 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Failure Modes of Self-Supervised Learning
Mar 03, 2022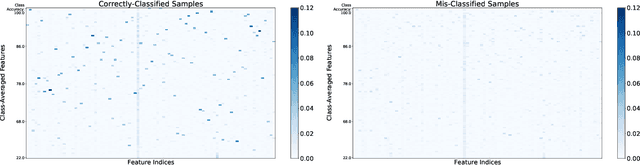
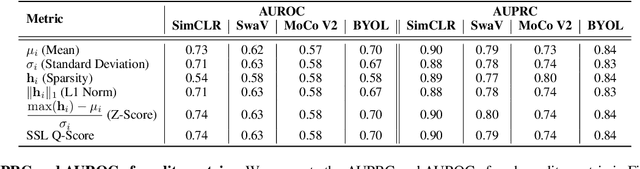
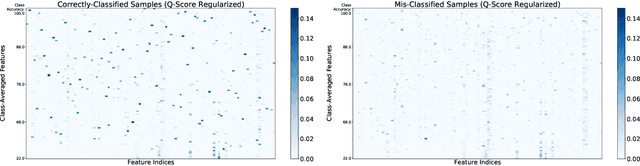
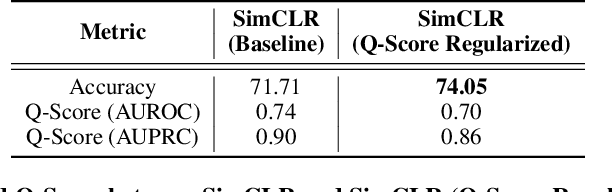
Self-supervised learning methods have shown impressive results in downstream classification tasks. However, there is limited work in understanding their failure models and interpreting the learned representations of these models. In this paper, we tackle these issues and study the representation space of self-supervised models by understanding the underlying reasons for misclassifications in a downstream task. Over several state-of-the-art self-supervised models including SimCLR, SwaV, MoCo V2 and BYOL, we observe that representations of correctly classified samples have few discriminative features with highly deviated values compared to other features. This is in a clear contrast with representations of misclassified samples. We also observe that noisy features in the representation space often correspond to spurious attributes in images making the models less interpretable. Building on these observations, we propose a sample-wise Self-Supervised Representation Quality Score (or, Q-Score) that, without access to any label information, is able to predict if a given sample is likely to be misclassified in the downstream task, achieving an AUPRC of up to 0.90. Q-Score can also be used as a regularization to remedy low-quality representations leading to 3.26% relative improvement in accuracy of SimCLR on ImageNet-100. Moreover, we show that Q-Score regularization increases representation sparsity, thus reducing noise and improving interpretability through gradient heatmaps.
Understanding Overparameterization in Generative Adversarial Networks
Apr 12, 2021
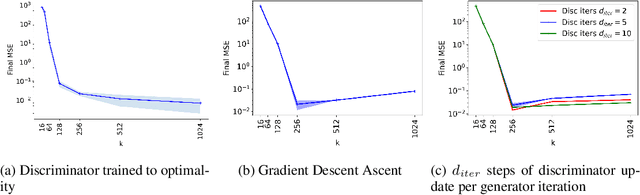
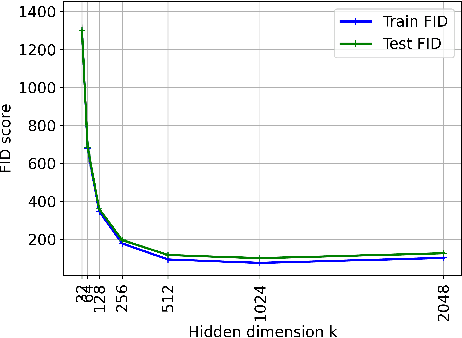
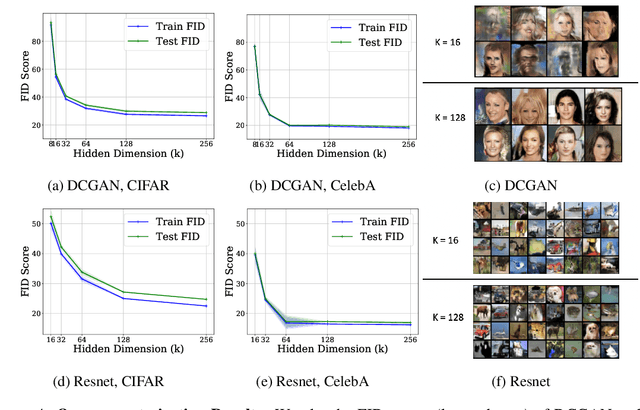
A broad class of unsupervised deep learning methods such as Generative Adversarial Networks (GANs) involve training of overparameterized models where the number of parameters of the model exceeds a certain threshold. A large body of work in supervised learning have shown the importance of model overparameterization in the convergence of the gradient descent (GD) to globally optimal solutions. In contrast, the unsupervised setting and GANs in particular involve non-convex concave mini-max optimization problems that are often trained using Gradient Descent/Ascent (GDA). The role and benefits of model overparameterization in the convergence of GDA to a global saddle point in non-convex concave problems is far less understood. In this work, we present a comprehensive analysis of the importance of model overparameterization in GANs both theoretically and empirically. We theoretically show that in an overparameterized GAN model with a $1$-layer neural network generator and a linear discriminator, GDA converges to a global saddle point of the underlying non-convex concave min-max problem. To the best of our knowledge, this is the first result for global convergence of GDA in such settings. Our theory is based on a more general result that holds for a broader class of nonlinear generators and discriminators that obey certain assumptions (including deeper generators and random feature discriminators). We also empirically study the role of model overparameterization in GANs using several large-scale experiments on CIFAR-10 and Celeb-A datasets. Our experiments show that overparameterization improves the quality of generated samples across various model architectures and datasets. Remarkably, we observe that overparameterization leads to faster and more stable convergence behavior of GDA across the board.
Winning Lottery Tickets in Deep Generative Models
Oct 05, 2020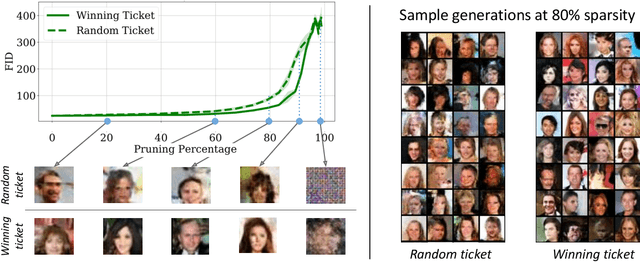
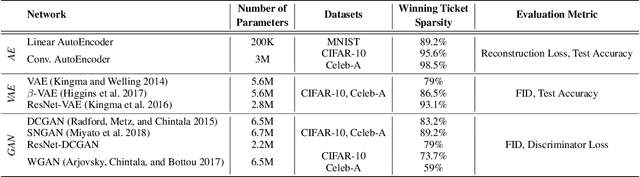
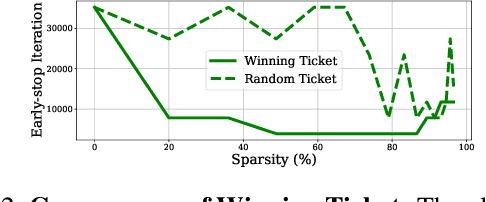
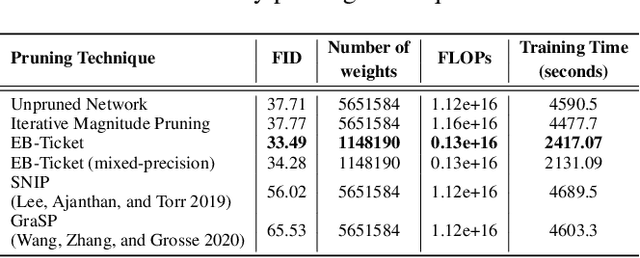
The lottery ticket hypothesis suggests that sparse, sub-networks of a given neural network, if initialized properly, can be trained to reach comparable or even better performance to that of the original network. Prior works in lottery tickets have primarily focused on the supervised learning setup, with several papers proposing effective ways of finding "winning tickets" in classification problems. In this paper, we confirm the existence of winning tickets in deep generative models such as GANs and VAEs. We show that the popular iterative magnitude pruning approach (with late rewinding) can be used with generative losses to find the winning tickets. This approach effectively yields tickets with sparsity up to 99% for AutoEncoders, 93% for VAEs and 89% for GANs on CIFAR and Celeb-A datasets. We also demonstrate the transferability of winning tickets across different generative models (GANs and VAEs) sharing the same architecture, suggesting that winning tickets have inductive biases that could help train a wide range of deep generative models. Furthermore, we show the practical benefits of lottery tickets in generative models by detecting tickets at very early stages in training called "early-bird tickets". Through early-bird tickets, we can achieve up to 88% reduction in floating-point operations (FLOPs) and 54% reduction in training time, making it possible to train large-scale generative models over tight resource constraints. These results out-perform existing early pruning methods like SNIP (Lee, Ajanthan, and Torr 2019) and GraSP (Wang, Zhang, and Grosse 2020). Our findings shed light towards existence of proper network initializations that could improve convergence and stability of generative models.