 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying the Myths and Legends of Nonconvex Convergence of SGD
Oct 19, 2023
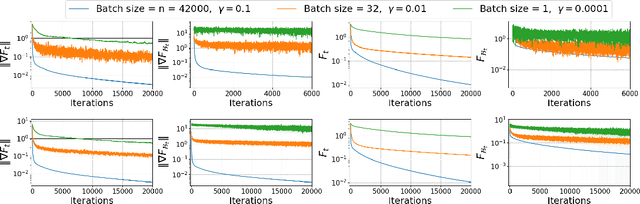
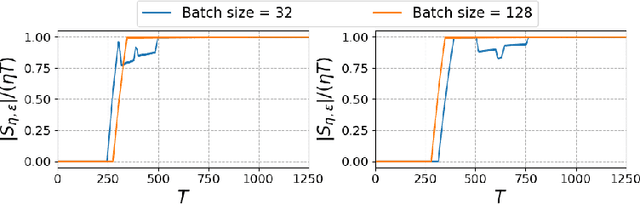

Stochastic gradient descent (SGD) and its variants are the main workhorses for solving large-scale optimization problems with nonconvex objective functions. Although the convergence of SGDs in the (strongly) convex case is well-understood, their convergence for nonconvex functions stands on weak mathematical foundations. Most existing studies on the nonconvex convergence of SGD show the complexity results based on either the minimum of the expected gradient norm or the functional sub-optimality gap (for functions with extra structural property) by searching the entire range of iterates. Hence the last iterations of SGDs do not necessarily maintain the same complexity guarantee. This paper shows that an $\epsilon$-stationary point exists in the final iterates of SGDs, given a large enough total iteration budget, $T$, not just anywhere in the entire range of iterates -- a much stronger result than the existing one. Additionally, our analyses allow us to measure the density of the $\epsilon$-stationary points in the final iterates of SGD, and we recover the classical $O(\frac{1}{\sqrt{T}})$ asymptotic rate under various existing assumptions on the objective function and the bounds on the stochastic gradient. As a result of our analyses, we addressed certain myths and legends related to the nonconvex convergence of SGD and posed some thought-provoking questions that could set new directions for research.
A Note on Randomized Kaczmarz Algorithm for Solving Doubly-Noisy Linear Systems
Aug 31, 2023
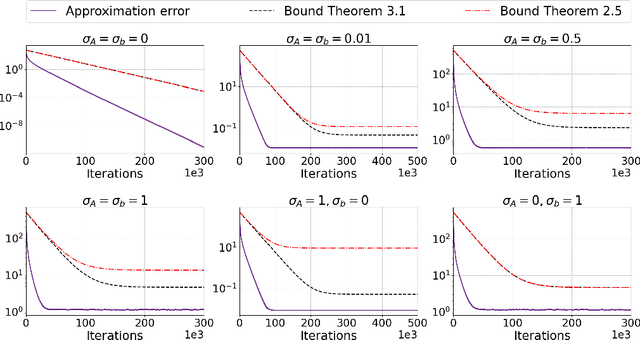
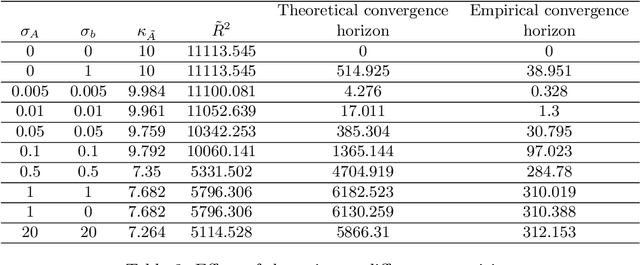
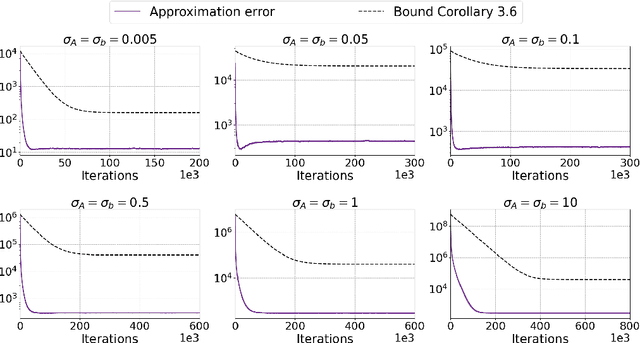
Large-scale linear systems, $Ax=b$, frequently arise in practice and demand effective iterative solvers. Often, these systems are noisy due to operational errors or faulty data-collection processes. In the past decade, the randomized Kaczmarz (RK) algorithm has been studied extensively as an efficient iterative solver for such systems. However, the convergence study of RK in the noisy regime is limited and considers measurement noise in the right-hand side vector, $b$. Unfortunately, in practice, that is not always the case; the coefficient matrix $A$ can also be noisy. In this paper, we analyze the convergence of RK for noisy linear systems when the coefficient matrix, $A$, is corrupted with both additive and multiplicative noise, along with the noisy vector, $b$. In our analyses, the quantity $\tilde R=\| \tilde A^{\dagger} \|_2^2 \|\tilde A \|_F^2$ influences the convergence of RK, where $\tilde A$ represents a noisy version of $A$. We claim that our analysis is robust and realistically applicable, as we do not require information about the noiseless coefficient matrix, $A$, and considering different conditions on noise, we can control the convergence of RK. We substantiate our theoretical findings by performing comprehensive numerical experiments.
Minibatch Stochastic Three Points Method for Unconstrained Smooth Minimization
Sep 16, 2022
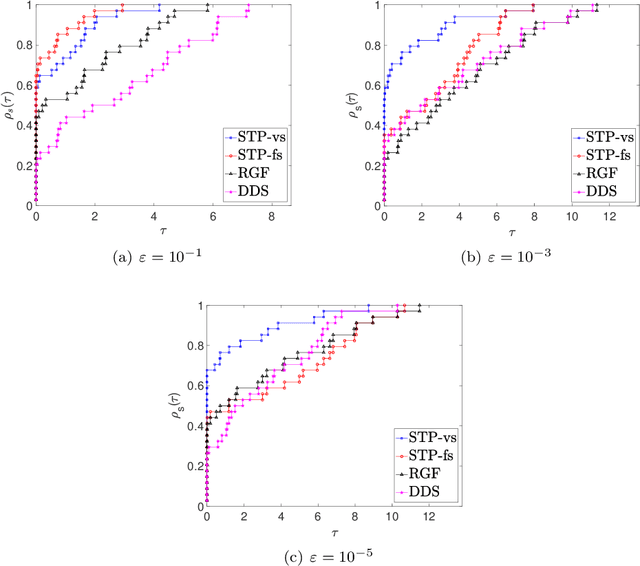
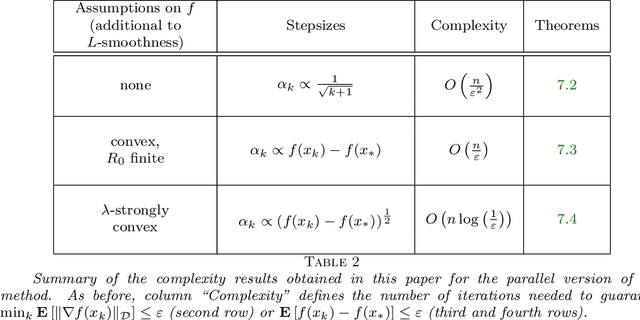
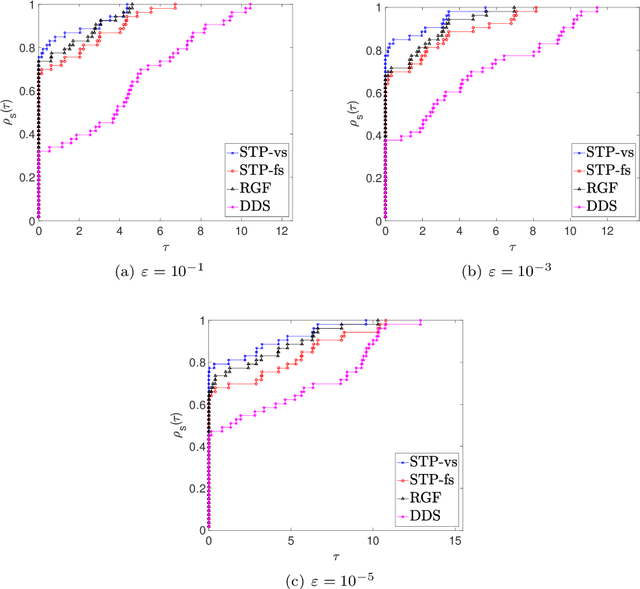
In this paper, we propose a new zero order optimization method called minibatch stochastic three points (MiSTP) method to solve an unconstrained minimization problem in a setting where only an approximation of the objective function evaluation is possible. It is based on the recently proposed stochastic three points (STP) method (Bergou et al., 2020). At each iteration, MiSTP generates a random search direction in a similar manner to STP, but chooses the next iterate based solely on the approximation of the objective function rather than its exact evaluations. We also analyze our method's complexity in the nonconvex and convex cases and evaluate its performance on multiple machine learning tasks.