 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruthLens:A Training-Free Paradigm for DeepFake Detection
Mar 19, 2025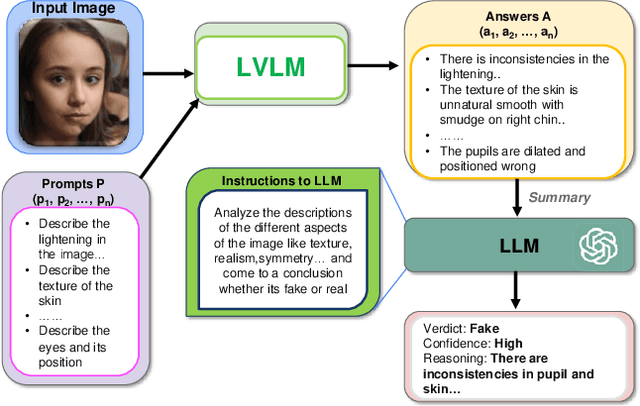
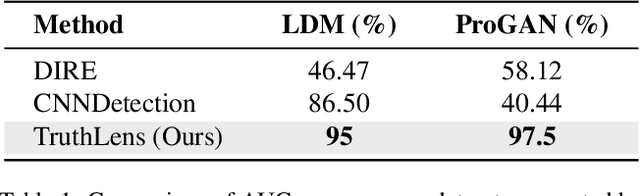

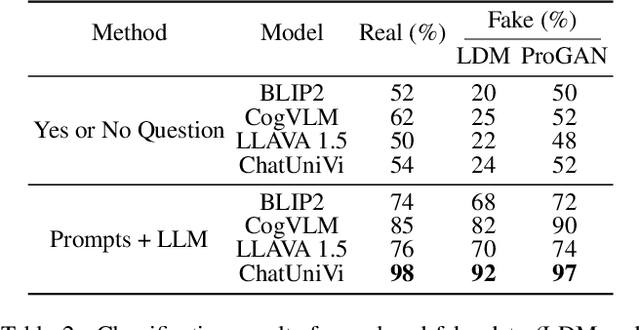
The proliferation of synthetic images generated by advanced AI models poses significant challenges in identifying and understanding manipulated visual content. Current fake image detection methods predominantly rely on binary classification models that focus on accuracy while often neglecting interpretability, leaving users without clear insights into why an image is deemed real or fake. To bridge this gap, we introduce TruthLens, a novel training-free framework that reimagines deepfake detection as a visual question-answering (VQA) task. TruthLens utilizes state-of-the-art large vision-language models (LVLMs) to observe and describe visual artifacts and combines this with the reasoning capabilities of large language models (LLMs) like GPT-4 to analyze and aggregate evidence into informed decisions. By adopting a multimodal approach, TruthLens seamlessly integrates visual and semantic reasoning to not only classify images as real or fake but also provide interpretable explanations for its decisions. This transparency enhances trust and provides valuable insights into the artifacts that signal synthetic content. Extensive evaluations demonstrate that TruthLens outperforms conventional methods, achieving high accuracy on challenging datasets while maintaining a strong emphasis on explainability. By reframing deepfake detection as a reasoning-driven process, TruthLens establishes a new paradigm in combating synthetic media, combining cutting-edge performance with interpretability to address the growing threats of visual disinformation.
Fibottention: Inceptive Visual Representation Learning with Diverse Attention Across Heads
Jun 27, 2024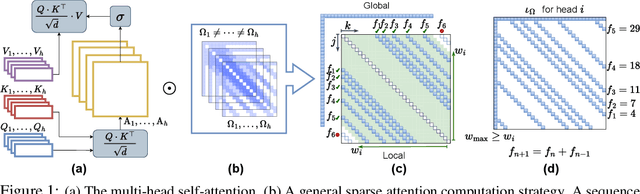


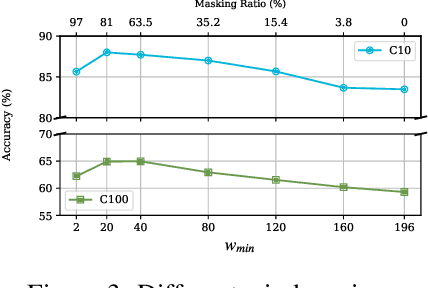
Visual perception tasks are predominantly solved by Vision Transformer (ViT) architectures, which, despite their effectiveness, encounter a computational bottleneck due to the quadratic complexity of computing self-attention. This inefficiency is largely due to the self-attention heads capturing redundant token interactions, reflecting inherent redundancy within visual data. Many works have aimed to reduce the computational complexity of self-attention in ViTs, leading to the development of efficient and sparse transformer architectures. In this paper, viewing through the efficiency lens, we realized that introducing any sparse self-attention strategy in ViTs can keep the computational overhead low. However, these strategies are sub-optimal as they often fail to capture fine-grained visual details. This observation leads us to propose a general, efficient, sparse architecture, named Fibottention, for approximating self-attention with superlinear complexity that is built upon Fibonacci sequences. The key strategies in Fibottention include: it excludes proximate tokens to reduce redundancy, employs structured sparsity by design to decrease computational demands, and incorporates inception-like diversity across attention heads. This diversity ensures the capture of complementary information through non-overlapping token interactions, optimizing both performance and resource utilization in ViTs for visual representation learning. We embed our Fibottention mechanism into multiple state-of-the-art transformer architectures dedicated to visual tasks. Leveraging only 2-6% of the elements in the self-attention heads, Fibottention in conjunction with ViT and its variants, consistently achieves significant performance boosts compared to standard ViTs in nine datasets across three domains $\unicode{x2013}$ image classification, video understanding, and robot learning tasks.