 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedOSAA: Improving Federated Learning with One-Step Anderson Acceleration
Paper and Code
Mar 14, 2025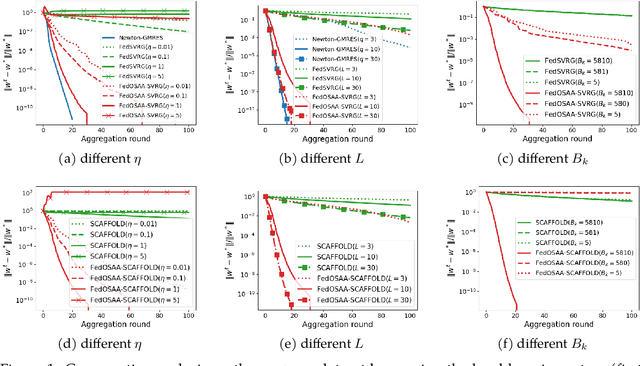
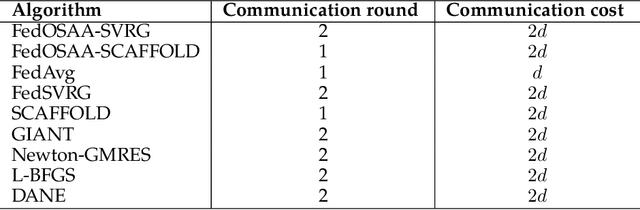
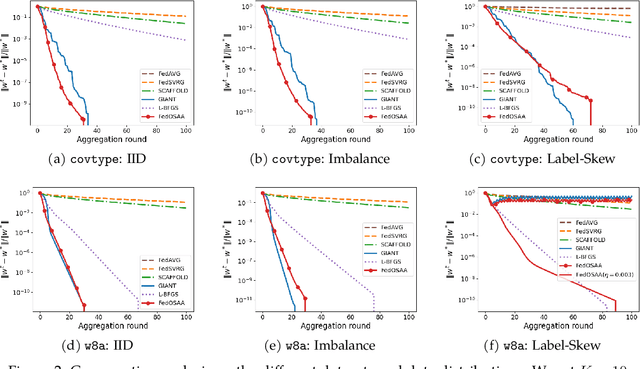
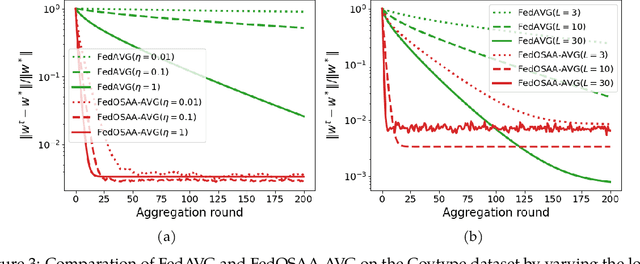
Federated learning (FL) is a distributed machine learning approach that enables multiple local clients and a central server to collaboratively train a model while keeping the data on their own devices. First-order methods, particularly those incorporating variance reduction techniques, are the most widely used FL algorithms due to their simple implementation and stable performance. However, these methods tend to be slow and require a large number of communication rounds to reach the global minimizer. We propose FedOSAA, a novel approach that preserves the simplicity of first-order methods while achieving the rapid convergence typically associated with second-order methods. Our approach applies one Anderson acceleration (AA) step following classical local updates based on first-order methods with variance reduction, such as FedSVRG and SCAFFOLD, during local training. This AA step is able to leverage curvature information from the history points and gives a new update that approximates the Newton-GMRES direction, thereby significantly improving the convergence. We establish a local linear convergence rate to the global minimizer of FedOSAA for smooth and strongly convex loss functions. Numerical comparisons show that FedOSAA substantially improves the communication and computation efficiency of the original first-order methods, achieving performance comparable to second-order methods like GIANT.