 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWedge Sampling: Efficient Tensor Completion with Nearly-Linear Sample Complexity
Feb 05, 2026We introduce Wedge Sampling, a new non-adaptive sampling scheme for low-rank tensor completion. We study recovery of an order-$k$ low-rank tensor of dimension $n \times \cdots \times n$ from a subset of its entries. Unlike the standard uniform entry model (i.e., i.i.d. samples from $[n]^k$), wedge sampling allocates observations to structured length-two patterns (wedges) in an associated bipartite sampling graph. By directly promoting these length-two connections, the sampling design strengthens the spectral signal that underlies efficient initialization, in regimes where uniform sampling is too sparse to generate enough informative correlations. Our main result shows that this change in sampling paradigm enables polynomial-time algorithms to achieve both weak and exact recovery with nearly linear sample complexity in $n$. The approach is also plug-and-play: wedge-sampling-based spectral initialization can be combined with existing refinement procedures (e.g., spectral or gradient-based methods) using only an additional $\tilde{O}(n)$ uniformly sampled entries, substantially improving over the $\tilde{O}(n^{k/2})$ sample complexity typically required under uniform entry sampling for efficient methods. Overall, our results suggest that the statistical-to-computational gap highlighted in Barak and Moitra (2022) is, to a large extent, a consequence of the uniform entry sampling model for tensor completion, and that alternative non-adaptive measurement designs that guarantee a strong initialization can overcome this barrier.
A Note on Randomized Kaczmarz Algorithm for Solving Doubly-Noisy Linear Systems
Aug 31, 2023
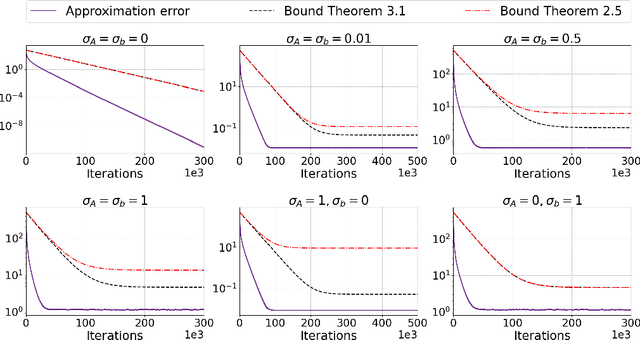
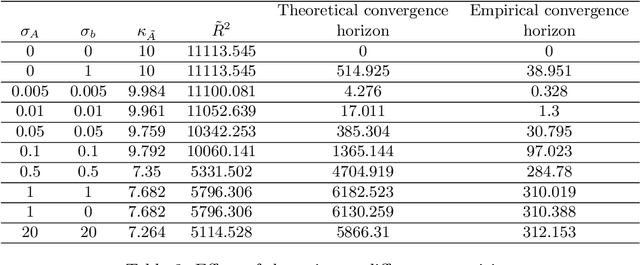
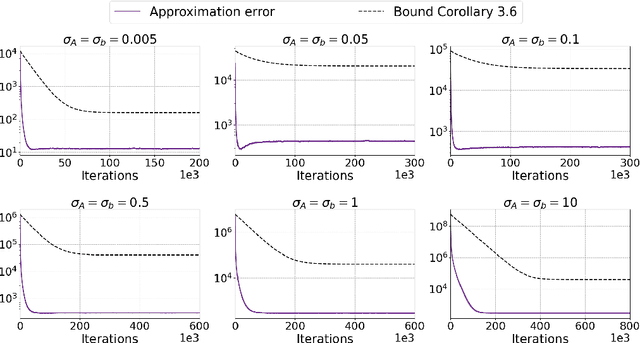
Large-scale linear systems, $Ax=b$, frequently arise in practice and demand effective iterative solvers. Often, these systems are noisy due to operational errors or faulty data-collection processes. In the past decade, the randomized Kaczmarz (RK) algorithm has been studied extensively as an efficient iterative solver for such systems. However, the convergence study of RK in the noisy regime is limited and considers measurement noise in the right-hand side vector, $b$. Unfortunately, in practice, that is not always the case; the coefficient matrix $A$ can also be noisy. In this paper, we analyze the convergence of RK for noisy linear systems when the coefficient matrix, $A$, is corrupted with both additive and multiplicative noise, along with the noisy vector, $b$. In our analyses, the quantity $\tilde R=\| \tilde A^{\dagger} \|_2^2 \|\tilde A \|_F^2$ influences the convergence of RK, where $\tilde A$ represents a noisy version of $A$. We claim that our analysis is robust and realistically applicable, as we do not require information about the noiseless coefficient matrix, $A$, and considering different conditions on noise, we can control the convergence of RK. We substantiate our theoretical findings by performing comprehensive numerical experiments.
Stochastic Natural Thresholding Algorithms
Jun 07, 2023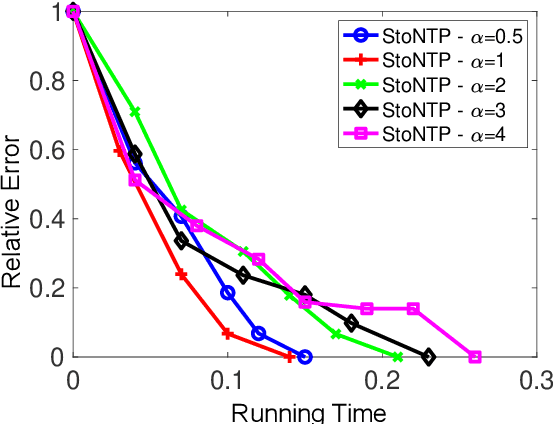
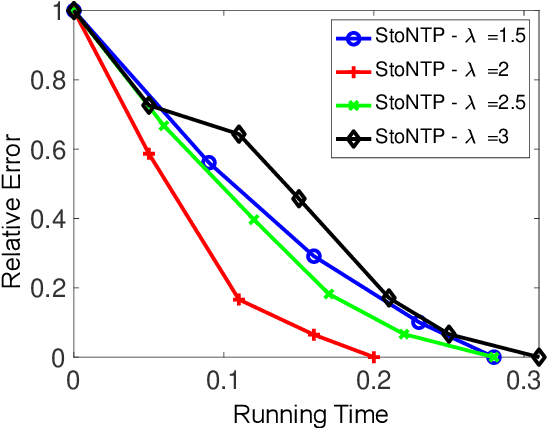
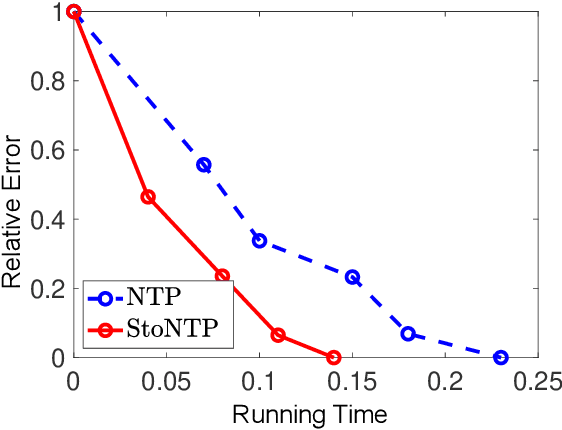
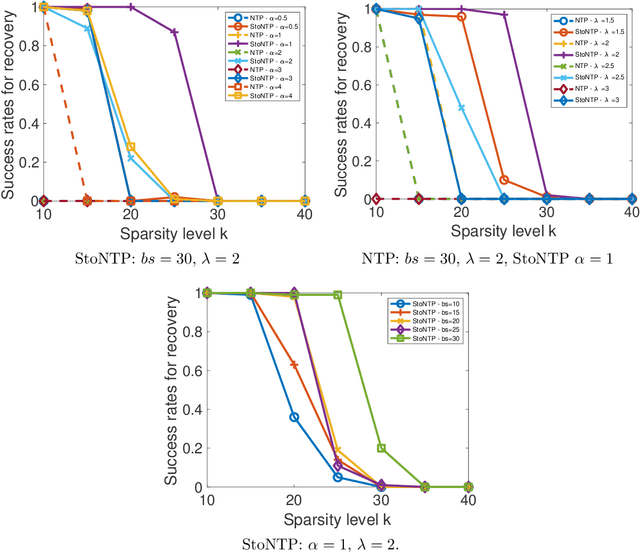
Sparse signal recovery is one of the most fundamental problems in various applications, including medical imaging and remote sensing. Many greedy algorithms based on the family of hard thresholding operators have been developed to solve the sparse signal recovery problem. More recently, Natural Thresholding (NT) has been proposed with improved computational efficiency. This paper proposes and discusses convergence guarantees for stochastic natural thresholding algorithms by extending the NT from the deterministic version with linear measurements to the stochastic version with a general objective function. We also conduct various numerical experiments on linear and nonlinear measurements to demonstrate the performance of StoNT.
Efficient and Robust Bayesian Selection of Hyperparameters in Dimension Reduction for Visualization
Jun 01, 2023



We introduce an efficient and robust auto-tuning framework for hyperparameter selection in dimension reduction (DR) algorithms, focusing on large-scale datasets and arbitrary performance metrics. By leveraging Bayesian optimization (BO) with a surrogate model, our approach enables efficient hyperparameter selection with multi-objective trade-offs and allows us to perform data-driven sensitivity analysis. By incorporating normalization and subsampling, the proposed framework demonstrates versatility and efficiency, as shown in applications to visualization techniques such as t-SNE and UMAP. We evaluate our results on various synthetic and real-world datasets using multiple quality metrics, providing a robust and efficient solution for hyperparameter selection in DR algorithms.
AVIDA: Alternating method for Visualizing and Integrating Data
May 31, 2022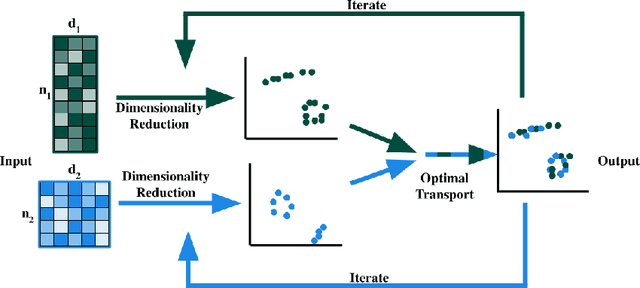
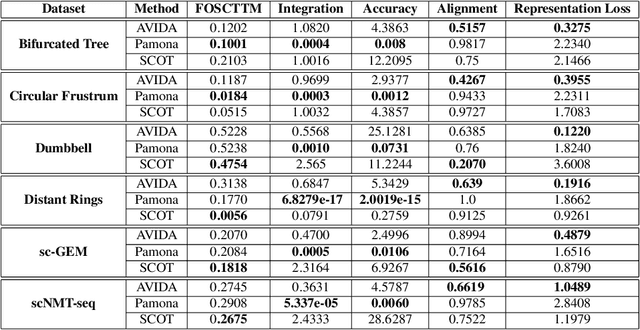
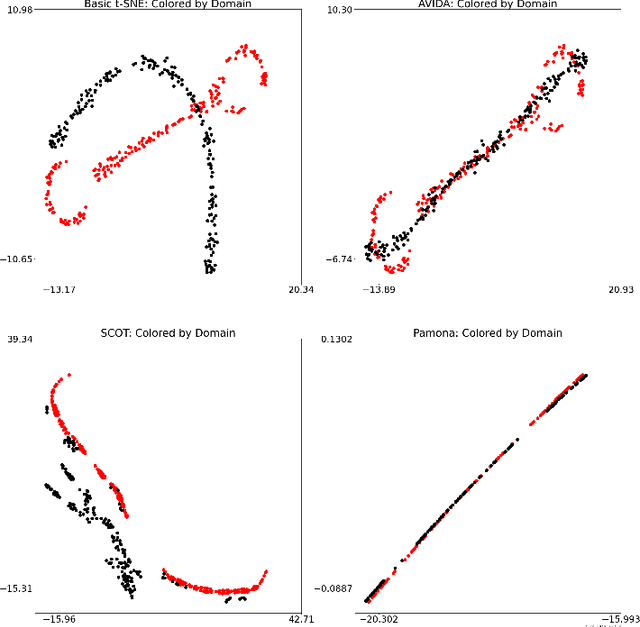
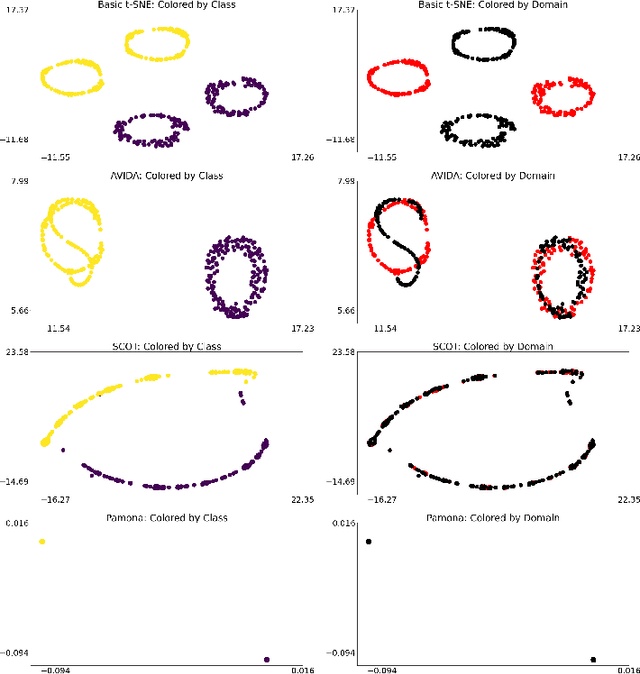
High-dimensional multimodal data arises in many scientific fields. The integration of multimodal data becomes challenging when there is no known correspondence between the samples and the features of different datasets. To tackle this challenge, we introduce AVIDA, a framework for simultaneously performing data alignment and dimension reduction. In the numerical experiments, Gromov-Wasserstein optimal transport and t-distributed stochastic neighbor embedding are used as the alignment and dimension reduction modules respectively. We show that AVIDA correctly aligns high-dimensional datasets without common features with four synthesized datasets and two real multimodal single-cell datasets. Compared to several existing methods, we demonstrate that AVIDA better preserves structures of individual datasets, especially distinct local structures in the joint low-dimensional visualization, while achieving comparable alignment performance. Such a property is important in multimodal single-cell data analysis as some biological processes are uniquely captured by one of the datasets. In general applications, other methods can be used for the alignment and dimension reduction modules.
Iterative Hard Thresholding for Low CP-rank Tensor Models
Aug 22, 2019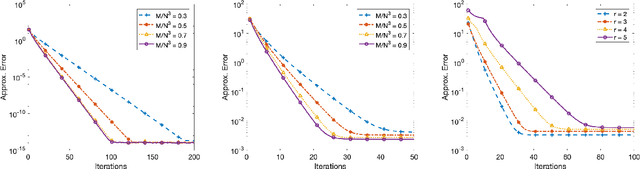
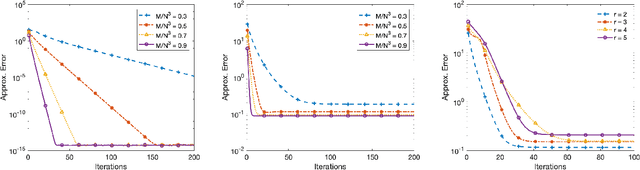
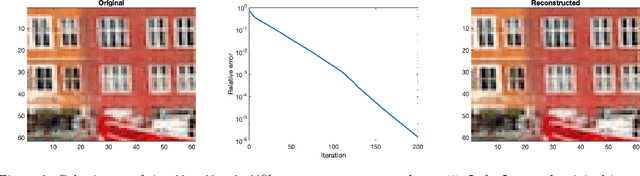
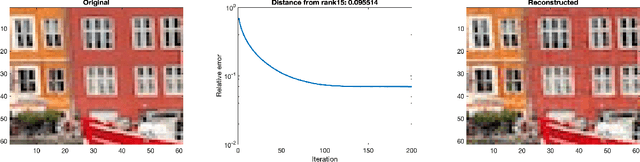
Recovery of low-rank matrices from a small number of linear measurements is now well-known to be possible under various model assumptions on the measurements. Such results demonstrate robustness and are backed with provable theoretical guarantees. However, extensions to tensor recovery have only recently began to be studied and developed, despite an abundance of practical tensor applications. Recently, a tensor variant of the Iterative Hard Thresholding method was proposed and theoretical results were obtained that guarantee exact recovery of tensors with low Tucker rank. In this paper, we utilize the same tensor version of the Restricted Isometry Property (RIP) to extend these results for tensors with low CANDECOMP/PARAFAC (CP) rank. In doing so, we leverage recent results on efficient approximations of CP decompositions that remove the need for challenging assumptions in prior works. We complement our theoretical findings with empirical results that showcase the potential of the approach.
Data-driven Algorithm Selection and Parameter Tuning: Two Case studies in Optimization and Signal Processing
May 31, 2019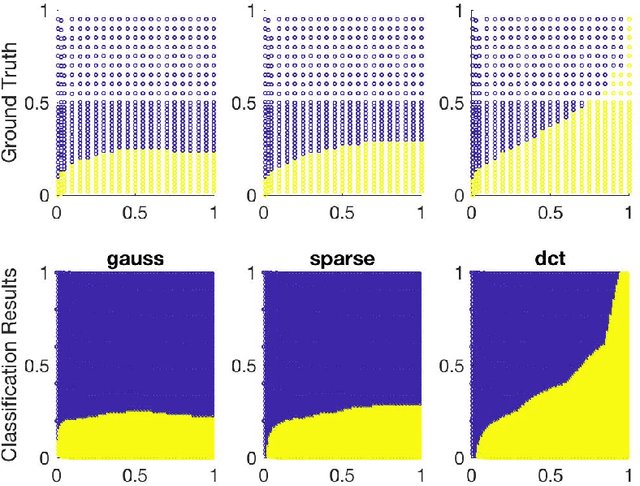

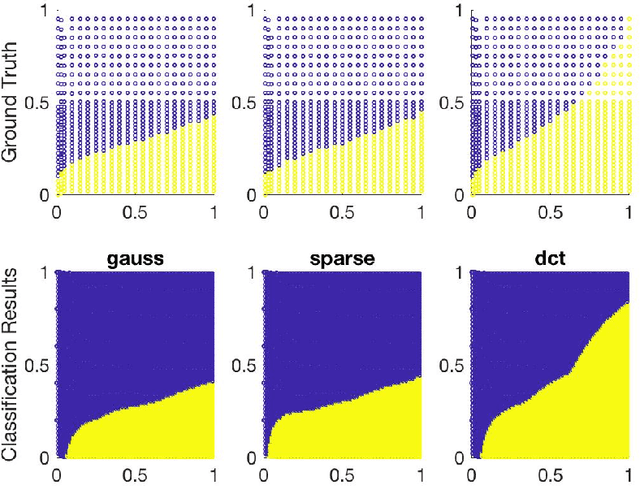

Machine learning algorithms typically rely on optimization subroutines and are well-known to provide very effective outcomes for many types of problems. Here, we flip the reliance and ask the reverse question: can machine learning algorithms lead to more effective outcomes for optimization problems? Our goal is to train machine learning methods to automatically improve the performance of optimization and signal processing algorithms. As a proof of concept, we use our approach to improve two popular data processing subroutines in data science: stochastic gradient descent and greedy methods in compressed sensing. We provide experimental results that demonstrate the answer is ``yes'', machine learning algorithms do lead to more effective outcomes for optimization problems, and show the future potential for this research direction.
Analysis of Fast Structured Dictionary Learning
May 31, 2018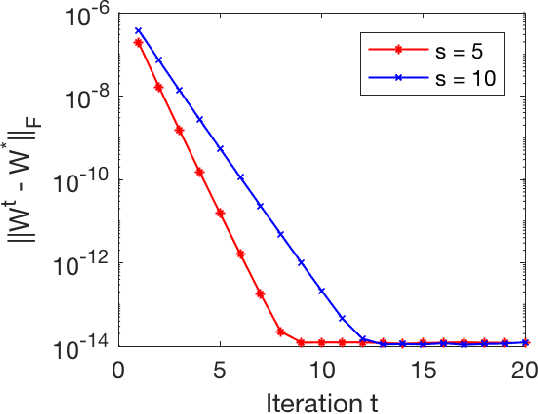
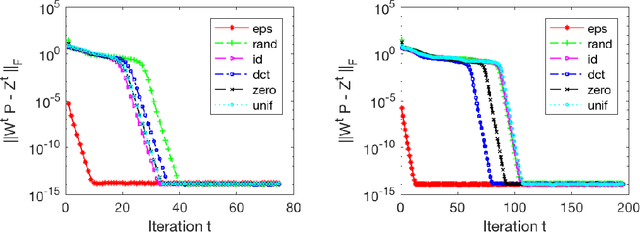
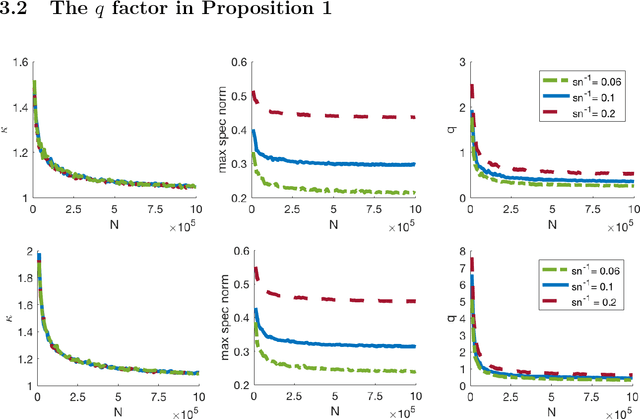
Sparsity-based models and techniques have been exploited in many signal processing and imaging applications. Data-driven methods based on dictionary and transform learning enable learning rich image features from data, and can outperform analytical models. In particular, alternating optimization algorithms for dictionary learning have been popular. In this work, we focus on alternating minimization for a specific structured unitary operator learning problem, and provide a convergence analysis. While the algorithm converges to the critical points of the problem generally, our analysis establishes under mild assumptions, the local linear convergence of the algorithm to the underlying generating model of the data. Analysis and numerical simulations show that our assumptions hold well for standard probabilistic data models. In practice, the algorithm is robust to initialization.
Analysis of Fast Alternating Minimization for Structured Dictionary Learning
Feb 01, 2018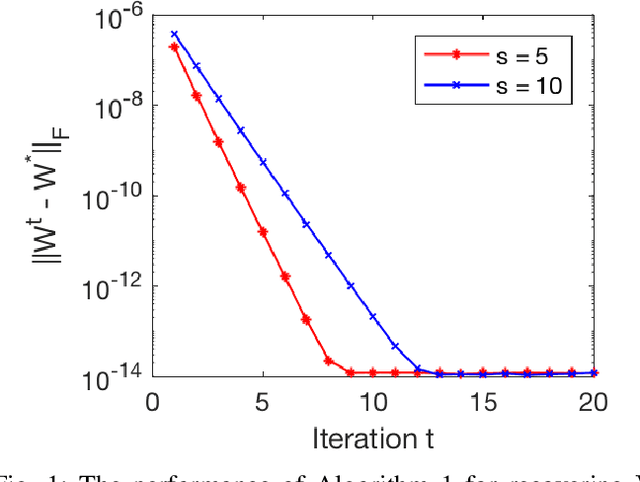
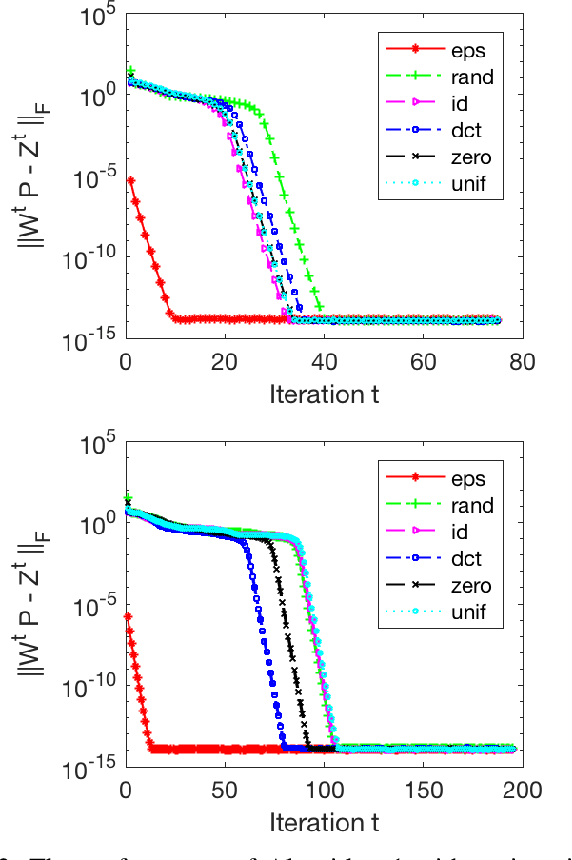
Methods exploiting sparsity have been popular in imaging and signal processing applications including compression, denoising, and imaging inverse problems. Data-driven approaches such as dictionary learning and transform learning enable one to discover complex image features from datasets and provide promising performance over analytical models. Alternating minimization algorithms have been particularly popular in dictionary or transform learning. In this work, we study the properties of alternating minimization for structured (unitary) sparsifying operator learning. While the algorithm converges to the stationary points of the non-convex problem in general, we prove rapid local linear convergence to the underlying generative model under mild assumptions. Our experiments show that the unitary operator learning algorithm is robust to initialization.
Improving Image Clustering using Sparse Text and the Wisdom of the Crowds
May 08, 2014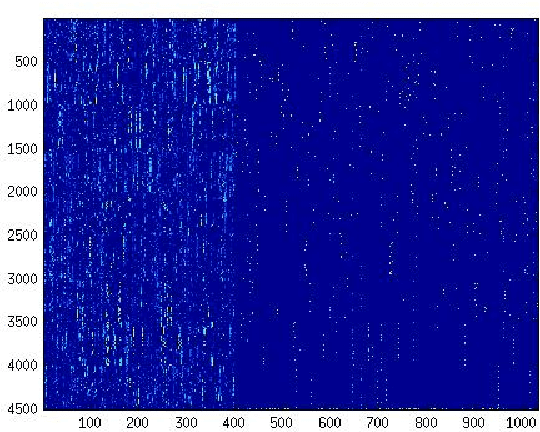

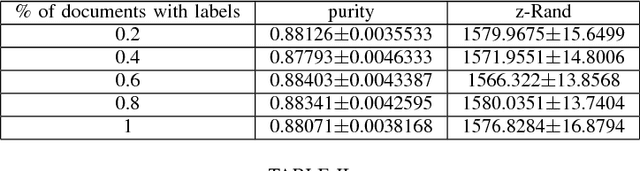
We propose a method to improve image clustering using sparse text and the wisdom of the crowds. In particular, we present a method to fuse two different kinds of document features, image and text features, and use a common dictionary or "wisdom of the crowds" as the connection between the two different kinds of documents. With the proposed fusion matrix, we use topic modeling via non-negative matrix factorization to cluster documents.