 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Multiscale Graph-based Protein Learning with Geometric Secondary Structural Motifs
Jan 31, 2026Graph neural networks (GNNs) have emerged as powerful tools for learning protein structures by capturing spatial relationships at the residue level. However, existing GNN-based methods often face challenges in learning multiscale representations and modeling long-range dependencies efficiently. In this work, we propose an efficient multiscale graph-based learning framework tailored to proteins. Our proposed framework contains two crucial components: (1) It constructs a hierarchical graph representation comprising a collection of fine-grained subgraphs, each corresponding to a secondary structure motif (e.g., $α$-helices, $β$-strands, loops), and a single coarse-grained graph that connects these motifs based on their spatial arrangement and relative orientation. (2) It employs two GNNs for feature learning: the first operates within individual secondary motifs to capture local interactions, and the second models higher-level structural relationships across motifs. Our modular framework allows a flexible choice of GNN in each stage. Theoretically, we show that our hierarchical framework preserves the desired maximal expressiveness, ensuring no loss of critical structural information. Empirically, we demonstrate that integrating baseline GNNs into our multiscale framework remarkably improves prediction accuracy and reduces computational cost across various benchmarks.
Forgetting-MarI: LLM Unlearning via Marginal Information Regularization
Nov 14, 2025As AI models are trained on ever-expanding datasets, the ability to remove the influence of specific data from trained models has become essential for privacy protection and regulatory compliance. Unlearning addresses this challenge by selectively removing parametric knowledge from the trained models without retraining from scratch, which is critical for resource-intensive models such as Large Language Models (LLMs). Existing unlearning methods often degrade model performance by removing more information than necessary when attempting to ''forget'' specific data. We introduce Forgetting-MarI, an LLM unlearning framework that provably removes only the additional (marginal) information contributed by the data to be unlearned, while preserving the information supported by the data to be retained. By penalizing marginal information, our method yields an explicit upper bound on the unlearn dataset's residual influence in the trained models, providing provable undetectability. Extensive experiments confirm that our approach outperforms current state-of-the-art unlearning methods, delivering reliable forgetting and better preserved general model performance across diverse benchmarks. This advancement represents an important step toward making AI systems more controllable and compliant with privacy and copyright regulations without compromising their effectiveness.
FedOSAA: Improving Federated Learning with One-Step Anderson Acceleration
Mar 14, 2025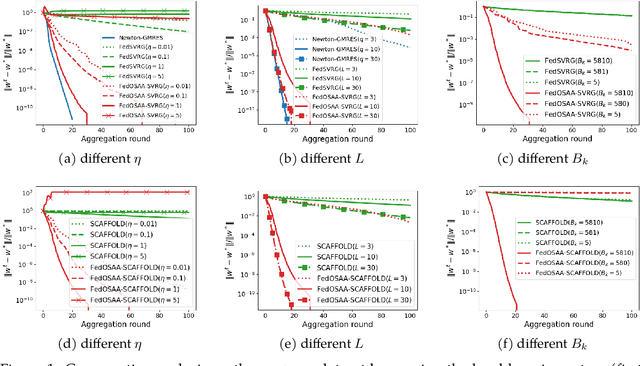
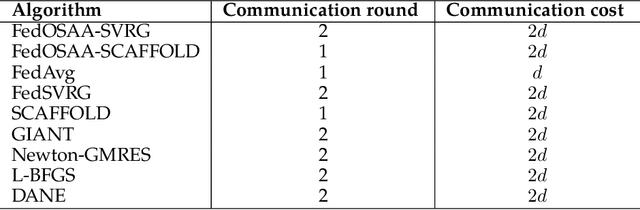
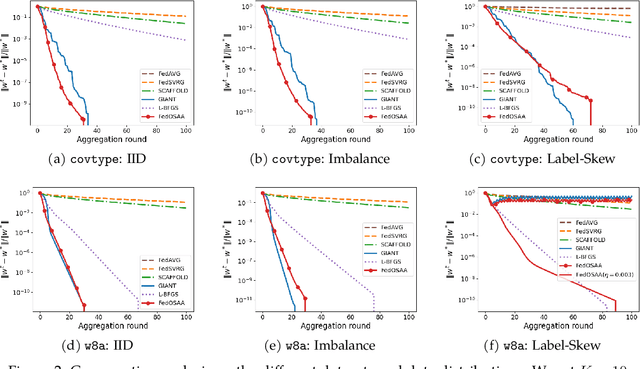
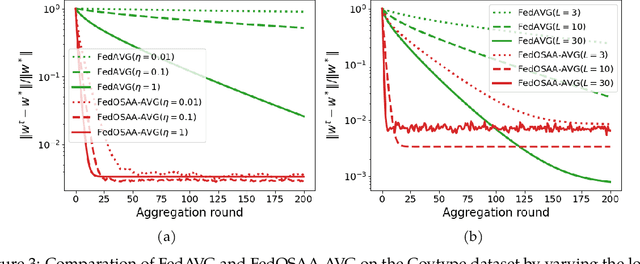
Federated learning (FL) is a distributed machine learning approach that enables multiple local clients and a central server to collaboratively train a model while keeping the data on their own devices. First-order methods, particularly those incorporating variance reduction techniques, are the most widely used FL algorithms due to their simple implementation and stable performance. However, these methods tend to be slow and require a large number of communication rounds to reach the global minimizer. We propose FedOSAA, a novel approach that preserves the simplicity of first-order methods while achieving the rapid convergence typically associated with second-order methods. Our approach applies one Anderson acceleration (AA) step following classical local updates based on first-order methods with variance reduction, such as FedSVRG and SCAFFOLD, during local training. This AA step is able to leverage curvature information from the history points and gives a new update that approximates the Newton-GMRES direction, thereby significantly improving the convergence. We establish a local linear convergence rate to the global minimizer of FedOSAA for smooth and strongly convex loss functions. Numerical comparisons show that FedOSAA substantially improves the communication and computation efficiency of the original first-order methods, achieving performance comparable to second-order methods like GIANT.
Machine Unlearning via Information Theoretic Regularization
Feb 08, 2025How can we effectively remove or "unlearn" undesirable information, such as specific features or individual data points, from a learning outcome while minimizing utility loss and ensuring rigorous guarantees? We introduce a mathematical framework based on information-theoretic regularization to address both feature and data point unlearning. For feature unlearning, we derive a unified solution that simultaneously optimizes diverse learning objectives, including entropy, conditional entropy, KL-divergence, and the energy of conditional probability. For data point unlearning, we first propose a novel definition that serves as a practical condition for unlearning via retraining, is easy to verify, and aligns with the principles of differential privacy from an inference perspective. Then, we provide provable guarantees for our framework on data point unlearning. By combining flexibility in learning objectives with simplicity in regularization design, our approach is highly adaptable and practical for a wide range of machine learning and AI applications.
WHOMP: Optimizing Randomized Controlled Trials via Wasserstein Homogeneity
Sep 27, 2024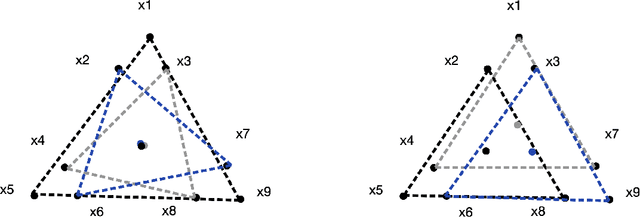
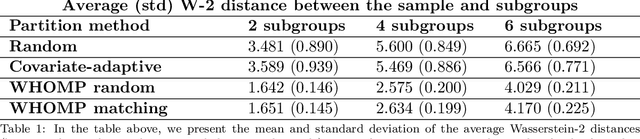
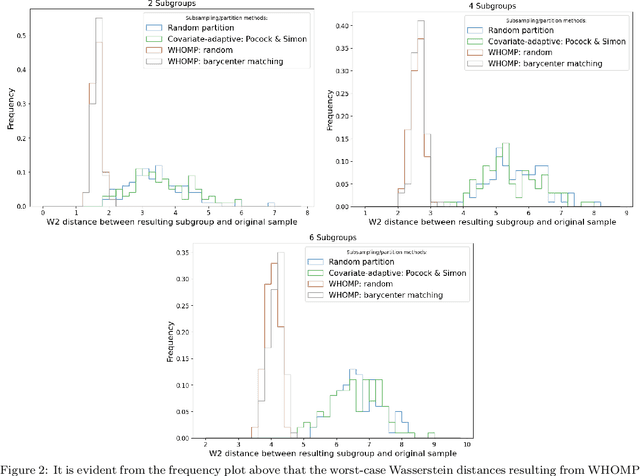

We investigate methods for partitioning datasets into subgroups that maximize diversity within each subgroup while minimizing dissimilarity across subgroups. We introduce a novel partitioning method called the $\textit{Wasserstein Homogeneity Partition}$ (WHOMP), which optimally minimizes type I and type II errors that often result from imbalanced group splitting or partitioning, commonly referred to as accidental bias, in comparative and controlled trials. We conduct an analytical comparison of WHOMP against existing partitioning methods, such as random subsampling, covariate-adaptive randomization, rerandomization, and anti-clustering, demonstrating its advantages. Moreover, we characterize the optimal solutions to the WHOMP problem and reveal an inherent trade-off between the stability of subgroup means and variances among these solutions. Based on our theoretical insights, we design algorithms that not only obtain these optimal solutions but also equip practitioners with tools to select the desired trade-off. Finally, we validate the effectiveness of WHOMP through numerical experiments, highlighting its superiority over traditional methods.
Differentially Private Synthetic High-dimensional Tabular Stream
Aug 31, 2024
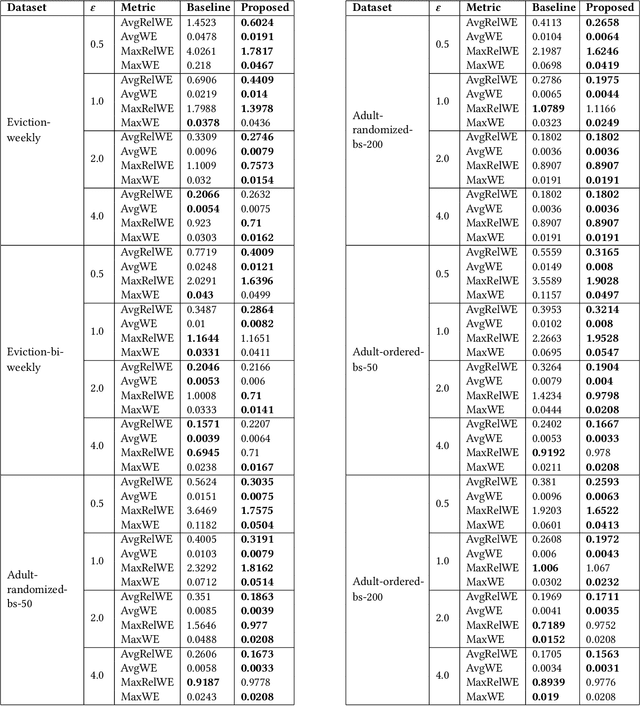
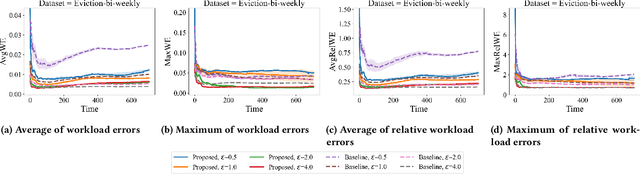
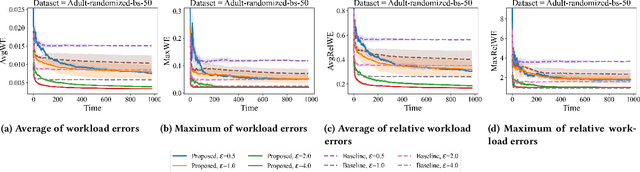
While differentially private synthetic data generation has been explored extensively in the literature, how to update this data in the future if the underlying private data changes is much less understood. We propose an algorithmic framework for streaming data that generates multiple synthetic datasets over time, tracking changes in the underlying private data. Our algorithm satisfies differential privacy for the entire input stream (continual differential privacy) and can be used for high-dimensional tabular data. Furthermore, we show the utility of our method via experiments on real-world datasets. The proposed algorithm builds upon a popular select, measure, fit, and iterate paradigm (used by offline synthetic data generation algorithms) and private counters for streams.
An Algorithm for Streaming Differentially Private Data
Jan 31, 2024Much of the research in differential privacy has focused on offline applications with the assumption that all data is available at once. When these algorithms are applied in practice to streams where data is collected over time, this either violates the privacy guarantees or results in poor utility. We derive an algorithm for differentially private synthetic streaming data generation, especially curated towards spatial datasets. Furthermore, we provide a general framework for online selective counting among a collection of queries which forms a basis for many tasks such as query answering and synthetic data generation. The utility of our algorithm is verified on both real-world and simulated datasets.
On the (In)Compatibility between Group Fairness and Individual Fairness
Jan 13, 2024We study the compatibility between the optimal statistical parity solutions and individual fairness. While individual fairness seeks to treat similar individuals similarly, optimal statistical parity aims to provide similar treatment to individuals who share relative similarity within their respective sensitive groups. The two fairness perspectives, while both desirable from a fairness perspective, often come into conflict in applications. Our goal in this work is to analyze the existence of this conflict and its potential solution. In particular, we establish sufficient (sharp) conditions for the compatibility between the optimal (post-processing) statistical parity $L^2$ learning and the ($K$-Lipschitz or $(\epsilon,\delta)$) individual fairness requirements. Furthermore, when there exists a conflict between the two, we first relax the former to the Pareto frontier (or equivalently the optimal trade-off) between $L^2$ error and statistical disparity, and then analyze the compatibility between the frontier and the individual fairness requirements. Our analysis identifies regions along the Pareto frontier that satisfy individual fairness requirements. (Lastly, we provide individual fairness guarantees for the composition of a trained model and the optimal post-processing step so that one can determine the compatibility of the post-processed model.) This provides practitioners with a valuable approach to attain Pareto optimality for statistical parity while adhering to the constraints of individual fairness.
Differentially private low-dimensional representation of high-dimensional data
May 26, 2023Differentially private synthetic data provide a powerful mechanism to enable data analysis while protecting sensitive information about individuals. However, when the data lie in a high-dimensional space, the accuracy of the synthetic data suffers from the curse of dimensionality. In this paper, we propose a differentially private algorithm to generate low-dimensional synthetic data efficiently from a high-dimensional dataset with a utility guarantee with respect to the Wasserstein distance. A key step of our algorithm is a private principal component analysis (PCA) procedure with a near-optimal accuracy bound that circumvents the curse of dimensionality. Different from the standard perturbation analysis using the Davis-Kahan theorem, our analysis of private PCA works without assuming the spectral gap for the sample covariance matrix.
Semi-Supervised Clustering of Sparse Graphs: Crossing the Information-Theoretic Threshold
May 24, 2022
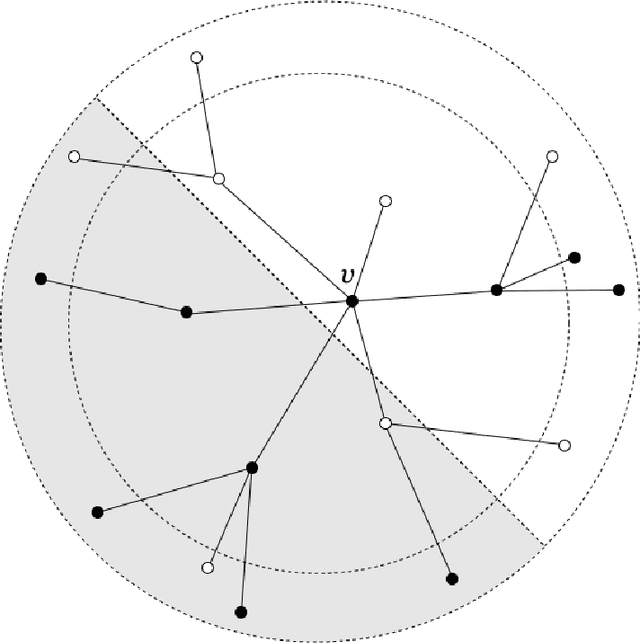
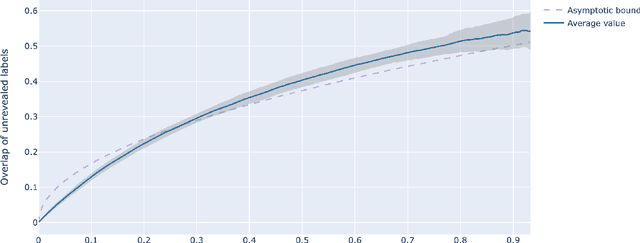
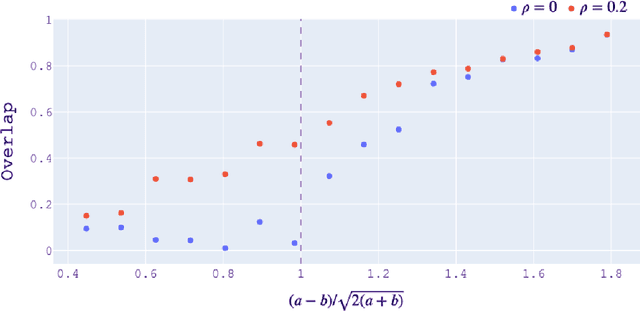
The stochastic block model is a canonical random graph model for clustering and community detection on network-structured data. Decades of extensive study on the problem have established many profound results, among which the phase transition at the Kesten-Stigum threshold is particularly interesting both from a mathematical and an applied standpoint. It states that no estimator based on the network topology can perform substantially better than chance on sparse graphs if the model parameter is below certain threshold. Nevertheless, if we slightly extend the horizon to the ubiquitous semi-supervised setting, such a fundamental limitation will disappear completely. We prove that with arbitrary fraction of the labels revealed, the detection problem is feasible throughout the parameter domain. Moreover, we introduce two efficient algorithms, one combinatorial and one based on optimization, to integrate label information with graph structures. Our work brings a new perspective to stochastic model of networks and semidefinite program research.