 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding Failure Modes of Self-Supervised Learning
Paper and Code
Mar 03, 2022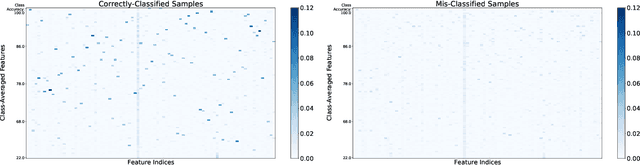
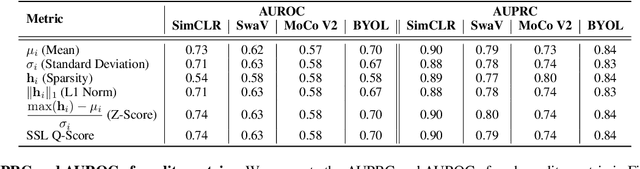
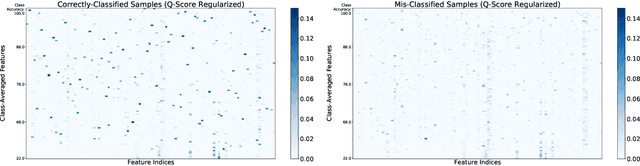
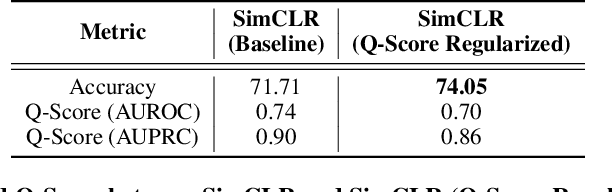
Self-supervised learning methods have shown impressive results in downstream classification tasks. However, there is limited work in understanding their failure models and interpreting the learned representations of these models. In this paper, we tackle these issues and study the representation space of self-supervised models by understanding the underlying reasons for misclassifications in a downstream task. Over several state-of-the-art self-supervised models including SimCLR, SwaV, MoCo V2 and BYOL, we observe that representations of correctly classified samples have few discriminative features with highly deviated values compared to other features. This is in a clear contrast with representations of misclassified samples. We also observe that noisy features in the representation space often correspond to spurious attributes in images making the models less interpretable. Building on these observations, we propose a sample-wise Self-Supervised Representation Quality Score (or, Q-Score) that, without access to any label information, is able to predict if a given sample is likely to be misclassified in the downstream task, achieving an AUPRC of up to 0.90. Q-Score can also be used as a regularization to remedy low-quality representations leading to 3.26% relative improvement in accuracy of SimCLR on ImageNet-100. Moreover, we show that Q-Score regularization increases representation sparsity, thus reducing noise and improving interpretability through gradient heatmaps.