 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom My View to Yours: Ego-Augmented Learning in Large Vision Language Models for Understanding Exocentric Daily Living Activities
Jan 10, 2025



Large Vision Language Models (LVLMs) have demonstrated impressive capabilities in video understanding, yet their adoption for Activities of Daily Living (ADL) remains limited by their inability to capture fine-grained interactions and spatial relationships. This limitation is particularly evident in ADL tasks, where understanding detailed human-object interaction and human-centric motion is crucial for applications such as elderly monitoring and cognitive assessment. To address this, we aim to leverage the complementary nature of egocentric views to enhance LVLM's understanding of exocentric ADL videos. Consequently, we propose an online ego2exo distillation approach to learn ego-augmented exo representations in LVLMs. While effective, this approach requires paired ego-exo training data, which is impractical to collect for real-world ADL scenarios. Consequently, we develop EgoMimic, a skeleton-guided method that can generate mimicked ego views from exocentric videos. We find that the exo representations of our ego-augmented LVLMs successfully learn to extract ego-perspective cues, demonstrated through comprehensive evaluation on six ADL benchmarks and our proposed EgoPerceptionMCQ benchmark designed specifically to assess egocentric understanding from exocentric videos. Code, models, and data will be open-sourced at https://github.com/dominickrei/EgoExo4ADL.
Fibottention: Inceptive Visual Representation Learning with Diverse Attention Across Heads
Jun 27, 2024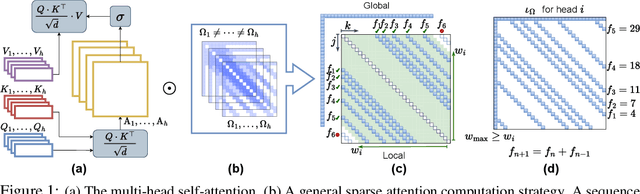


Visual perception tasks are predominantly solved by Vision Transformer (ViT) architectures, which, despite their effectiveness, encounter a computational bottleneck due to the quadratic complexity of computing self-attention. This inefficiency is largely due to the self-attention heads capturing redundant token interactions, reflecting inherent redundancy within visual data. Many works have aimed to reduce the computational complexity of self-attention in ViTs, leading to the development of efficient and sparse transformer architectures. In this paper, viewing through the efficiency lens, we realized that introducing any sparse self-attention strategy in ViTs can keep the computational overhead low. However, these strategies are sub-optimal as they often fail to capture fine-grained visual details. This observation leads us to propose a general, efficient, sparse architecture, named Fibottention, for approximating self-attention with superlinear complexity that is built upon Fibonacci sequences. The key strategies in Fibottention include: it excludes proximate tokens to reduce redundancy, employs structured sparsity by design to decrease computational demands, and incorporates inception-like diversity across attention heads. This diversity ensures the capture of complementary information through non-overlapping token interactions, optimizing both performance and resource utilization in ViTs for visual representation learning. We embed our Fibottention mechanism into multiple state-of-the-art transformer architectures dedicated to visual tasks. Leveraging only 2-6% of the elements in the self-attention heads, Fibottention in conjunction with ViT and its variants, consistently achieves significant performance boosts compared to standard ViTs in nine datasets across three domains $\unicode{x2013}$ image classification, video understanding, and robot learning tasks.
LLAVIDAL: Benchmarking Large Language Vision Models for Daily Activities of Living
Jun 13, 2024Large Language Vision Models (LLVMs) have demonstrated effectiveness in processing internet videos, yet they struggle with the visually perplexing dynamics present in Activities of Daily Living (ADL) due to limited pertinent datasets and models tailored to relevant cues. To this end, we propose a framework for curating ADL multiview datasets to fine-tune LLVMs, resulting in the creation of ADL-X, comprising 100K RGB video-instruction pairs, language descriptions, 3D skeletons, and action-conditioned object trajectories. We introduce LLAVIDAL, an LLVM capable of incorporating 3D poses and relevant object trajectories to understand the intricate spatiotemporal relationships within ADLs. Furthermore, we present a novel benchmark, ADLMCQ, for quantifying LLVM effectiveness in ADL scenarios. When trained on ADL-X, LLAVIDAL consistently achieves state-of-the-art performance across all ADL evaluation metrics. Qualitative analysis reveals LLAVIDAL's temporal reasoning capabilities in understanding ADL. The link to the dataset is provided at: https://adl-x.github.io/