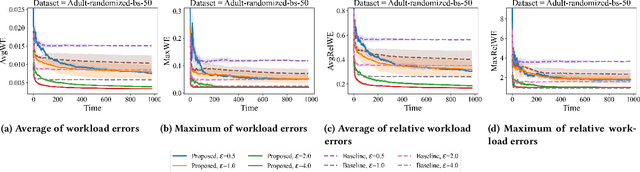
An Algorithm for Streaming Differentially Private Data
Jan 31, 2024Much of the research in differential privacy has focused on offline applications with the assumption that all data is available at once. When these algorithms are applied in practice to streams where data is collected over time, this either violates the privacy guarantees or results in poor utility. We derive an algorithm for differentially private synthetic streaming data generation, especially curated towards spatial datasets. Furthermore, we provide a general framework for online selective counting among a collection of queries which forms a basis for many tasks such as query answering and synthetic data generation. The utility of our algorithm is verified on both real-world and simulated datasets.
Synthetic Text Generation with Differential Privacy: A Simple and Practical Recipe
Oct 25, 2022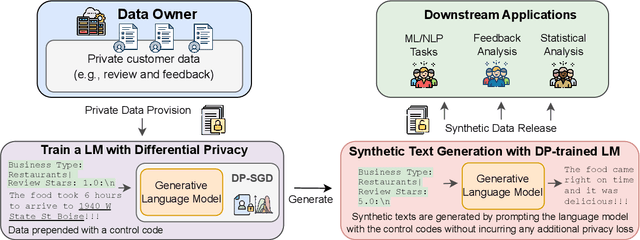
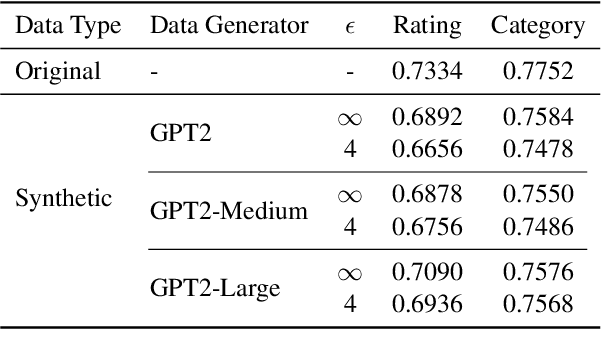
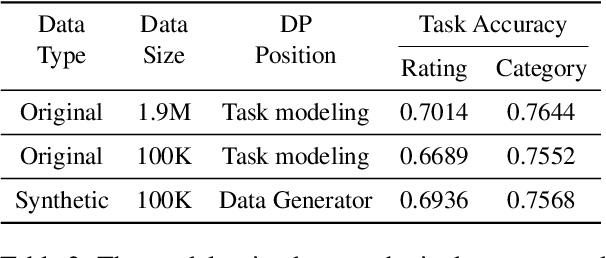
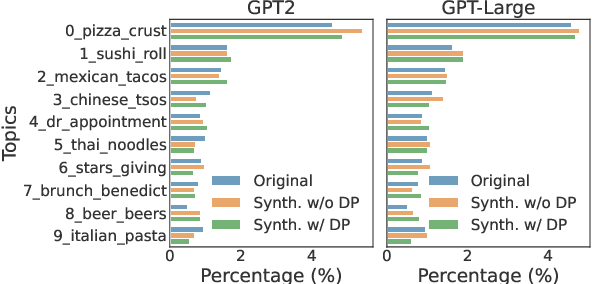
Privacy concerns have attracted increasing attention in data-driven products and services. Existing legislation forbids arbitrary processing of personal data collected from individuals. Generating synthetic versions of such data with a formal privacy guarantee such as differential privacy (DP) is considered to be a solution to address privacy concerns. In this direction, we show a simple, practical, and effective recipe in the text domain: simply fine-tuning a generative language model with DP allows us to generate useful synthetic text while mitigating privacy concerns. Through extensive empirical analyses, we demonstrate that our method produces synthetic data that is competitive in terms of utility with its non-private counterpart and meanwhile provides strong protection against potential privacy leakages.
TextSETTR: Label-Free Text Style Extraction and Tunable Targeted Restyling
Oct 08, 2020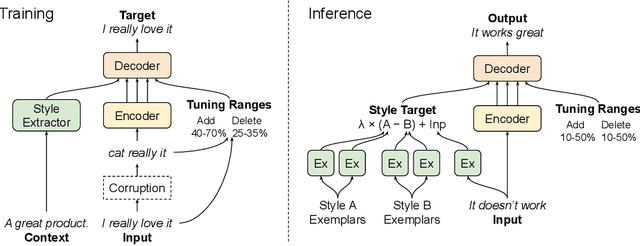
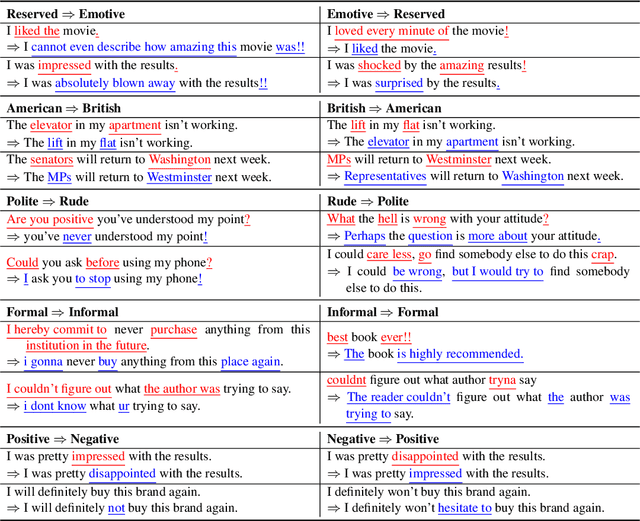
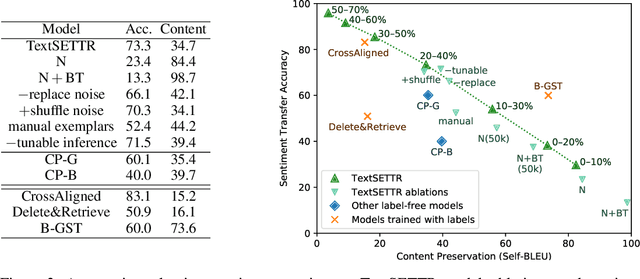

We present a novel approach to the problem of text style transfer. Unlike previous approaches that use parallel or non-parallel labeled data, our technique removes the need for labels entirely, relying instead on the implicit connection in style between adjacent sentences in unlabeled text. We show that T5 (Raffel et al., 2019), a strong pretrained text-to-text model, can be adapted to extract a style vector from arbitrary text and use this vector to condition the decoder to perform style transfer. As the resulting learned style vector space encodes many facets of textual style, we recast transfers as "targeted restyling" vector operations that adjust specific attributes of the input text while preserving others. When trained over unlabeled Amazon reviews data, our resulting TextSETTR model is competitive on sentiment transfer, even when given only four exemplars of each class. Furthermore, we demonstrate that a single model trained on unlabeled Common Crawl data is capable of transferring along multiple dimensions including dialect, emotiveness, formality, politeness, and sentiment.
A Repository of Conversational Datasets
May 29, 2019

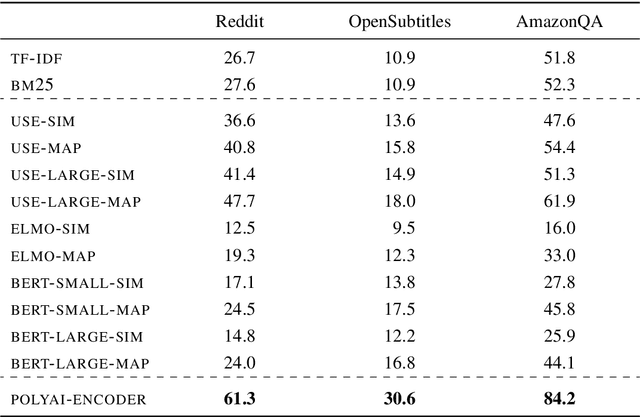

Progress in Machine Learning is often driven by the availability of large datasets, and consistent evaluation metrics for comparing modeling approaches. To this end, we present a repository of conversational datasets consisting of hundreds of millions of examples, and a standardised evaluation procedure for conversational response selection models using '1-of-100 accuracy'. The repository contains scripts that allow researchers to reproduce the standard datasets, or to adapt the pre-processing and data filtering steps to their needs. We introduce and evaluate several competitive baselines for conversational response selection, whose implementations are shared in the repository, as well as a neural encoder model that is trained on the entire training set.
Question-Answer Selection in User to User Marketplace Conversations
Feb 06, 2018
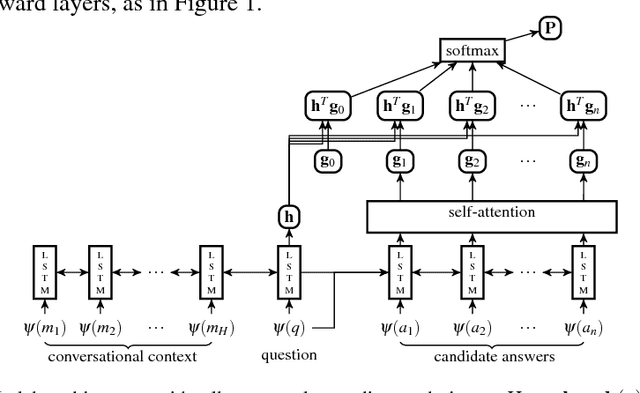

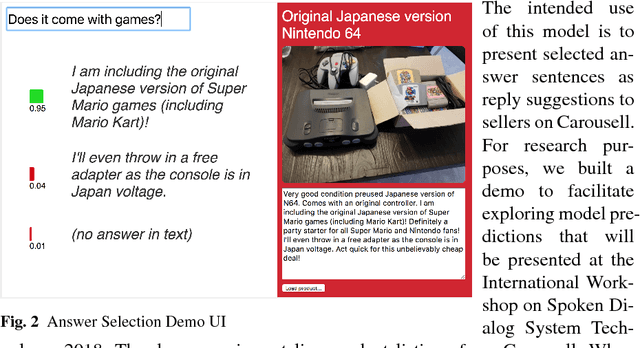
Sellers in user to user marketplaces can be inundated with questions from potential buyers. Answers are often already available in the product description. We collected a dataset of around 590K such questions and answers from conversations in an online marketplace. We propose a question answering system that selects a sentence from the product description using a neural-network ranking model. We explore multiple encoding strategies, with recurrent neural networks and feed-forward attention layers yielding good results. This paper presents a demo to interactively pose buyer questions and visualize the ranking scores of product description sentences from live online listings.