 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinTradeBench: A Financial Reasoning Benchmark for LLMs
Mar 19, 2026Real-world financial decision-making is a challenging problem that requires reasoning over heterogeneous signals, including company fundamentals derived from regulatory filings and trading signals computed from price dynamics. Recently, with the advancement of Large Language Models (LLMs), financial analysts have begun to use them for financial decision-making tasks. However, existing financial question answering benchmarks for testing these models primarily focus on company balance sheet data and rarely evaluate reasoning over how company stocks trade in the market or their interactions with fundamentals. To take advantage of the strengths of both approaches, we introduce FinTradeBench, a benchmark for evaluating financial reasoning that integrates company fundamentals and trading signals. FinTradeBench contains 1,400 questions grounded in NASDAQ-100 companies over a ten-year historical window. The benchmark is organized into three reasoning categories: fundamentals-focused, trading-signal-focused, and hybrid questions requiring cross-signal reasoning. To ensure reliability at scale, we adopt a calibration-then-scaling framework that combines expert seed questions, multi-model response generation, intra-model self-filtering, numerical auditing, and human-LLM judge alignment. We evaluate 14 LLMs under zero-shot prompting and retrieval-augmented settings and witness a clear performance gap. Retrieval substantially improves reasoning over textual fundamentals, but provides limited benefit for trading-signal reasoning. These findings highlight fundamental challenges in the numerical and time-series reasoning for current LLMs and motivate future research in financial intelligence.
NLKI: A lightweight Natural Language Knowledge Integration Framework for Improving Small VLMs in Commonsense VQA Tasks
Aug 28, 2025Commonsense visual-question answering often hinges on knowledge that is missing from the image or the question. Small vision-language models (sVLMs) such as ViLT, VisualBERT and FLAVA therefore lag behind their larger generative counterparts. To study the effect of careful commonsense knowledge integration on sVLMs, we present an end-to-end framework (NLKI) that (i) retrieves natural language facts, (ii) prompts an LLM to craft natural language explanations, and (iii) feeds both signals to sVLMs respectively across two commonsense VQA datasets (CRIC, AOKVQA) and a visual-entailment dataset (e-SNLI-VE). Facts retrieved using a fine-tuned ColBERTv2 and an object information-enriched prompt yield explanations that largely cut down hallucinations, while lifting the end-to-end answer accuracy by up to 7% (across 3 datasets), making FLAVA and other models in NLKI match or exceed medium-sized VLMs such as Qwen-2 VL-2B and SmolVLM-2.5B. As these benchmarks contain 10-25% label noise, additional finetuning using noise-robust losses (such as symmetric cross entropy and generalised cross entropy) adds another 2.5% in CRIC, and 5.5% in AOKVQA. Our findings expose when LLM-based commonsense knowledge beats retrieval from commonsense knowledge bases, how noise-aware training stabilises small models in the context of external knowledge augmentation, and why parameter-efficient commonsense reasoning is now within reach for 250M models.
GAEA: A Geolocation Aware Conversational Model
Mar 20, 2025



Image geolocalization, in which, traditionally, an AI model predicts the precise GPS coordinates of an image is a challenging task with many downstream applications. However, the user cannot utilize the model to further their knowledge other than the GPS coordinate; the model lacks an understanding of the location and the conversational ability to communicate with the user. In recent days, with tremendous progress of large multimodal models (LMMs) proprietary and open-source researchers have attempted to geolocalize images via LMMs. However, the issues remain unaddressed; beyond general tasks, for more specialized downstream tasks, one of which is geolocalization, LMMs struggle. In this work, we propose to solve this problem by introducing a conversational model GAEA that can provide information regarding the location of an image, as required by a user. No large-scale dataset enabling the training of such a model exists. Thus we propose a comprehensive dataset GAEA with 800K images and around 1.6M question answer pairs constructed by leveraging OpenStreetMap (OSM) attributes and geographical context clues. For quantitative evaluation, we propose a diverse benchmark comprising 4K image-text pairs to evaluate conversational capabilities equipped with diverse question types. We consider 11 state-of-the-art open-source and proprietary LMMs and demonstrate that GAEA significantly outperforms the best open-source model, LLaVA-OneVision by 25.69% and the best proprietary model, GPT-4o by 8.28%. Our dataset, model and codes are available
Kolmogorov-Arnold Attention: Is Learnable Attention Better For Vision Transformers?
Mar 13, 2025



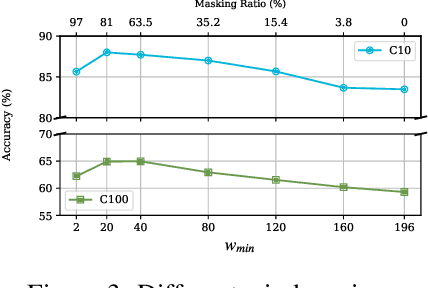
Kolmogorov-Arnold networks (KANs) are a remarkable innovation consisting of learnable activation functions with the potential to capture more complex relationships from data. Although KANs are useful in finding symbolic representations and continual learning of one-dimensional functions, their effectiveness in diverse machine learning (ML) tasks, such as vision, remains questionable. Presently, KANs are deployed by replacing multilayer perceptrons (MLPs) in deep network architectures, including advanced architectures such as vision Transformers (ViTs). In this paper, we are the first to design a general learnable Kolmogorov-Arnold Attention (KArAt) for vanilla ViTs that can operate on any choice of basis. However, the computing and memory costs of training them motivated us to propose a more modular version, and we designed particular learnable attention, called Fourier-KArAt. Fourier-KArAt and its variants either outperform their ViT counterparts or show comparable performance on CIFAR-10, CIFAR-100, and ImageNet-1K datasets. We dissect these architectures' performance and generalization capacity by analyzing their loss landscapes, weight distributions, optimizer path, attention visualization, and spectral behavior, and contrast them with vanilla ViTs. The goal of this paper is not to produce parameter- and compute-efficient attention, but to encourage the community to explore KANs in conjunction with more advanced architectures that require a careful understanding of learnable activations. Our open-source code and implementation details are available on: https://subhajitmaity.me/KArAt
Fibottention: Inceptive Visual Representation Learning with Diverse Attention Across Heads
Jun 27, 2024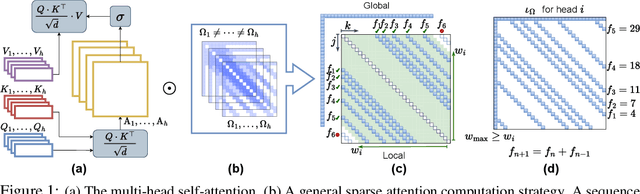


Visual perception tasks are predominantly solved by Vision Transformer (ViT) architectures, which, despite their effectiveness, encounter a computational bottleneck due to the quadratic complexity of computing self-attention. This inefficiency is largely due to the self-attention heads capturing redundant token interactions, reflecting inherent redundancy within visual data. Many works have aimed to reduce the computational complexity of self-attention in ViTs, leading to the development of efficient and sparse transformer architectures. In this paper, viewing through the efficiency lens, we realized that introducing any sparse self-attention strategy in ViTs can keep the computational overhead low. However, these strategies are sub-optimal as they often fail to capture fine-grained visual details. This observation leads us to propose a general, efficient, sparse architecture, named Fibottention, for approximating self-attention with superlinear complexity that is built upon Fibonacci sequences. The key strategies in Fibottention include: it excludes proximate tokens to reduce redundancy, employs structured sparsity by design to decrease computational demands, and incorporates inception-like diversity across attention heads. This diversity ensures the capture of complementary information through non-overlapping token interactions, optimizing both performance and resource utilization in ViTs for visual representation learning. We embed our Fibottention mechanism into multiple state-of-the-art transformer architectures dedicated to visual tasks. Leveraging only 2-6% of the elements in the self-attention heads, Fibottention in conjunction with ViT and its variants, consistently achieves significant performance boosts compared to standard ViTs in nine datasets across three domains $\unicode{x2013}$ image classification, video understanding, and robot learning tasks.
Towards Multi-modal Transformers in Federated Learning
Apr 18, 2024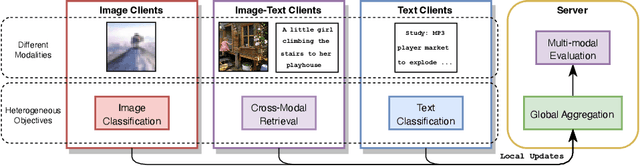
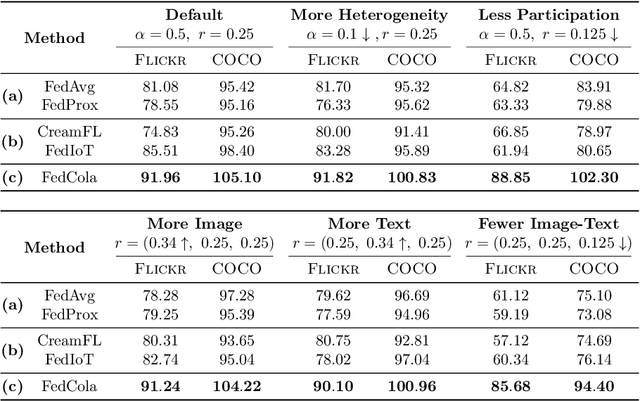
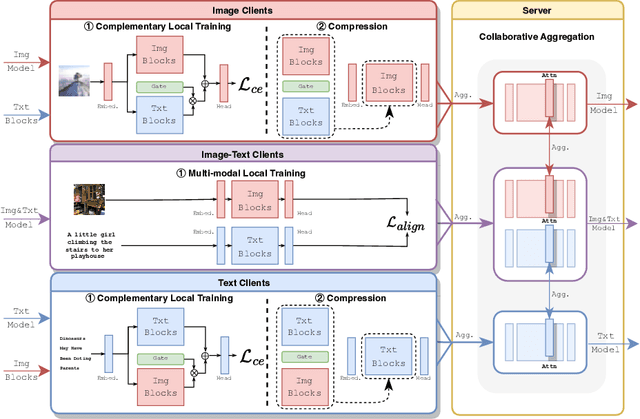
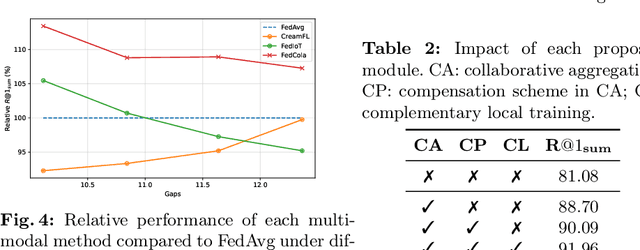
Multi-modal transformers mark significant progress in different domains, but siloed high-quality data hinders their further improvement. To remedy this, federated learning (FL) has emerged as a promising privacy-preserving paradigm for training models without direct access to the raw data held by different clients. Despite its potential, a considerable research direction regarding the unpaired uni-modal clients and the transformer architecture in FL remains unexplored. To fill this gap, this paper explores a transfer multi-modal federated learning (MFL) scenario within the vision-language domain, where clients possess data of various modalities distributed across different datasets. We systematically evaluate the performance of existing methods when a transformer architecture is utilized and introduce a novel framework called Federated modality complementary and collaboration (FedCola) by addressing the in-modality and cross-modality gaps among clients. Through extensive experiments across various FL settings, FedCola demonstrates superior performance over previous approaches, offering new perspectives on future federated training of multi-modal transformers.
Robust Multi-Modal Image Stitching for Improved Scene Understanding
Dec 28, 2023Multi-modal image stitching can be a difficult feat. That's why, in this paper, we've devised a unique and comprehensive image-stitching pipeline that taps into OpenCV's stitching module. Our approach integrates feature-based matching, transformation estimation, and blending techniques to bring about panoramic views that are of top-tier quality - irrespective of lighting, scale or orientation differences between images. We've put our pipeline to the test with a varied dataset and found that it's very effective in enhancing scene understanding and finding real-world applications.
Multiview Aerial Visual Recognition (MAVREC): Can Multi-view Improve Aerial Visual Perception?
Dec 07, 2023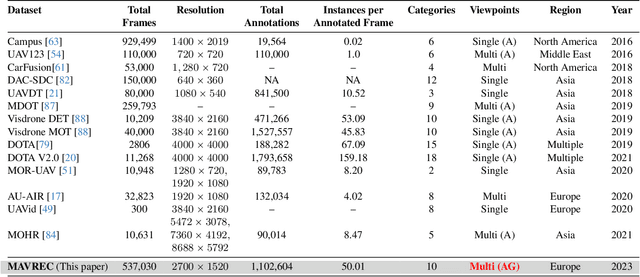
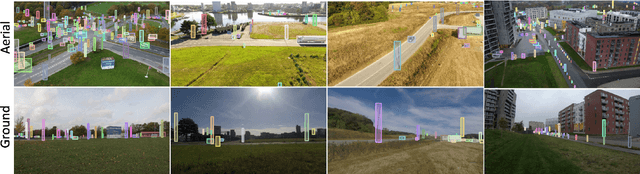
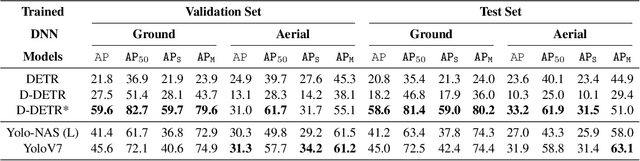
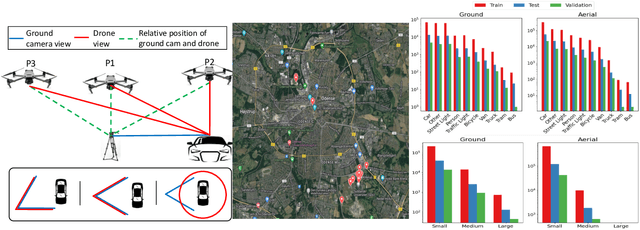
Despite the commercial abundance of UAVs, aerial data acquisition remains challenging, and the existing Asia and North America-centric open-source UAV datasets are small-scale or low-resolution and lack diversity in scene contextuality. Additionally, the color content of the scenes, solar-zenith angle, and population density of different geographies influence the data diversity. These two factors conjointly render suboptimal aerial-visual perception of the deep neural network (DNN) models trained primarily on the ground-view data, including the open-world foundational models. To pave the way for a transformative era of aerial detection, we present Multiview Aerial Visual RECognition or MAVREC, a video dataset where we record synchronized scenes from different perspectives -- ground camera and drone-mounted camera. MAVREC consists of around 2.5 hours of industry-standard 2.7K resolution video sequences, more than 0.5 million frames, and 1.1 million annotated bounding boxes. This makes MAVREC the largest ground and aerial-view dataset, and the fourth largest among all drone-based datasets across all modalities and tasks. Through our extensive benchmarking on MAVREC, we recognize that augmenting object detectors with ground-view images from the corresponding geographical location is a superior pre-training strategy for aerial detection. Building on this strategy, we benchmark MAVREC with a curriculum-based semi-supervised object detection approach that leverages labeled (ground and aerial) and unlabeled (only aerial) images to enhance the aerial detection. We publicly release the MAVREC dataset: https://mavrec.github.io.
Demystifying the Myths and Legends of Nonconvex Convergence of SGD
Oct 19, 2023
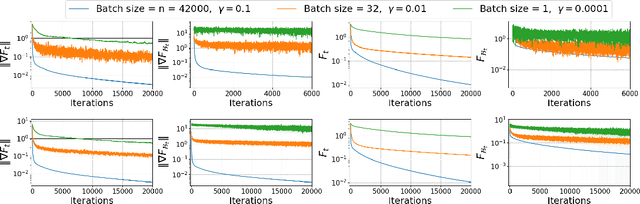
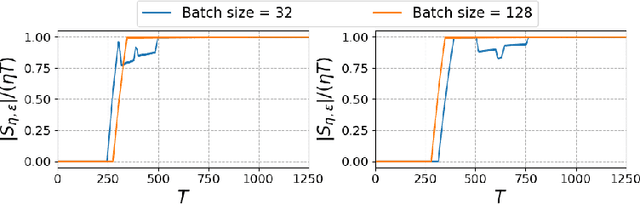

Stochastic gradient descent (SGD) and its variants are the main workhorses for solving large-scale optimization problems with nonconvex objective functions. Although the convergence of SGDs in the (strongly) convex case is well-understood, their convergence for nonconvex functions stands on weak mathematical foundations. Most existing studies on the nonconvex convergence of SGD show the complexity results based on either the minimum of the expected gradient norm or the functional sub-optimality gap (for functions with extra structural property) by searching the entire range of iterates. Hence the last iterations of SGDs do not necessarily maintain the same complexity guarantee. This paper shows that an $\epsilon$-stationary point exists in the final iterates of SGDs, given a large enough total iteration budget, $T$, not just anywhere in the entire range of iterates -- a much stronger result than the existing one. Additionally, our analyses allow us to measure the density of the $\epsilon$-stationary points in the final iterates of SGD, and we recover the classical $O(\frac{1}{\sqrt{T}})$ asymptotic rate under various existing assumptions on the objective function and the bounds on the stochastic gradient. As a result of our analyses, we addressed certain myths and legends related to the nonconvex convergence of SGD and posed some thought-provoking questions that could set new directions for research.
A Note on Randomized Kaczmarz Algorithm for Solving Doubly-Noisy Linear Systems
Aug 31, 2023
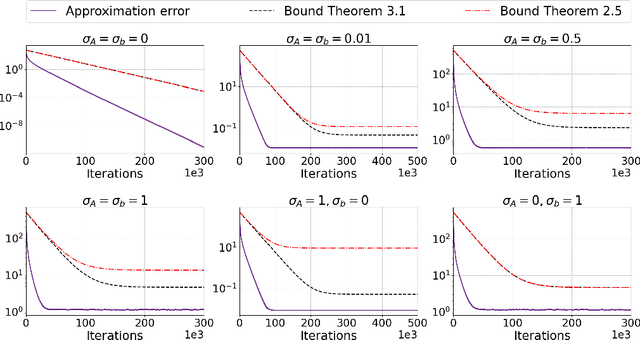
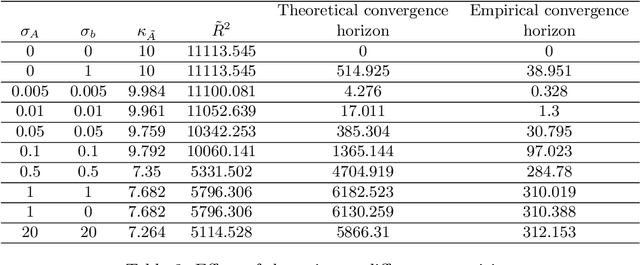
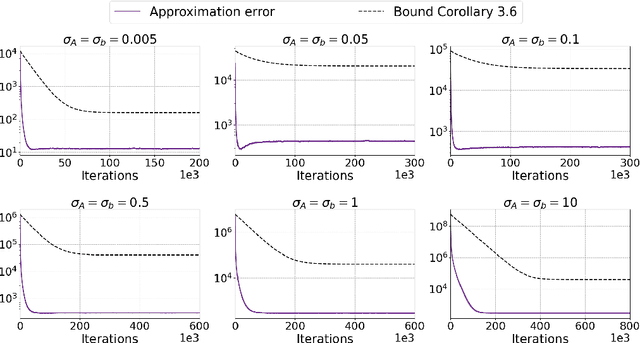
Large-scale linear systems, $Ax=b$, frequently arise in practice and demand effective iterative solvers. Often, these systems are noisy due to operational errors or faulty data-collection processes. In the past decade, the randomized Kaczmarz (RK) algorithm has been studied extensively as an efficient iterative solver for such systems. However, the convergence study of RK in the noisy regime is limited and considers measurement noise in the right-hand side vector, $b$. Unfortunately, in practice, that is not always the case; the coefficient matrix $A$ can also be noisy. In this paper, we analyze the convergence of RK for noisy linear systems when the coefficient matrix, $A$, is corrupted with both additive and multiplicative noise, along with the noisy vector, $b$. In our analyses, the quantity $\tilde R=\| \tilde A^{\dagger} \|_2^2 \|\tilde A \|_F^2$ influences the convergence of RK, where $\tilde A$ represents a noisy version of $A$. We claim that our analysis is robust and realistically applicable, as we do not require information about the noiseless coefficient matrix, $A$, and considering different conditions on noise, we can control the convergence of RK. We substantiate our theoretical findings by performing comprehensive numerical experiments.