 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWinning Lottery Tickets in Deep Generative Models
Paper and Code
Oct 05, 2020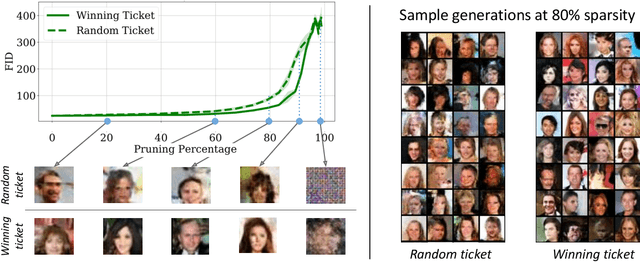
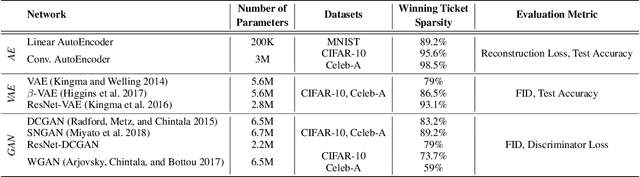
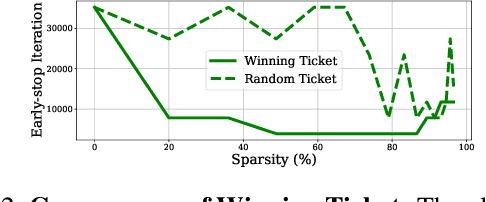
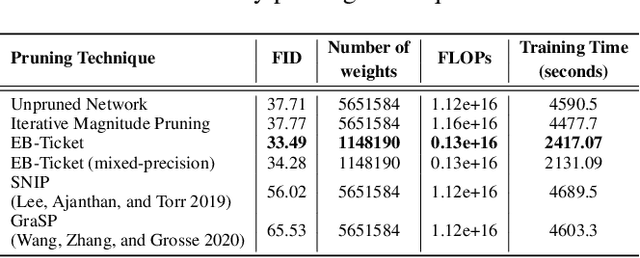
The lottery ticket hypothesis suggests that sparse, sub-networks of a given neural network, if initialized properly, can be trained to reach comparable or even better performance to that of the original network. Prior works in lottery tickets have primarily focused on the supervised learning setup, with several papers proposing effective ways of finding "winning tickets" in classification problems. In this paper, we confirm the existence of winning tickets in deep generative models such as GANs and VAEs. We show that the popular iterative magnitude pruning approach (with late rewinding) can be used with generative losses to find the winning tickets. This approach effectively yields tickets with sparsity up to 99% for AutoEncoders, 93% for VAEs and 89% for GANs on CIFAR and Celeb-A datasets. We also demonstrate the transferability of winning tickets across different generative models (GANs and VAEs) sharing the same architecture, suggesting that winning tickets have inductive biases that could help train a wide range of deep generative models. Furthermore, we show the practical benefits of lottery tickets in generative models by detecting tickets at very early stages in training called "early-bird tickets". Through early-bird tickets, we can achieve up to 88% reduction in floating-point operations (FLOPs) and 54% reduction in training time, making it possible to train large-scale generative models over tight resource constraints. These results out-perform existing early pruning methods like SNIP (Lee, Ajanthan, and Torr 2019) and GraSP (Wang, Zhang, and Grosse 2020). Our findings shed light towards existence of proper network initializations that could improve convergence and stability of generative models.