 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ3R: Quadratic Reweighted Rank Regularizer for Effective Low-Rank Training
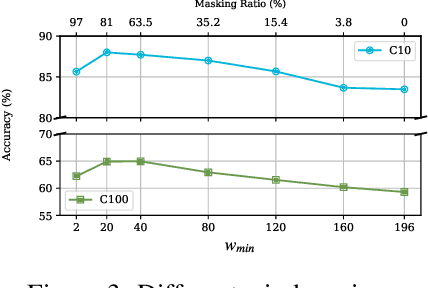
Nov 06, 2025Parameter-efficient training, based on low-rank optimization, has become a highly successful tool for fine-tuning large deep-learning models. However, these methods fail at low-rank pre-training tasks where maintaining the low-rank structure and the objective remains a challenging task. We propose the Quadratic Reweighted Rank Regularizer dubbed Q3R, which leads to a novel low-rank inducing training strategy inspired by the iteratively reweighted least squares (IRLS) framework. Q3R is based on a quadratic regularizer term which majorizes a smoothed log determinant serving as rank surrogate objective. Unlike other low-rank training techniques, Q3R is able to train weight matrices with prescribed, low target ranks of models that achieve comparable predictive performance as dense models, with small computational overhead, while remaining fully compatible with existing architectures. For example, we demonstrated one experiment where we are able to truncate $60\%$ and $80\%$ of the parameters of a ViT-Tiny model with $~1.3\%$ and $~4\%$ accuracy drop in CIFAR-10 performance respectively. The efficacy of Q3R is confirmed on Transformers across both image and language tasks, including for low-rank fine-tuning.
Sample-Efficient Geometry Reconstruction from Euclidean Distances using Non-Convex Optimization
Oct 22, 2024



The problem of finding suitable point embedding or geometric configurations given only Euclidean distance information of point pairs arises both as a core task and as a sub-problem in a variety of machine learning applications. In this paper, we aim to solve this problem given a minimal number of distance samples. To this end, we leverage continuous and non-convex rank minimization formulations of the problem and establish a local convergence guarantee for a variant of iteratively reweighted least squares (IRLS), which applies if a minimal random set of observed distances is provided. As a technical tool, we establish a restricted isometry property (RIP) restricted to a tangent space of the manifold of symmetric rank-$r$ matrices given random Euclidean distance measurements, which might be of independent interest for the analysis of other non-convex approaches. Furthermore, we assess data efficiency, scalability and generalizability of different reconstruction algorithms through numerical experiments with simulated data as well as real-world data, demonstrating the proposed algorithm's ability to identify the underlying geometry from fewer distance samples compared to the state-of-the-art.
Fibottention: Inceptive Visual Representation Learning with Diverse Attention Across Heads
Jun 27, 2024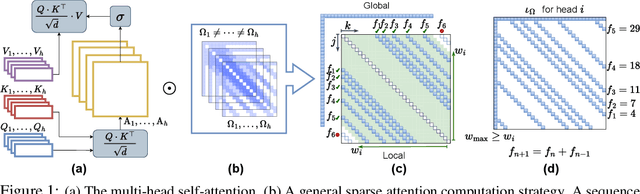


Visual perception tasks are predominantly solved by Vision Transformer (ViT) architectures, which, despite their effectiveness, encounter a computational bottleneck due to the quadratic complexity of computing self-attention. This inefficiency is largely due to the self-attention heads capturing redundant token interactions, reflecting inherent redundancy within visual data. Many works have aimed to reduce the computational complexity of self-attention in ViTs, leading to the development of efficient and sparse transformer architectures. In this paper, viewing through the efficiency lens, we realized that introducing any sparse self-attention strategy in ViTs can keep the computational overhead low. However, these strategies are sub-optimal as they often fail to capture fine-grained visual details. This observation leads us to propose a general, efficient, sparse architecture, named Fibottention, for approximating self-attention with superlinear complexity that is built upon Fibonacci sequences. The key strategies in Fibottention include: it excludes proximate tokens to reduce redundancy, employs structured sparsity by design to decrease computational demands, and incorporates inception-like diversity across attention heads. This diversity ensures the capture of complementary information through non-overlapping token interactions, optimizing both performance and resource utilization in ViTs for visual representation learning. We embed our Fibottention mechanism into multiple state-of-the-art transformer architectures dedicated to visual tasks. Leveraging only 2-6% of the elements in the self-attention heads, Fibottention in conjunction with ViT and its variants, consistently achieves significant performance boosts compared to standard ViTs in nine datasets across three domains $\unicode{x2013}$ image classification, video understanding, and robot learning tasks.
UnitNorm: Rethinking Normalization for Transformers in Time Series
May 24, 2024Normalization techniques are crucial for enhancing Transformer models' performance and stability in time series analysis tasks, yet traditional methods like batch and layer normalization often lead to issues such as token shift, attention shift, and sparse attention. We propose UnitNorm, a novel approach that scales input vectors by their norms and modulates attention patterns, effectively circumventing these challenges. Grounded in existing normalization frameworks, UnitNorm's effectiveness is demonstrated across diverse time series analysis tasks, including forecasting, classification, and anomaly detection, via a rigorous evaluation on 6 state-of-the-art models and 10 datasets. Notably, UnitNorm shows superior performance, especially in scenarios requiring robust attention mechanisms and contextual comprehension, evidenced by significant improvements by up to a 1.46 decrease in MSE for forecasting, and a 4.89% increase in accuracy for classification. This work not only calls for a reevaluation of normalization strategies in time series Transformers but also sets a new direction for enhancing model performance and stability. The source code is available at https://anonymous.4open.science/r/UnitNorm-5B84.
Recovering Simultaneously Structured Data via Non-Convex Iteratively Reweighted Least Squares
Jun 08, 2023We propose a new algorithm for the problem of recovering data that adheres to multiple, heterogeneous low-dimensional structures from linear observations. Focusing on data matrices that are simultaneously row-sparse and low-rank, we propose and analyze an iteratively reweighted least squares (IRLS) algorithm that is able to leverage both structures. In particular, it optimizes a combination of non-convex surrogates for row-sparsity and rank, a balancing of which is built into the algorithm. We prove locally quadratic convergence of the iterates to a simultaneously structured data matrix in a regime of minimal sample complexity (up to constants and a logarithmic factor), which is known to be impossible for a combination of convex surrogates. In experiments, we show that the IRLS method exhibits favorable empirical convergence, identifying simultaneously row-sparse and low-rank matrices from fewer measurements than state-of-the-art methods.
Learning Transition Operators From Sparse Space-Time Samples
Dec 01, 2022We consider the nonlinear inverse problem of learning a transition operator $\mathbf{A}$ from partial observations at different times, in particular from sparse observations of entries of its powers $\mathbf{A},\mathbf{A}^2,\cdots,\mathbf{A}^{T}$. This Spatio-Temporal Transition Operator Recovery problem is motivated by the recent interest in learning time-varying graph signals that are driven by graph operators depending on the underlying graph topology. We address the nonlinearity of the problem by embedding it into a higher-dimensional space of suitable block-Hankel matrices, where it becomes a low-rank matrix completion problem, even if $\mathbf{A}$ is of full rank. For both a uniform and an adaptive random space-time sampling model, we quantify the recoverability of the transition operator via suitable measures of incoherence of these block-Hankel embedding matrices. For graph transition operators these measures of incoherence depend on the interplay between the dynamics and the graph topology. We develop a suitable non-convex iterative reweighted least squares (IRLS) algorithm, establish its quadratic local convergence, and show that, in optimal scenarios, no more than $\mathcal{O}(rn \log(nT))$ space-time samples are sufficient to ensure accurate recovery of a rank-$r$ operator $\mathbf{A}$ of size $n \times n$. This establishes that spatial samples can be substituted by a comparable number of space-time samples. We provide an efficient implementation of the proposed IRLS algorithm with space complexity of order $O(r n T)$ and per-iteration time complexity linear in $n$. Numerical experiments for transition operators based on several graph models confirm that the theoretical findings accurately track empirical phase transitions, and illustrate the applicability and scalability of the proposed algorithm.
A Scalable Second Order Method for Ill-Conditioned Matrix Completion from Few Samples
Jun 03, 2021

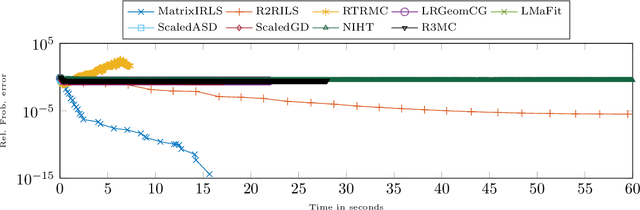
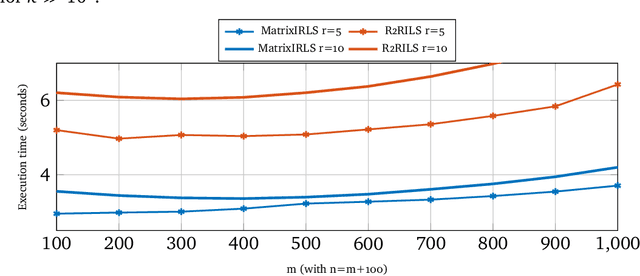
We propose an iterative algorithm for low-rank matrix completion that can be interpreted as an iteratively reweighted least squares (IRLS) algorithm, a saddle-escaping smoothing Newton method or a variable metric proximal gradient method applied to a non-convex rank surrogate. It combines the favorable data-efficiency of previous IRLS approaches with an improved scalability by several orders of magnitude. We establish the first local convergence guarantee from a minimal number of samples for that class of algorithms, showing that the method attains a local quadratic convergence rate. Furthermore, we show that the linear systems to be solved are well-conditioned even for very ill-conditioned ground truth matrices. We provide extensive experiments, indicating that unlike many state-of-the-art approaches, our method is able to complete very ill-conditioned matrices with a condition number of up to $10^{10}$ from few samples, while being competitive in its scalability.
Dictionary-Sparse Recovery From Heavy-Tailed Measurements
Jan 20, 2021The recovery of signals that are sparse not in a basis, but rather sparse with respect to an over-complete dictionary is one of the most flexible settings in the field of compressed sensing with numerous applications. As in the standard compressed sensing setting, it is possible that the signal can be reconstructed efficiently from few, linear measurements, for example by the so-called $\ell_1$-synthesis method. However, it has been less well-understood which measurement matrices provably work for this setting. Whereas in the standard setting, it has been shown that even certain heavy-tailed measurement matrices can be used in the same sample complexity regime as Gaussian matrices, comparable results are only available for the restrictive class of sub-Gaussian measurement vectors as far as the recovery of dictionary-sparse signals via $\ell_1$-synthesis is concerned. In this work, we fill this gap and establish optimal guarantees for the recovery of vectors that are (approximately) sparse with respect to a dictionary via the $\ell_1$-synthesis method from linear, potentially noisy measurements for a large class of random measurement matrices. In particular, we show that random measurements that fulfill only a small-ball assumption and a weak moment assumption, such as random vectors with i.i.d. Student-$t$ entries with a logarithmic number of degrees of freedom, lead to comparable guarantees as (sub-)Gaussian measurements. Our results apply for a large class of both random and deterministic dictionaries. As a corollary of our results, we also obtain a slight improvement on the weakest assumption on a measurement matrix with i.i.d. rows sufficient for uniform recovery in standard compressed sensing, improving on results by Mendelson and Lecu\'e and Dirksen, Lecu\'e and Rauhut.
Iteratively Reweighted Least Squares for $\ell_1$-minimization with Global Linear Convergence Rate
Jan 15, 2021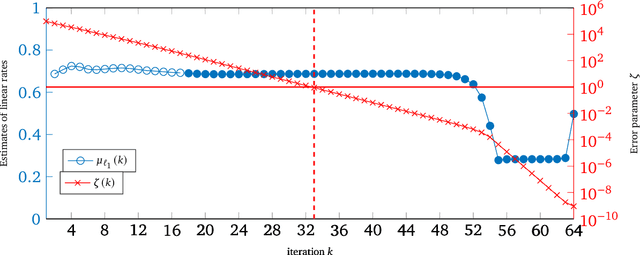
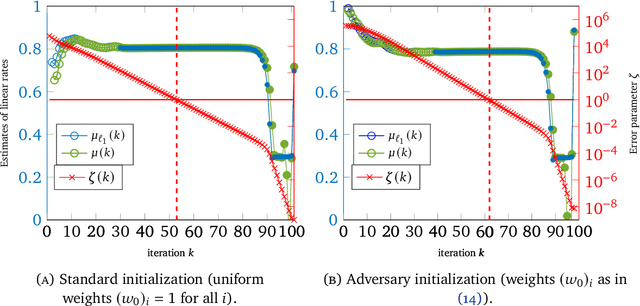
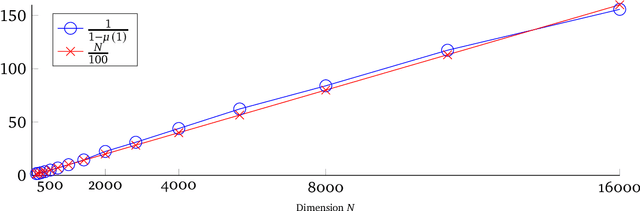
Iteratively Reweighted Least Squares (IRLS), whose history goes back more than 80 years, represents an important family of algorithms for non-smooth optimization as it is able to optimize these problems by solving a sequence of linear systems. In 2010, Daubechies, DeVore, Fornasier, and G\"unt\"urk proved that IRLS for $\ell_1$-minimization, an optimization program ubiquitous in the field of compressed sensing, globally converges to a sparse solution. While this algorithm has been popular in applications in engineering and statistics, fundamental algorithmic questions have remained unanswered. As a matter of fact, existing convergence guarantees only provide global convergence without any rate, except for the case that the support of the underlying signal has already been identified. In this paper, we prove that IRLS for $\ell_1$-minimization converges to a sparse solution with a global linear rate. We support our theory by numerical experiments indicating that our linear rate essentially captures the correct dimension dependence.
Escaping Saddle Points in Ill-Conditioned Matrix Completion with a Scalable Second Order Method
Sep 07, 2020
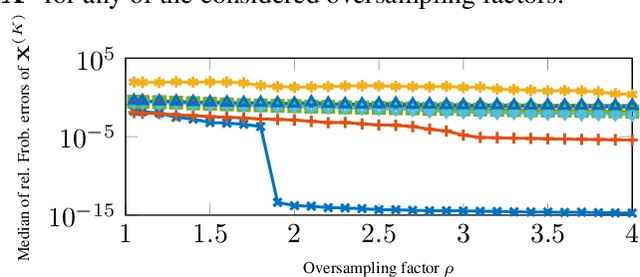


We propose an iterative algorithm for low-rank matrix completion that can be interpreted as both an iteratively reweighted least squares (IRLS) algorithm and a saddle-escaping smoothing Newton method applied to a non-convex rank surrogate objective. It combines the favorable data efficiency of previous IRLS approaches with an improved scalability by several orders of magnitude. Our method attains a local quadratic convergence rate already for a number of samples that is close to the information theoretical limit. We show in numerical experiments that unlike many state-of-the-art approaches, our approach is able to complete very ill-conditioned matrices with a condition number of up to $10^{10}$ from few samples.