 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNear-optimal estimates for the $\ell^p$-Lipschitz constants of deep random ReLU neural networks
Jun 24, 2025

This paper studies the $\ell^p$-Lipschitz constants of ReLU neural networks $\Phi: \mathbb{R}^d \to \mathbb{R}$ with random parameters for $p \in [1,\infty]$. The distribution of the weights follows a variant of the He initialization and the biases are drawn from symmetric distributions. We derive high probability upper and lower bounds for wide networks that differ at most by a factor that is logarithmic in the network's width and linear in its depth. In the special case of shallow networks, we obtain matching bounds. Remarkably, the behavior of the $\ell^p$-Lipschitz constant varies significantly between the regimes $ p \in [1,2) $ and $ p \in [2,\infty] $. For $p \in [2,\infty]$, the $\ell^p$-Lipschitz constant behaves similarly to $\Vert g\Vert_{p'}$, where $g \in \mathbb{R}^d$ is a $d$-dimensional standard Gaussian vector and $1/p + 1/p' = 1$. In contrast, for $p \in [1,2)$, the $\ell^p$-Lipschitz constant aligns more closely to $\Vert g \Vert_{2}$.
Non-convex matrix sensing: Breaking the quadratic rank barrier in the sample complexity
Aug 20, 2024For the problem of reconstructing a low-rank matrix from a few linear measurements, two classes of algorithms have been widely studied in the literature: convex approaches based on nuclear norm minimization, and non-convex approaches that use factorized gradient descent. Under certain statistical model assumptions, it is known that nuclear norm minimization recovers the ground truth as soon as the number of samples scales linearly with the number of degrees of freedom of the ground-truth. In contrast, while non-convex approaches are computationally less expensive, existing recovery guarantees assume that the number of samples scales at least quadratically with the rank $r$ of the ground-truth matrix. In this paper, we close this gap by showing that the non-convex approaches can be as efficient as nuclear norm minimization in terms of sample complexity. Namely, we consider the problem of reconstructing a positive semidefinite matrix from a few Gaussian measurements. We show that factorized gradient descent with spectral initialization converges to the ground truth with a linear rate as soon as the number of samples scales with $ \Omega (rd\kappa^2)$, where $d$ is the dimension, and $\kappa$ is the condition number of the ground truth matrix. This improves the previous rank-dependence from quadratic to linear. Our proof relies on a probabilistic decoupling argument, where we show that the gradient descent iterates are only weakly dependent on the individual entries of the measurement matrices. We expect that our proof technique is of independent interest for other non-convex problems.
On the Lipschitz constant of random neural networks
Nov 02, 2023Empirical studies have widely demonstrated that neural networks are highly sensitive to small, adversarial perturbations of the input. The worst-case robustness against these so-called adversarial examples can be quantified by the Lipschitz constant of the neural network. However, only few theoretical results regarding this quantity exist in the literature. In this paper, we initiate the study of the Lipschitz constant of random ReLU neural networks, i.e., neural networks whose weights are chosen at random and which employ the ReLU activation function. For shallow neural networks, we characterize the Lipschitz constant up to an absolute numerical constant. Moreover, we extend our analysis to deep neural networks of sufficiently large width where we prove upper and lower bounds for the Lipschitz constant. These bounds match up to a logarithmic factor that depends on the depth.
Implicit Balancing and Regularization: Generalization and Convergence Guarantees for Overparameterized Asymmetric Matrix Sensing
Mar 24, 2023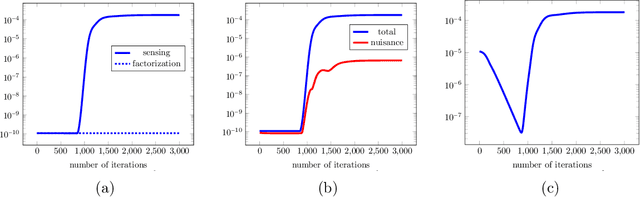
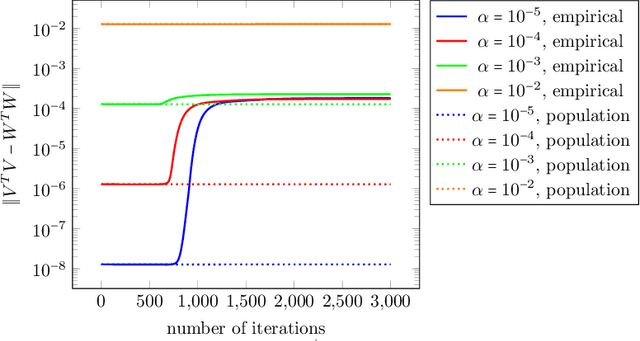
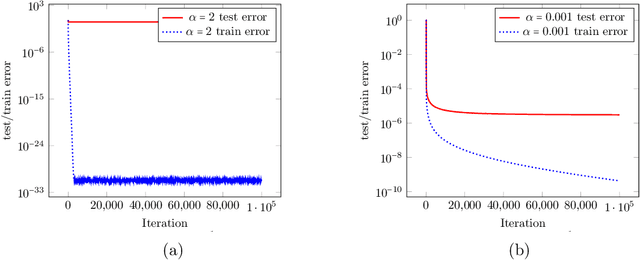
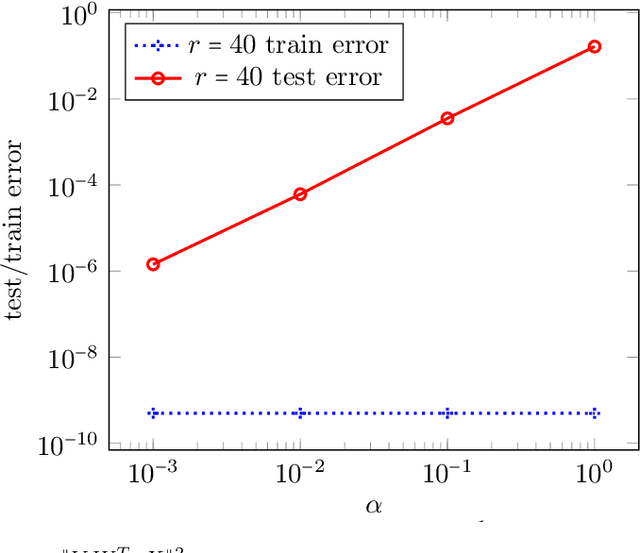
Recently, there has been significant progress in understanding the convergence and generalization properties of gradient-based methods for training overparameterized learning models. However, many aspects including the role of small random initialization and how the various parameters of the model are coupled during gradient-based updates to facilitate good generalization remain largely mysterious. A series of recent papers have begun to study this role for non-convex formulations of symmetric Positive Semi-Definite (PSD) matrix sensing problems which involve reconstructing a low-rank PSD matrix from a few linear measurements. The underlying symmetry/PSDness is crucial to existing convergence and generalization guarantees for this problem. In this paper, we study a general overparameterized low-rank matrix sensing problem where one wishes to reconstruct an asymmetric rectangular low-rank matrix from a few linear measurements. We prove that an overparameterized model trained via factorized gradient descent converges to the low-rank matrix generating the measurements. We show that in this setting, factorized gradient descent enjoys two implicit properties: (1) coupling of the trajectory of gradient descent where the factors are coupled in various ways throughout the gradient update trajectory and (2) an algorithmic regularization property where the iterates show a propensity towards low-rank models despite the overparameterized nature of the factorized model. These two implicit properties in turn allow us to show that the gradient descent trajectory from small random initialization moves towards solutions that are both globally optimal and generalize well.
How robust is randomized blind deconvolution via nuclear norm minimization against adversarial noise?
Mar 17, 2023In this paper, we study the problem of recovering two unknown signals from their convolution, which is commonly referred to as blind deconvolution. Reformulation of blind deconvolution as a low-rank recovery problem has led to multiple theoretical recovery guarantees in the past decade due to the success of the nuclear norm minimization heuristic. In particular, in the absence of noise, exact recovery has been established for sufficiently incoherent signals contained in lower-dimensional subspaces. However, if the convolution is corrupted by additive bounded noise, the stability of the recovery problem remains much less understood. In particular, existing reconstruction bounds involve large dimension factors and therefore fail to explain the empirical evidence for dimension-independent robustness of nuclear norm minimization. Recently, theoretical evidence has emerged for ill-posed behavior of low-rank matrix recovery for sufficiently small noise levels. In this work, we develop improved recovery guarantees for blind deconvolution with adversarial noise which exhibit square-root scaling in the noise level. Hence, our results are consistent with existing counterexamples which speak against linear scaling in the noise level as demonstrated for related low-rank matrix recovery problems.
Randomly Initialized Alternating Least Squares: Fast Convergence for Matrix Sensing
Apr 25, 2022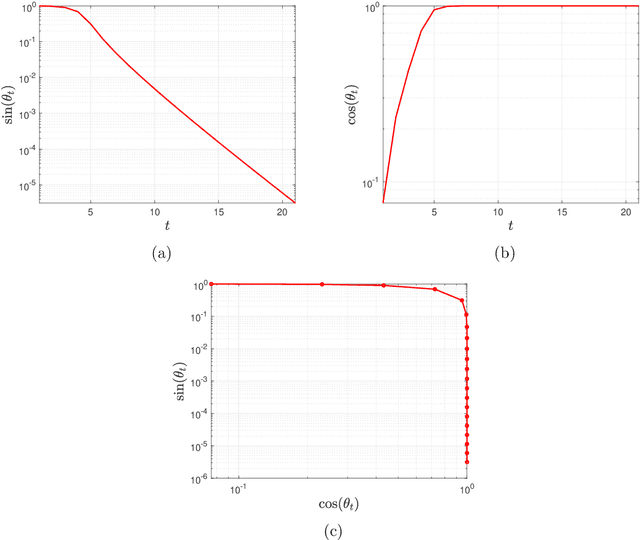
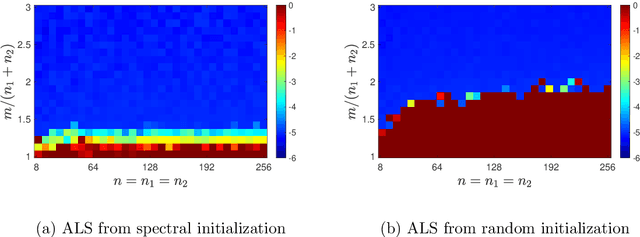
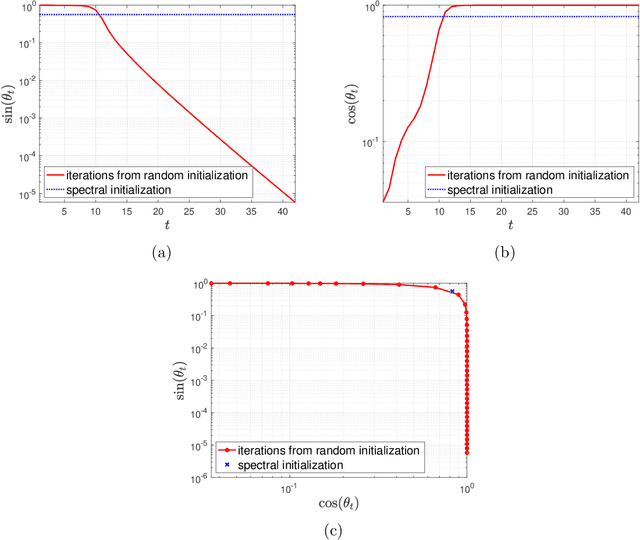
We consider the problem of reconstructing rank-one matrices from random linear measurements, a task that appears in a variety of problems in signal processing, statistics, and machine learning. In this paper, we focus on the Alternating Least Squares (ALS) method. While this algorithm has been studied in a number of previous works, most of them only show convergence from an initialization close to the true solution and thus require a carefully designed initialization scheme. However, random initialization has often been preferred by practitioners as it is model-agnostic. In this paper, we show that ALS with random initialization converges to the true solution with $\varepsilon$-accuracy in $O(\log n + \log (1/\varepsilon)) $ iterations using only a near-optimal amount of samples, where we assume the measurement matrices to be i.i.d. Gaussian and where by $n$ we denote the ambient dimension. Key to our proof is the observation that the trajectory of the ALS iterates only depends very mildly on certain entries of the random measurement matrices. Numerical experiments corroborate our theoretical predictions.
Small random initialization is akin to spectral learning: Optimization and generalization guarantees for overparameterized low-rank matrix reconstruction
Jun 28, 2021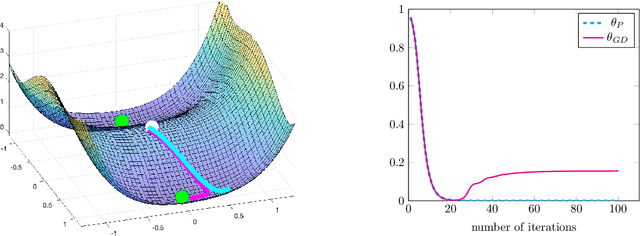
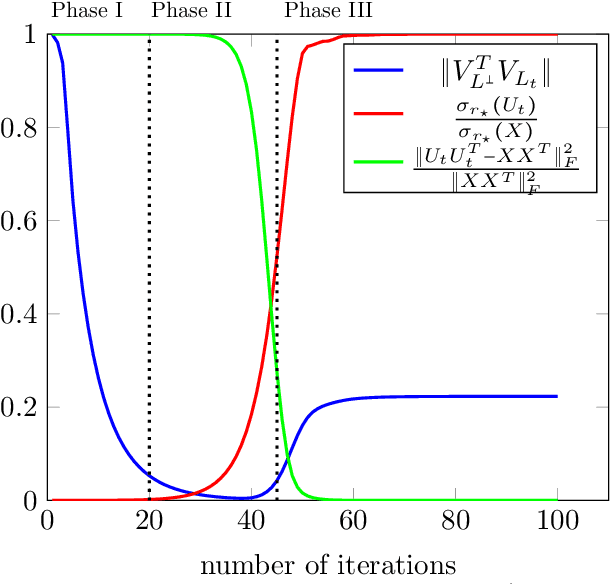
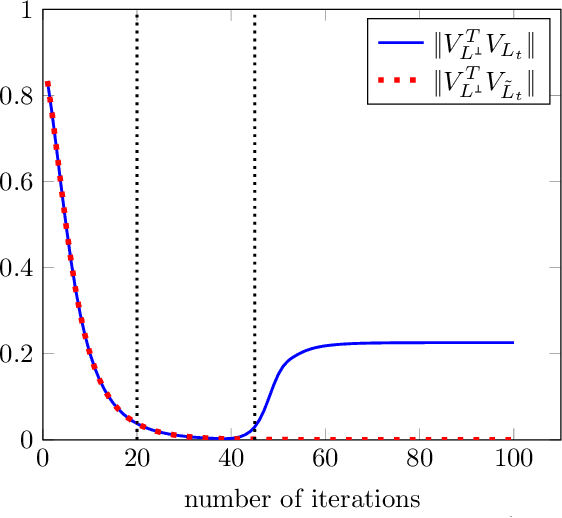
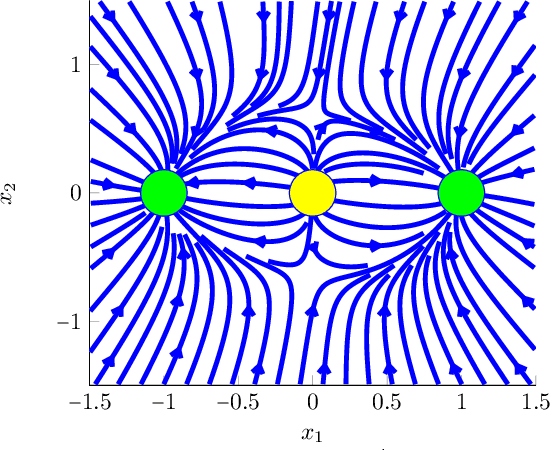
Recently there has been significant theoretical progress on understanding the convergence and generalization of gradient-based methods on nonconvex losses with overparameterized models. Nevertheless, many aspects of optimization and generalization and in particular the critical role of small random initialization are not fully understood. In this paper, we take a step towards demystifying this role by proving that small random initialization followed by a few iterations of gradient descent behaves akin to popular spectral methods. We also show that this implicit spectral bias from small random initialization, which is provably more prominent for overparameterized models, also puts the gradient descent iterations on a particular trajectory towards solutions that are not only globally optimal but also generalize well. Concretely, we focus on the problem of reconstructing a low-rank matrix from a few measurements via a natural nonconvex formulation. In this setting, we show that the trajectory of the gradient descent iterations from small random initialization can be approximately decomposed into three phases: (I) a spectral or alignment phase where we show that that the iterates have an implicit spectral bias akin to spectral initialization allowing us to show that at the end of this phase the column space of the iterates and the underlying low-rank matrix are sufficiently aligned, (II) a saddle avoidance/refinement phase where we show that the trajectory of the gradient iterates moves away from certain degenerate saddle points, and (III) a local refinement phase where we show that after avoiding the saddles the iterates converge quickly to the underlying low-rank matrix. Underlying our analysis are insights for the analysis of overparameterized nonconvex optimization schemes that may have implications for computational problems beyond low-rank reconstruction.
Proof methods for robust low-rank matrix recovery
Jun 08, 2021
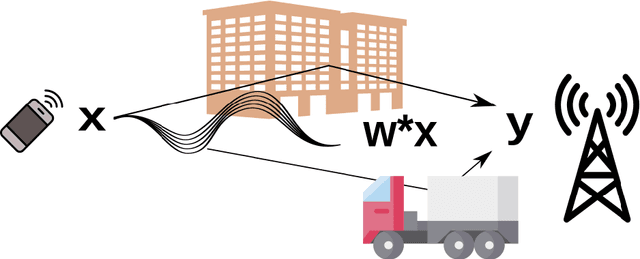
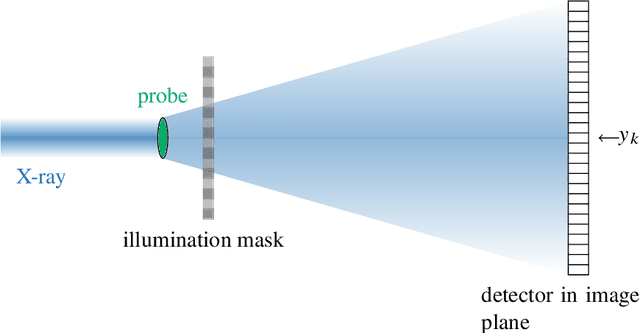
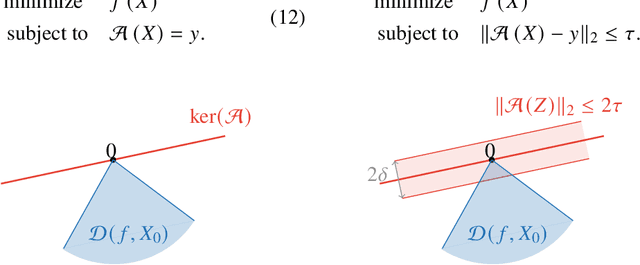
Low-rank matrix recovery problems arise naturally as mathematical formulations of various inverse problems, such as matrix completion, blind deconvolution, and phase retrieval. Over the last two decades, a number of works have rigorously analyzed the reconstruction performance for such scenarios, giving rise to a rather general understanding of the potential and the limitations of low-rank matrix models in sensing problems. In this article, we compare the two main proof techniques that have been paving the way to a rigorous analysis, discuss their potential and limitations, and survey their successful applications. On the one hand, we review approaches based on descent cone analysis, showing that they often lead to strong guarantees even in the presence of adversarial noise, but face limitations when it comes to structured observations. On the other hand, we discuss techniques using approximate dual certificates and the golfing scheme, which are often better suited to deal with practical measurement structures, but sometimes lead to weaker guarantees. Lastly, we review recent progress towards analyzing descent cones also for structured scenarios -- exploiting the idea of splitting the cones into multiple parts that are analyzed via different techniques.
Understanding Overparameterization in Generative Adversarial Networks
Apr 12, 2021
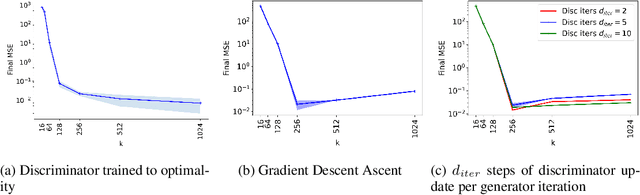
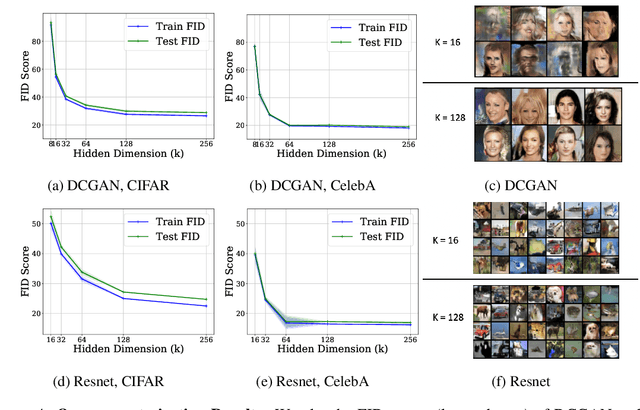
A broad class of unsupervised deep learning methods such as Generative Adversarial Networks (GANs) involve training of overparameterized models where the number of parameters of the model exceeds a certain threshold. A large body of work in supervised learning have shown the importance of model overparameterization in the convergence of the gradient descent (GD) to globally optimal solutions. In contrast, the unsupervised setting and GANs in particular involve non-convex concave mini-max optimization problems that are often trained using Gradient Descent/Ascent (GDA). The role and benefits of model overparameterization in the convergence of GDA to a global saddle point in non-convex concave problems is far less understood. In this work, we present a comprehensive analysis of the importance of model overparameterization in GANs both theoretically and empirically. We theoretically show that in an overparameterized GAN model with a $1$-layer neural network generator and a linear discriminator, GDA converges to a global saddle point of the underlying non-convex concave min-max problem. To the best of our knowledge, this is the first result for global convergence of GDA in such settings. Our theory is based on a more general result that holds for a broader class of nonlinear generators and discriminators that obey certain assumptions (including deeper generators and random feature discriminators). We also empirically study the role of model overparameterization in GANs using several large-scale experiments on CIFAR-10 and Celeb-A datasets. Our experiments show that overparameterization improves the quality of generated samples across various model architectures and datasets. Remarkably, we observe that overparameterization leads to faster and more stable convergence behavior of GDA across the board.
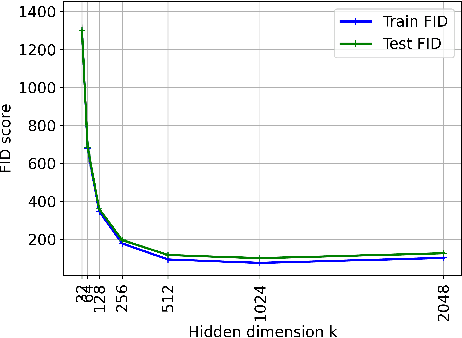
Iteratively Reweighted Least Squares for $\ell_1$-minimization with Global Linear Convergence Rate
Jan 15, 2021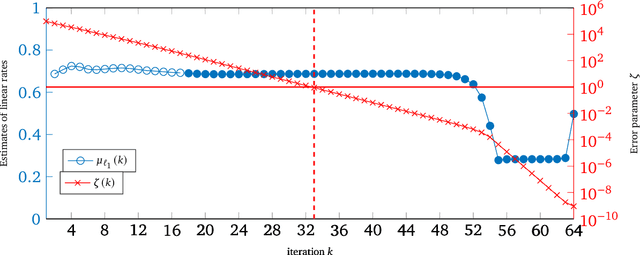
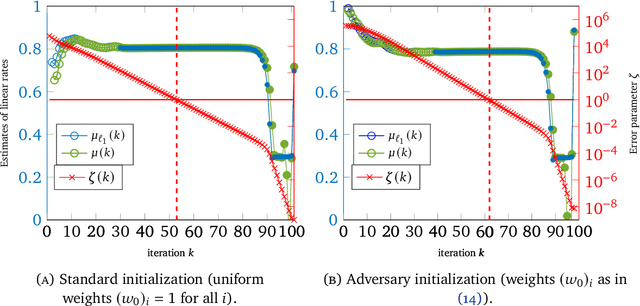
Iteratively Reweighted Least Squares (IRLS), whose history goes back more than 80 years, represents an important family of algorithms for non-smooth optimization as it is able to optimize these problems by solving a sequence of linear systems. In 2010, Daubechies, DeVore, Fornasier, and G\"unt\"urk proved that IRLS for $\ell_1$-minimization, an optimization program ubiquitous in the field of compressed sensing, globally converges to a sparse solution. While this algorithm has been popular in applications in engineering and statistics, fundamental algorithmic questions have remained unanswered. As a matter of fact, existing convergence guarantees only provide global convergence without any rate, except for the case that the support of the underlying signal has already been identified. In this paper, we prove that IRLS for $\ell_1$-minimization converges to a sparse solution with a global linear rate. We support our theory by numerical experiments indicating that our linear rate essentially captures the correct dimension dependence.