 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparation-Utility Pareto Frontier: An Information-Theoretic Characterization
Feb 05, 2026We study the Pareto frontier (optimal trade-off) between utility and separation, a fairness criterion requiring predictive independence from sensitive attributes conditional on the true outcome. Through an information-theoretic lens, we prove a characterization of the utility-separation Pareto frontier, establish its concavity, and thereby prove the increasing marginal cost of separation in terms of utility. In addition, we characterize the conditions under which this trade-off becomes strict, providing a guide for trade-off selection in practice. Based on the theoretical characterization, we develop an empirical regularizer based on conditional mutual information (CMI) between predictions and sensitive attributes given the true outcome. The CMI regularizer is compatible with any deep model trained via gradient-based optimization and serves as a scalar monitor of residual separation violations, offering tractable guarantees during training. Finally, numerical experiments support our theoretical findings: across COMPAS, UCI Adult, UCI Bank, and CelebA, the proposed method substantially reduces separation violations while matching or exceeding the utility of established baseline methods. This study thus offers a provable, stable, and flexible approach to enforcing separation in deep learning.
Forgetting-MarI: LLM Unlearning via Marginal Information Regularization
Nov 14, 2025As AI models are trained on ever-expanding datasets, the ability to remove the influence of specific data from trained models has become essential for privacy protection and regulatory compliance. Unlearning addresses this challenge by selectively removing parametric knowledge from the trained models without retraining from scratch, which is critical for resource-intensive models such as Large Language Models (LLMs). Existing unlearning methods often degrade model performance by removing more information than necessary when attempting to ''forget'' specific data. We introduce Forgetting-MarI, an LLM unlearning framework that provably removes only the additional (marginal) information contributed by the data to be unlearned, while preserving the information supported by the data to be retained. By penalizing marginal information, our method yields an explicit upper bound on the unlearn dataset's residual influence in the trained models, providing provable undetectability. Extensive experiments confirm that our approach outperforms current state-of-the-art unlearning methods, delivering reliable forgetting and better preserved general model performance across diverse benchmarks. This advancement represents an important step toward making AI systems more controllable and compliant with privacy and copyright regulations without compromising their effectiveness.
Machine Unlearning via Information Theoretic Regularization
Feb 08, 2025How can we effectively remove or "unlearn" undesirable information, such as specific features or individual data points, from a learning outcome while minimizing utility loss and ensuring rigorous guarantees? We introduce a mathematical framework based on information-theoretic regularization to address both feature and data point unlearning. For feature unlearning, we derive a unified solution that simultaneously optimizes diverse learning objectives, including entropy, conditional entropy, KL-divergence, and the energy of conditional probability. For data point unlearning, we first propose a novel definition that serves as a practical condition for unlearning via retraining, is easy to verify, and aligns with the principles of differential privacy from an inference perspective. Then, we provide provable guarantees for our framework on data point unlearning. By combining flexibility in learning objectives with simplicity in regularization design, our approach is highly adaptable and practical for a wide range of machine learning and AI applications.
WHOMP: Optimizing Randomized Controlled Trials via Wasserstein Homogeneity
Sep 27, 2024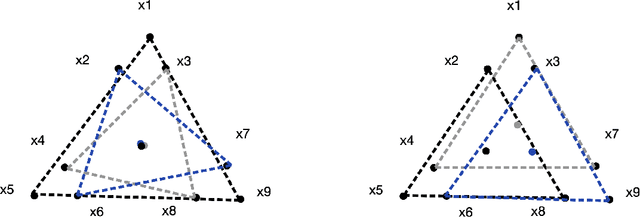
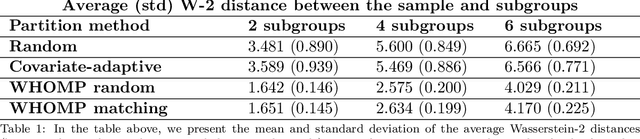
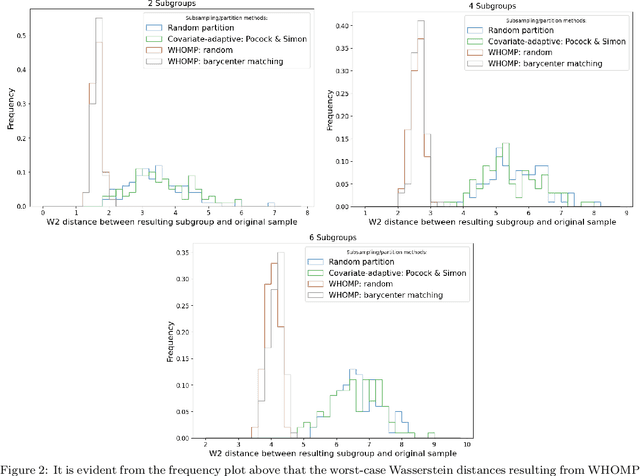

We investigate methods for partitioning datasets into subgroups that maximize diversity within each subgroup while minimizing dissimilarity across subgroups. We introduce a novel partitioning method called the $\textit{Wasserstein Homogeneity Partition}$ (WHOMP), which optimally minimizes type I and type II errors that often result from imbalanced group splitting or partitioning, commonly referred to as accidental bias, in comparative and controlled trials. We conduct an analytical comparison of WHOMP against existing partitioning methods, such as random subsampling, covariate-adaptive randomization, rerandomization, and anti-clustering, demonstrating its advantages. Moreover, we characterize the optimal solutions to the WHOMP problem and reveal an inherent trade-off between the stability of subgroup means and variances among these solutions. Based on our theoretical insights, we design algorithms that not only obtain these optimal solutions but also equip practitioners with tools to select the desired trade-off. Finally, we validate the effectiveness of WHOMP through numerical experiments, highlighting its superiority over traditional methods.
On the (In)Compatibility between Group Fairness and Individual Fairness
Jan 13, 2024We study the compatibility between the optimal statistical parity solutions and individual fairness. While individual fairness seeks to treat similar individuals similarly, optimal statistical parity aims to provide similar treatment to individuals who share relative similarity within their respective sensitive groups. The two fairness perspectives, while both desirable from a fairness perspective, often come into conflict in applications. Our goal in this work is to analyze the existence of this conflict and its potential solution. In particular, we establish sufficient (sharp) conditions for the compatibility between the optimal (post-processing) statistical parity $L^2$ learning and the ($K$-Lipschitz or $(\epsilon,\delta)$) individual fairness requirements. Furthermore, when there exists a conflict between the two, we first relax the former to the Pareto frontier (or equivalently the optimal trade-off) between $L^2$ error and statistical disparity, and then analyze the compatibility between the frontier and the individual fairness requirements. Our analysis identifies regions along the Pareto frontier that satisfy individual fairness requirements. (Lastly, we provide individual fairness guarantees for the composition of a trained model and the optimal post-processing step so that one can determine the compatibility of the post-processed model.) This provides practitioners with a valuable approach to attain Pareto optimality for statistical parity while adhering to the constraints of individual fairness.
Fair Data Representation for Machine Learning at the Pareto Frontier
Jan 02, 2022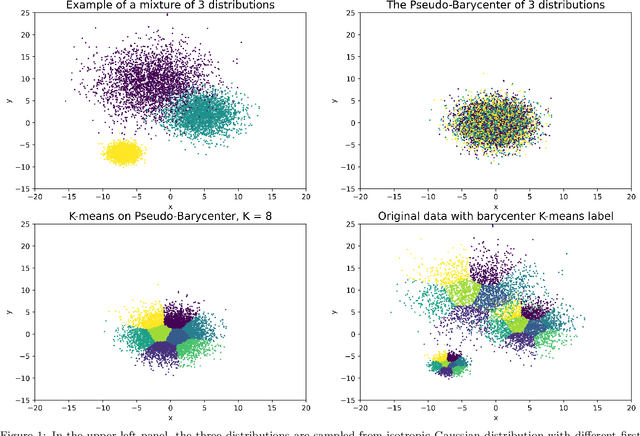
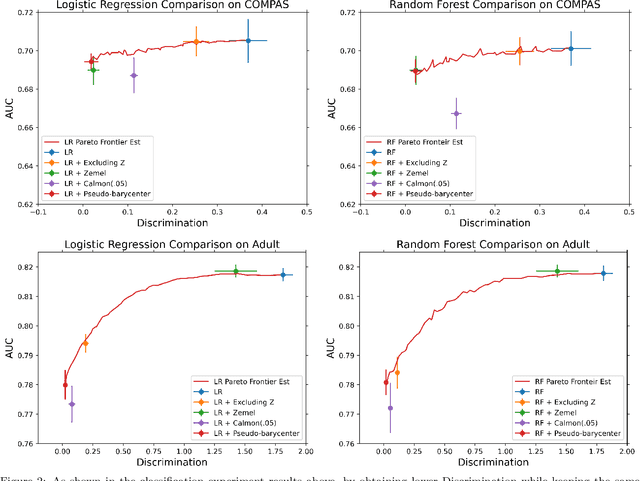
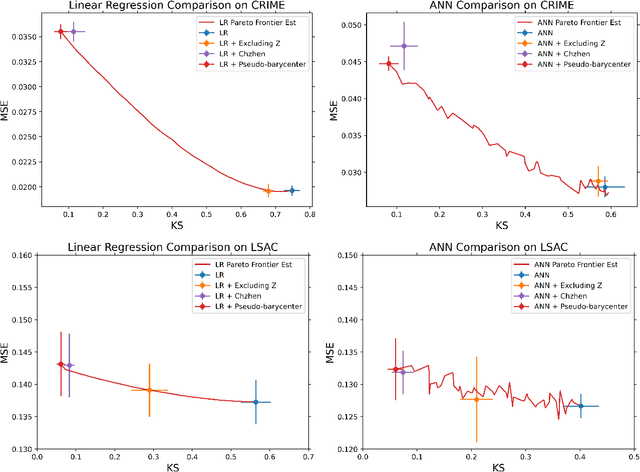
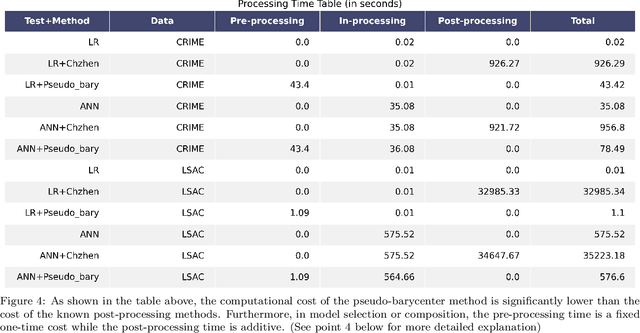
As machine learning powered decision making is playing an increasingly important role in our daily lives, it is imperative to strive for fairness of the underlying data processing and algorithms. We propose a pre-processing algorithm for fair data representation via which L2- objective supervised learning algorithms result in an estimation of the Pareto frontier between prediction error and statistical disparity. In particular, the present work applies the optimal positive definite affine transport maps to approach the post-processing Wasserstein barycenter characterization of the optimal fair L2-objective supervised learning via a pre-processing data deformation. We call the resulting data Wasserstein pseudo-barycenter. Furthermore, we show that the Wasserstein geodesics from the learning outcome marginals to the barycenter characterizes the Pareto frontier between L2-loss and total Wasserstein distance among learning outcome marginals. Thereby, an application of McCann interpolation generalizes the pseudo-barycenter to a family of data representations via which L2-objective supervised learning algorithms result in the Pareto frontier. Numerical simulations underscore the advantages of the proposed data representation: (1) the pre-processing step is compositive with arbitrary L2-objective supervised learning methods and unseen data; (2) the fair representation protects data privacy by preventing the training machine from direct or indirect access to the sensitive information of the data; (3) the optimal affine map results in efficient computation of fair supervised learning on high-dimensional data; (4) experimental results shed light on the fairness of L2-objective unsupervised learning via the proposed fair data representation.