 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAchieving the Kesten-Stigum bound in the non-uniform hypergraph stochastic block model
Apr 21, 2026We study the community detection problem in the non-uniform hypergraph stochastic block model (HSBM), where hyperedges of varying sizes coexist. This setting captures higher-order and multi-view interactions and raises a fundamental question: can multiple uniform hypergraph layers below the detection threshold be combined to enable weak recovery? We answer this question by establishing a Kesten--Stigum-type bound for weak recovery in a general class of non-uniform HSBMs with $r$ blocks, generated according to multiple symmetric probability tensors. In the case $r=2$, we show that weak recovery is possible whenever the sum of the signal-to-noise ratios across all uniform hypergraph layers exceeds one, thereby confirming the positive part of a conjecture in (Chodrow et al., 2023). Moreover, we provide a polynomial-time spectral algorithm that achieves this threshold via an optimally weighted non-backtracking operator. For the unweighted non-backtracking matrix, our spectral method attains a different algorithmic threshold, also conjectured in (Chodrow et al., 2023). Our approach develops a spectral theory for weighted non-backtracking operators on non-uniform hypergraphs, including a precise characterization of outlier eigenvalues and eigenvector overlaps. We introduce a novel Ihara--Bass formula tailored to weighted non-uniform hypergraphs, which yields an efficient low-dimensional representation and leads to a provable spectral reconstruction algorithm. Taken together, these results provide a principled and computationally efficient approach to clustering in non-uniform hypergraphs, and highlight the role of optimal weighting in aggregating heterogeneous higher-order interactions.
SMAL-pets: SMAL Based Avatars of Pets from Single Image
Mar 17, 2026Creating high-fidelity, animatable 3D dog avatars remains a formidable challenge in computer vision. Unlike human digital doubles, animal reconstruction faces a critical shortage of large-scale, annotated datasets for specialized applications. Furthermore, the immense morphological diversity across species, breeds, and crosses, which varies significantly in size, proportions, and features, complicates the generalization of existing models. Current reconstruction methods often struggle to capture realistic fur textures. Additionally, ensuring these avatars are fully editable and capable of performing complex, naturalistic movements typically necessitates labor-intensive manual mesh manipulation and expert rigging. This paper introduces SMAL-pets, a comprehensive framework that generates high-quality, editable animal avatars from a single input image. Our approach bridges the gap between reconstruction and generative modeling by leveraging a hybrid architecture. Our method integrates 3D Gaussian Splatting with the SMAL parametric model to provide a representation that is both visually high-fidelity and anatomically grounded. We introduce a multimodal editing suite that enables users to refine the avatar's appearance and execute complex animations through direct textual prompts. By allowing users to control both the aesthetic and behavioral aspects of the model via natural language, SMAL-pets provides a flexible, robust tool for animation and virtual reality.
Power-Law Spectrum of the Random Feature Model
Mar 15, 2026Scaling laws for neural networks, in which the loss decays as a power-law in the number of parameters, data, and compute, depend fundamentally on the spectral structure of the data covariance, with power-law eigenvalue decay appearing ubiquitously in vision and language tasks. A central question is whether this spectral structure is preserved or destroyed when data passes through the basic building block of a neural network: a random linear projection followed by a nonlinear activation. We study this question for the random feature model: given data $x \sim N(0,H)\in \mathbb{R}^v$ where $H$ has $α$-power-law spectrum ($λ_j(H ) \asymp j^{-α}$, $α> 1$), a Gaussian sketch matrix $W \in \mathbb{R}^{v\times d}$, and an entrywise monomial $f(y) = y^{p}$, we characterize the eigenvalues of the population random-feature covariance $\mathbb{E}_{x }[\frac{1}{d}f(W^\top x )^{\otimes 2}]$. We prove matching upper and lower bounds: for all $1 \leq j \leq c_1 d \log^{-(p+1)}(d)$, the $j$-th eigenvalue is of order $\left(\log^{p-1}(j+1)/j\right)^α$. For $ c_1 d \log^{-(p+1)}(d)\leq j\leq d$, the $j$-th eigenvalue is of order $j^{-α}$ up to a polylog factor. That is, the power-law exponent $α$ is inherited exactly from the input covariance, modified only by a logarithmic correction that depends on the monomial degree $p$. The proof combines a dyadic head-tail decomposition with Wick chaos expansions for higher-order monomials and random matrix concentration inequalities.
Wedge Sampling: Efficient Tensor Completion with Nearly-Linear Sample Complexity
Feb 05, 2026We introduce Wedge Sampling, a new non-adaptive sampling scheme for low-rank tensor completion. We study recovery of an order-$k$ low-rank tensor of dimension $n \times \cdots \times n$ from a subset of its entries. Unlike the standard uniform entry model (i.e., i.i.d. samples from $[n]^k$), wedge sampling allocates observations to structured length-two patterns (wedges) in an associated bipartite sampling graph. By directly promoting these length-two connections, the sampling design strengthens the spectral signal that underlies efficient initialization, in regimes where uniform sampling is too sparse to generate enough informative correlations. Our main result shows that this change in sampling paradigm enables polynomial-time algorithms to achieve both weak and exact recovery with nearly linear sample complexity in $n$. The approach is also plug-and-play: wedge-sampling-based spectral initialization can be combined with existing refinement procedures (e.g., spectral or gradient-based methods) using only an additional $\tilde{O}(n)$ uniformly sampled entries, substantially improving over the $\tilde{O}(n^{k/2})$ sample complexity typically required under uniform entry sampling for efficient methods. Overall, our results suggest that the statistical-to-computational gap highlighted in Barak and Moitra (2022) is, to a large extent, a consequence of the uniform entry sampling model for tensor completion, and that alternative non-adaptive measurement designs that guarantee a strong initialization can overcome this barrier.
Minimax optimal differentially private synthetic data for smooth queries
Feb 02, 2026Differentially private synthetic data enables the sharing and analysis of sensitive datasets while providing rigorous privacy guarantees for individual contributors. A central challenge is to achieve strong utility guarantees for meaningful downstream analysis. Many existing methods ensure uniform accuracy over broad query classes, such as all Lipschitz functions, but this level of generality often leads to suboptimal rates for statistics of practical interest. Since many common data analysis queries exhibit smoothness beyond what worst-case Lipschitz bounds capture, we ask whether exploiting this additional structure can yield improved utility. We study the problem of generating $(\varepsilon,δ)$-differentially private synthetic data from a dataset of size $n$ supported on the hypercube $[-1,1]^d$, with utility guarantees uniformly for all smooth queries having bounded derivatives up to order $k$. We propose a polynomial-time algorithm that achieves a minimax error rate of $n^{-\min \{1, \frac{k}{d}\}}$, up to a $\log(n)$ factor. This characterization uncovers a phase transition at $k=d$. Our results generalize the Chebyshev moment matching framework of (Musco et al., 2025; Wang et al., 2016) and strictly improve the error rates for $k$-smooth queries established in (Wang et al., 2016). Moreover, we establish the first minimax lower bound for the utility of $(\varepsilon,δ)$-differentially private synthetic data with respect to $k$-smooth queries, extending the Wasserstein lower bound for $\varepsilon$-differential privacy in (Boedihardjo et al., 2024).
Residual Rotation Correction using Tactile Equivariance
Nov 11, 2025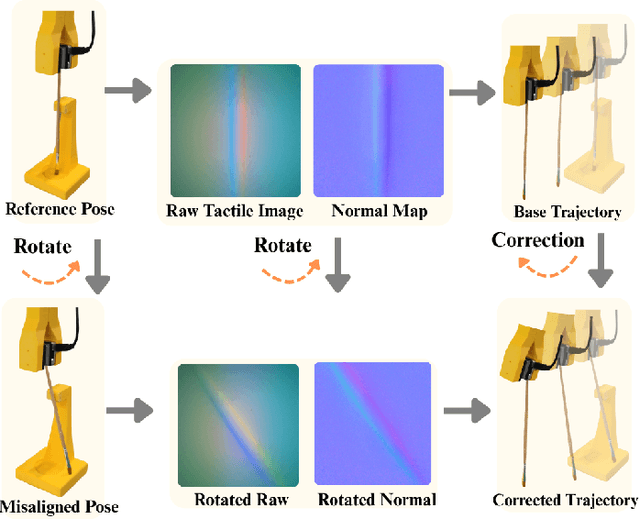
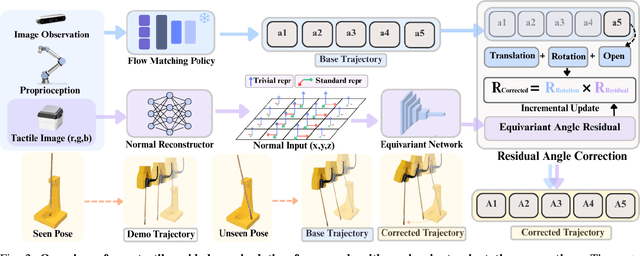
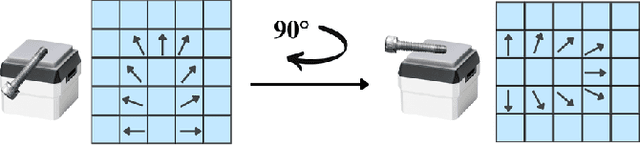

Visuotactile policy learning augments vision-only policies with tactile input, facilitating contact-rich manipulation. However, the high cost of tactile data collection makes sample efficiency the key requirement for developing visuotactile policies. We present EquiTac, a framework that exploits the inherent SO(2) symmetry of in-hand object rotation to improve sample efficiency and generalization for visuotactile policy learning. EquiTac first reconstructs surface normals from raw RGB inputs of vision-based tactile sensors, so rotations of the normal vector field correspond to in-hand object rotations. An SO(2)-equivariant network then predicts a residual rotation action that augments a base visuomotor policy at test time, enabling real-time rotation correction without additional reorientation demonstrations. On a real robot, EquiTac accurately achieves robust zero-shot generalization to unseen in-hand orientations with very few training samples, where baselines fail even with more training data. To our knowledge, this is the first tactile learning method to explicitly encode tactile equivariance for policy learning, yielding a lightweight, symmetry-aware module that improves reliability in contact-rich tasks.
EquAct: An SE(3)-Equivariant Multi-Task Transformer for Open-Loop Robotic Manipulation
May 27, 2025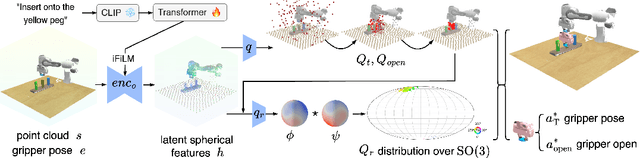
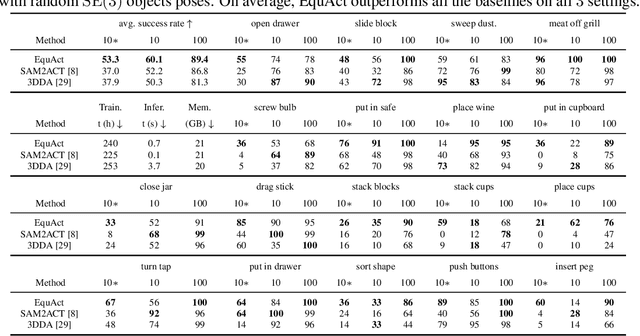
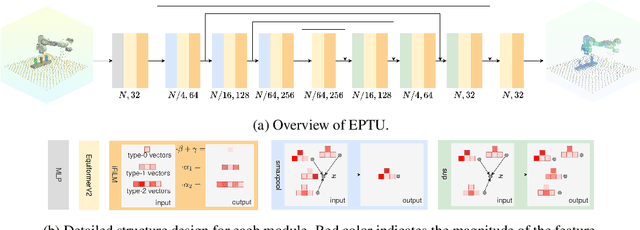
Transformer architectures can effectively learn language-conditioned, multi-task 3D open-loop manipulation policies from demonstrations by jointly processing natural language instructions and 3D observations. However, although both the robot policy and language instructions inherently encode rich 3D geometric structures, standard transformers lack built-in guarantees of geometric consistency, often resulting in unpredictable behavior under SE(3) transformations of the scene. In this paper, we leverage SE(3) equivariance as a key structural property shared by both policy and language, and propose EquAct-a novel SE(3)-equivariant multi-task transformer. EquAct is theoretically guaranteed to be SE(3) equivariant and consists of two key components: (1) an efficient SE(3)-equivariant point cloud-based U-net with spherical Fourier features for policy reasoning, and (2) SE(3)-invariant Feature-wise Linear Modulation (iFiLM) layers for language conditioning. To evaluate its spatial generalization ability, we benchmark EquAct on 18 RLBench simulation tasks with both SE(3) and SE(2) scene perturbations, and on 4 physical tasks. EquAct performs state-of-the-art across these simulation and physical tasks.
Hierarchical Equivariant Policy via Frame Transf
Feb 09, 2025Recent advances in hierarchical policy learning highlight the advantages of decomposing systems into high-level and low-level agents, enabling efficient long-horizon reasoning and precise fine-grained control. However, the interface between these hierarchy levels remains underexplored, and existing hierarchical methods often ignore domain symmetry, resulting in the need for extensive demonstrations to achieve robust performance. To address these issues, we propose Hierarchical Equivariant Policy (HEP), a novel hierarchical policy framework. We propose a frame transfer interface for hierarchical policy learning, which uses the high-level agent's output as a coordinate frame for the low-level agent, providing a strong inductive bias while retaining flexibility. Additionally, we integrate domain symmetries into both levels and theoretically demonstrate the system's overall equivariance. HEP achieves state-of-the-art performance in complex robotic manipulation tasks, demonstrating significant improvements in both simulation and real-world settings.
Community detection with the Bethe-Hessian
Nov 05, 2024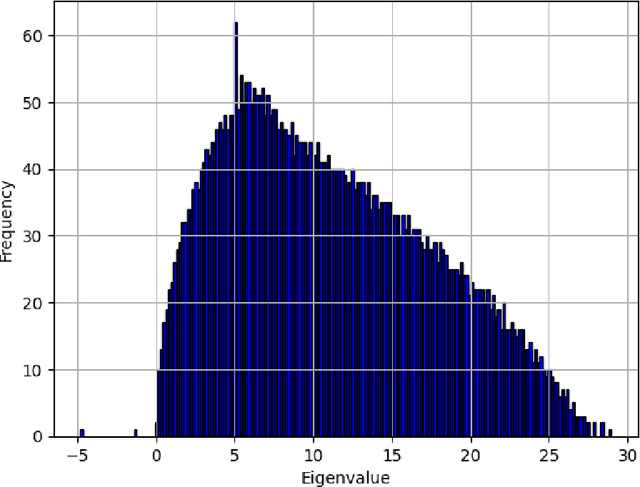
The Bethe-Hessian matrix, introduced by Saade, Krzakala, and Zdeborov\'a (2014), is a Hermitian matrix designed for applying spectral clustering algorithms to sparse networks. Rather than employing a non-symmetric and high-dimensional non-backtracking operator, a spectral method based on the Bethe-Hessian matrix is conjectured to also reach the Kesten-Stigum detection threshold in the sparse stochastic block model (SBM). We provide the first rigorous analysis of the Bethe-Hessian spectral method in the SBM under both the bounded expected degree and the growing degree regimes. Specifically, we demonstrate that: (i) When the expected degree $d\geq 2$, the number of negative outliers of the Bethe-Hessian matrix can consistently estimate the number of blocks above the Kesten-Stigum threshold, thus confirming a conjecture from Saade, Krzakala, and Zdeborov\'a (2014) for $d\geq 2$. (ii) For sufficiently large $d$, its eigenvectors can be used to achieve weak recovery. (iii) As $d\to\infty$, we establish the concentration of the locations of its negative outlier eigenvalues, and weak consistency can be achieved via a spectral method based on the Bethe-Hessian matrix.
Non-convex matrix sensing: Breaking the quadratic rank barrier in the sample complexity
Aug 20, 2024For the problem of reconstructing a low-rank matrix from a few linear measurements, two classes of algorithms have been widely studied in the literature: convex approaches based on nuclear norm minimization, and non-convex approaches that use factorized gradient descent. Under certain statistical model assumptions, it is known that nuclear norm minimization recovers the ground truth as soon as the number of samples scales linearly with the number of degrees of freedom of the ground-truth. In contrast, while non-convex approaches are computationally less expensive, existing recovery guarantees assume that the number of samples scales at least quadratically with the rank $r$ of the ground-truth matrix. In this paper, we close this gap by showing that the non-convex approaches can be as efficient as nuclear norm minimization in terms of sample complexity. Namely, we consider the problem of reconstructing a positive semidefinite matrix from a few Gaussian measurements. We show that factorized gradient descent with spectral initialization converges to the ground truth with a linear rate as soon as the number of samples scales with $ \Omega (rd\kappa^2)$, where $d$ is the dimension, and $\kappa$ is the condition number of the ground truth matrix. This improves the previous rank-dependence from quadratic to linear. Our proof relies on a probabilistic decoupling argument, where we show that the gradient descent iterates are only weakly dependent on the individual entries of the measurement matrices. We expect that our proof technique is of independent interest for other non-convex problems.