 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFibottention: Inceptive Visual Representation Learning with Diverse Attention Across Heads
Paper and Code
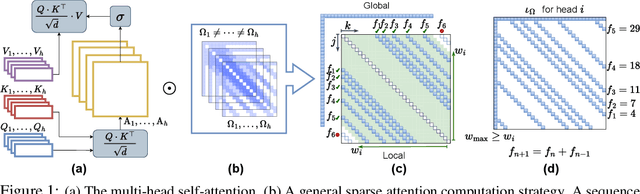


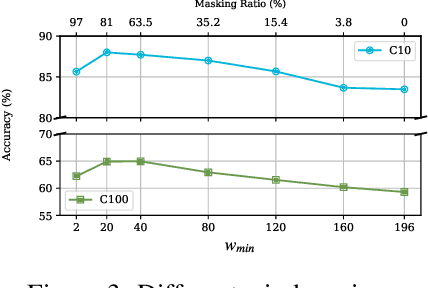
Visual perception tasks are predominantly solved by Vision Transformer (ViT) architectures, which, despite their effectiveness, encounter a computational bottleneck due to the quadratic complexity of computing self-attention. This inefficiency is largely due to the self-attention heads capturing redundant token interactions, reflecting inherent redundancy within visual data. Many works have aimed to reduce the computational complexity of self-attention in ViTs, leading to the development of efficient and sparse transformer architectures. In this paper, viewing through the efficiency lens, we realized that introducing any sparse self-attention strategy in ViTs can keep the computational overhead low. However, these strategies are sub-optimal as they often fail to capture fine-grained visual details. This observation leads us to propose a general, efficient, sparse architecture, named Fibottention, for approximating self-attention with superlinear complexity that is built upon Fibonacci sequences. The key strategies in Fibottention include: it excludes proximate tokens to reduce redundancy, employs structured sparsity by design to decrease computational demands, and incorporates inception-like diversity across attention heads. This diversity ensures the capture of complementary information through non-overlapping token interactions, optimizing both performance and resource utilization in ViTs for visual representation learning. We embed our Fibottention mechanism into multiple state-of-the-art transformer architectures dedicated to visual tasks. Leveraging only 2-6% of the elements in the self-attention heads, Fibottention in conjunction with ViT and its variants, consistently achieves significant performance boosts compared to standard ViTs in nine datasets across three domains $\unicode{x2013}$ image classification, video understanding, and robot learning tasks.