 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairEnergy: Contribution-Based Fairness meets Energy Efficiency in Federated Learning
Nov 19, 2025Federated learning (FL) enables collaborative model training across distributed devices while preserving data privacy. However, balancing energy efficiency and fair participation while ensuring high model accuracy remains challenging in wireless edge systems due to heterogeneous resources, unequal client contributions, and limited communication capacity. To address these challenges, we propose FairEnergy, a fairness-aware energy minimization framework that integrates a contribution score capturing both the magnitude of updates and their compression ratio into the joint optimization of device selection, bandwidth allocation, and compression level. The resulting mixed-integer non-convex problem is solved by relaxing binary selection variables and applying Lagrangian decomposition to handle global bandwidth coupling, followed by per-device subproblem optimization. Experiments on non-IID data show that FairEnergy achieves higher accuracy while reducing energy consumption by up to 79\% compared to baseline strategies.
If You Want to Be Robust, Be Wary of Initialization
Oct 26, 2025Graph Neural Networks (GNNs) have demonstrated remarkable performance across a spectrum of graph-related tasks, however concerns persist regarding their vulnerability to adversarial perturbations. While prevailing defense strategies focus primarily on pre-processing techniques and adaptive message-passing schemes, this study delves into an under-explored dimension: the impact of weight initialization and associated hyper-parameters, such as training epochs, on a model's robustness. We introduce a theoretical framework bridging the connection between initialization strategies and a network's resilience to adversarial perturbations. Our analysis reveals a direct relationship between initial weights, number of training epochs and the model's vulnerability, offering new insights into adversarial robustness beyond conventional defense mechanisms. While our primary focus is on GNNs, we extend our theoretical framework, providing a general upper-bound applicable to Deep Neural Networks. Extensive experiments, spanning diverse models and real-world datasets subjected to various adversarial attacks, validate our findings. We illustrate that selecting appropriate initialization not only ensures performance on clean datasets but also enhances model robustness against adversarial perturbations, with observed gaps of up to 50\% compared to alternative initialization approaches.
Energy Efficient Aerial RIS: Phase Shift Optimization and Trajectory Design
Jul 25, 2024Reconfigurable Intelligent Surface (RIS) technology has gained significant attention due to its ability to enhance the performance of wireless communication systems. The main advantage of RIS is that it can be strategically placed in the environment to control wireless signals, enabling improvements in coverage, capacity, and energy efficiency. In this paper, we investigate a scenario in which a drone, equipped with a RIS, travels from an initial point to a target destination. In this scenario, the aerial RIS (ARIS) is deployed to establish a direct link between the base station and obstructed users. Our objective is to maximize the energy efficiency of the ARIS while taking into account its dynamic model including its velocity and acceleration along with the phase shift of the RIS. To this end, we formulate the energy efficiency problem under the constraints of the dynamic model of the drone. The studied problem is challenging to solve. To address this, we proceed as follows. First, we introduce an efficient solution that involves decoupling the phase shift optimization and the trajectory design. Specifically, the closed-form expression of the phase-shift is obtained using a convex approximation, which is subsequently integrated into the trajectory design problem. We then employ tools inspired by economic model predictive control (EMPC) to solve the resulting trajectory optimization. Our simulation results show a significant improvement in energy efficiency against the scenario where the dynamic model of the UAV is ignored.
Joint Probability Selection and Power Allocation for Federated Learning
Jan 15, 2024



In this paper, we study the performance of federated learning over wireless networks, where devices with a limited energy budget train a machine learning model. The federated learning performance depends on the selection of the clients participating in the learning at each round. Most existing studies suggest deterministic approaches for the client selection, resulting in challenging optimization problems that are usually solved using heuristics, and therefore without guarantees on the quality of the final solution. We formulate a new probabilistic approach to jointly select clients and allocate power optimally so that the expected number of participating clients is maximized. To solve the problem, a new alternating algorithm is proposed, where at each step, the closed-form solutions for user selection probabilities and power allocations are obtained. Our numerical results show that the proposed approach achieves a significant performance in terms of energy consumption, completion time and accuracy as compared to the studied benchmarks.
Demystifying the Myths and Legends of Nonconvex Convergence of SGD
Oct 19, 2023
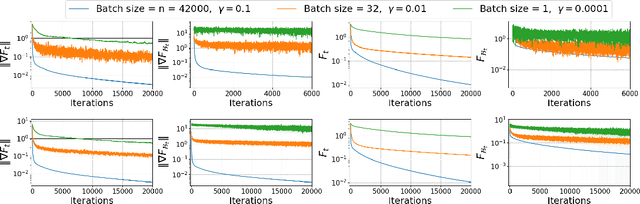
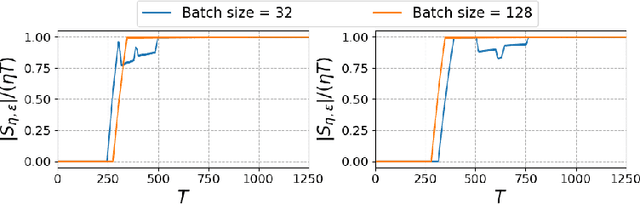

Stochastic gradient descent (SGD) and its variants are the main workhorses for solving large-scale optimization problems with nonconvex objective functions. Although the convergence of SGDs in the (strongly) convex case is well-understood, their convergence for nonconvex functions stands on weak mathematical foundations. Most existing studies on the nonconvex convergence of SGD show the complexity results based on either the minimum of the expected gradient norm or the functional sub-optimality gap (for functions with extra structural property) by searching the entire range of iterates. Hence the last iterations of SGDs do not necessarily maintain the same complexity guarantee. This paper shows that an $\epsilon$-stationary point exists in the final iterates of SGDs, given a large enough total iteration budget, $T$, not just anywhere in the entire range of iterates -- a much stronger result than the existing one. Additionally, our analyses allow us to measure the density of the $\epsilon$-stationary points in the final iterates of SGD, and we recover the classical $O(\frac{1}{\sqrt{T}})$ asymptotic rate under various existing assumptions on the objective function and the bounds on the stochastic gradient. As a result of our analyses, we addressed certain myths and legends related to the nonconvex convergence of SGD and posed some thought-provoking questions that could set new directions for research.
Ensemble DNN for Age-of-Information Minimization in UAV-assisted Networks
Sep 06, 2023This paper addresses the problem of Age-of-Information (AoI) in UAV-assisted networks. Our objective is to minimize the expected AoI across devices by optimizing UAVs' stopping locations and device selection probabilities. To tackle this problem, we first derive a closed-form expression of the expected AoI that involves the probabilities of selection of devices. Then, we formulate the problem as a non-convex minimization subject to quality of service constraints. Since the problem is challenging to solve, we propose an Ensemble Deep Neural Network (EDNN) based approach which takes advantage of the dual formulation of the studied problem. Specifically, the Deep Neural Networks (DNNs) in the ensemble are trained in an unsupervised manner using the Lagrangian function of the studied problem. Our experiments show that the proposed EDNN method outperforms traditional DNNs in reducing the expected AoI, achieving a remarkable reduction of $29.5\%$.
A Note on Randomized Kaczmarz Algorithm for Solving Doubly-Noisy Linear Systems
Aug 31, 2023
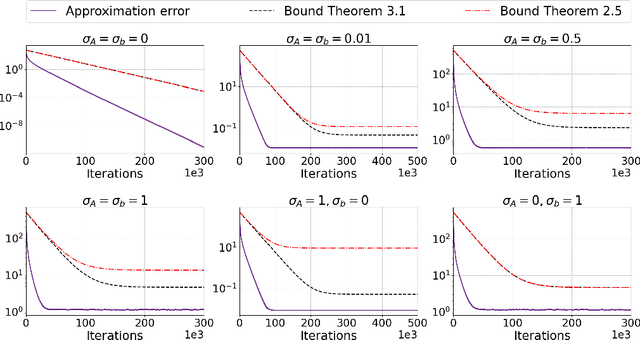
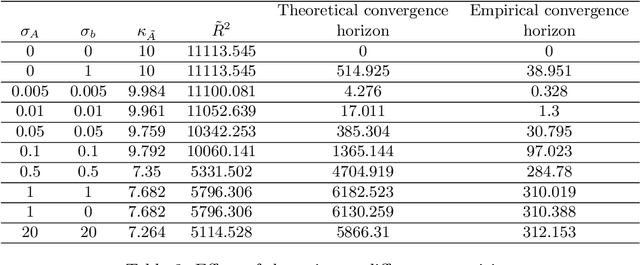
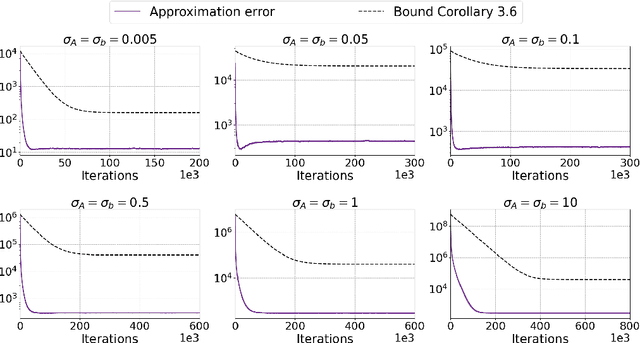
Large-scale linear systems, $Ax=b$, frequently arise in practice and demand effective iterative solvers. Often, these systems are noisy due to operational errors or faulty data-collection processes. In the past decade, the randomized Kaczmarz (RK) algorithm has been studied extensively as an efficient iterative solver for such systems. However, the convergence study of RK in the noisy regime is limited and considers measurement noise in the right-hand side vector, $b$. Unfortunately, in practice, that is not always the case; the coefficient matrix $A$ can also be noisy. In this paper, we analyze the convergence of RK for noisy linear systems when the coefficient matrix, $A$, is corrupted with both additive and multiplicative noise, along with the noisy vector, $b$. In our analyses, the quantity $\tilde R=\| \tilde A^{\dagger} \|_2^2 \|\tilde A \|_F^2$ influences the convergence of RK, where $\tilde A$ represents a noisy version of $A$. We claim that our analysis is robust and realistically applicable, as we do not require information about the noiseless coefficient matrix, $A$, and considering different conditions on noise, we can control the convergence of RK. We substantiate our theoretical findings by performing comprehensive numerical experiments.
Muti-Agent Proximal Policy Optimization For Data Freshness in UAV-assisted Networks
Mar 15, 2023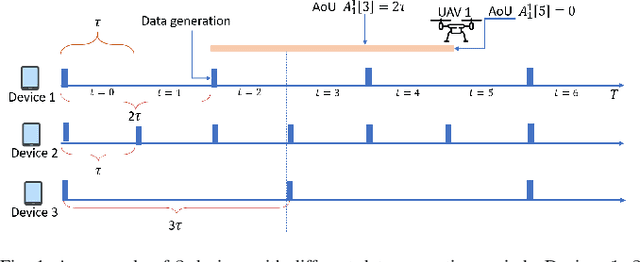
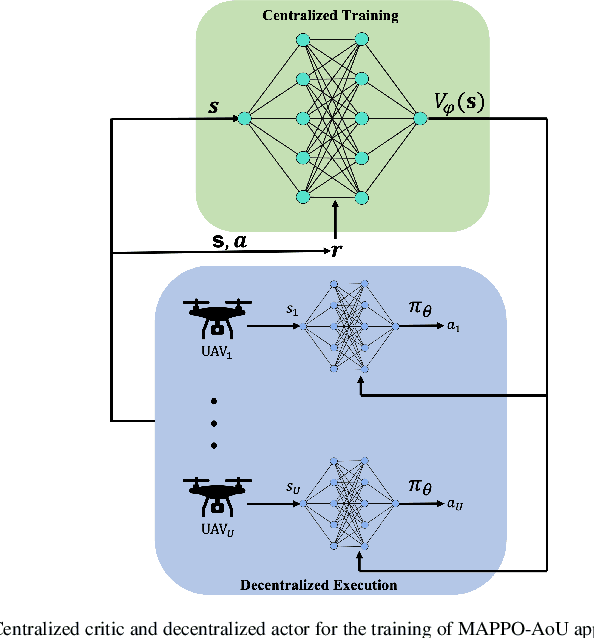
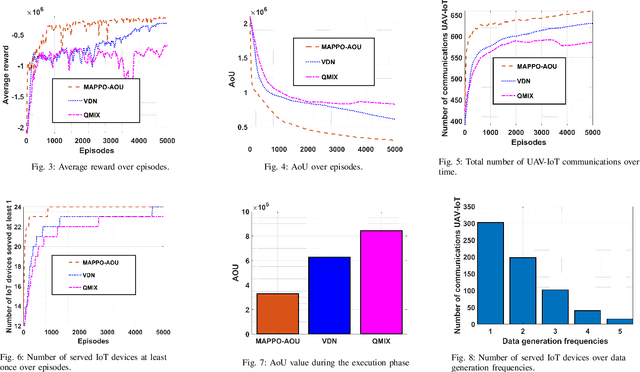
Unmanned aerial vehicles (UAVs) are seen as a promising technology to perform a wide range of tasks in wireless communication networks. In this work, we consider the deployment of a group of UAVs to collect the data generated by IoT devices. Specifically, we focus on the case where the collected data is time-sensitive, and it is critical to maintain its timeliness. Our objective is to optimally design the UAVs' trajectories and the subsets of visited IoT devices such as the global Age-of-Updates (AoU) is minimized. To this end, we formulate the studied problem as a mixed-integer nonlinear programming (MINLP) under time and quality of service constraints. To efficiently solve the resulting optimization problem, we investigate the cooperative Multi-Agent Reinforcement Learning (MARL) framework and propose an RL approach based on the popular on-policy Reinforcement Learning (RL) algorithm: Policy Proximal Optimization (PPO). Our approach leverages the centralized training decentralized execution (CTDE) framework where the UAVs learn their optimal policies while training a centralized value function. Our simulation results show that the proposed MAPPO approach reduces the global AoU by at least a factor of 1/2 compared to conventional off-policy reinforcement learning approaches.
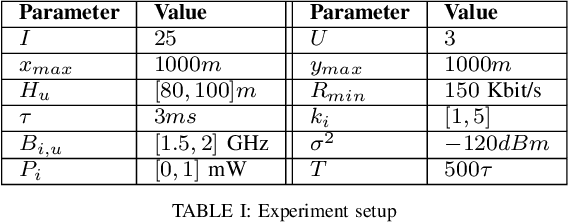
Linear Scalarization for Byzantine-robust learning on non-IID data
Oct 15, 2022
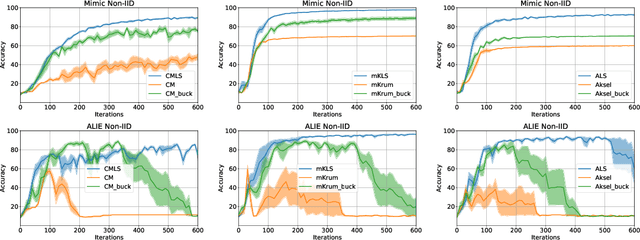
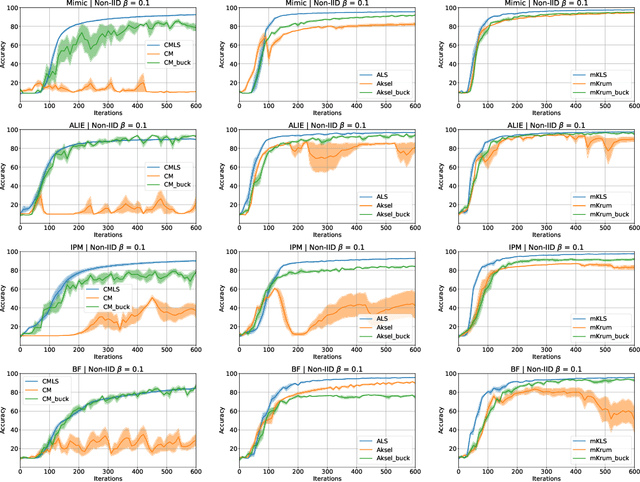
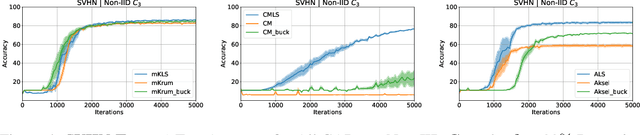
In this work we study the problem of Byzantine-robust learning when data among clients is heterogeneous. We focus on poisoning attacks targeting the convergence of SGD. Although this problem has received great attention; the main Byzantine defenses rely on the IID assumption causing them to fail when data distribution is non-IID even with no attack. We propose the use of Linear Scalarization (LS) as an enhancing method to enable current defenses to circumvent Byzantine attacks in the non-IID setting. The LS method is based on the incorporation of a trade-off vector that penalizes the suspected malicious clients. Empirical analysis corroborates that the proposed LS variants are viable in the IID setting. For mild to strong non-IID data splits, LS is either comparable or outperforming current approaches under state-of-the-art Byzantine attack scenarios.
Personalized Federated Learning with Communication Compression
Sep 12, 2022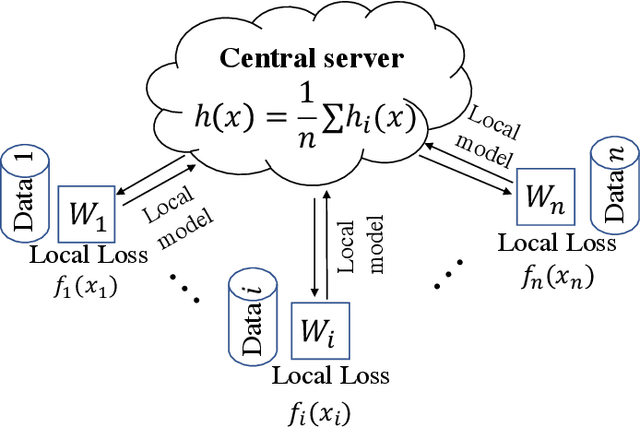
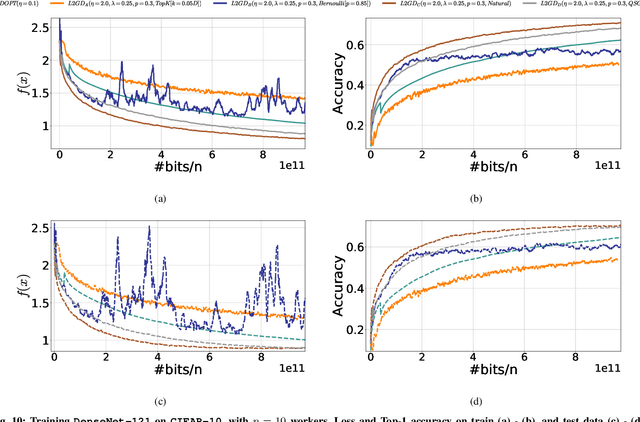
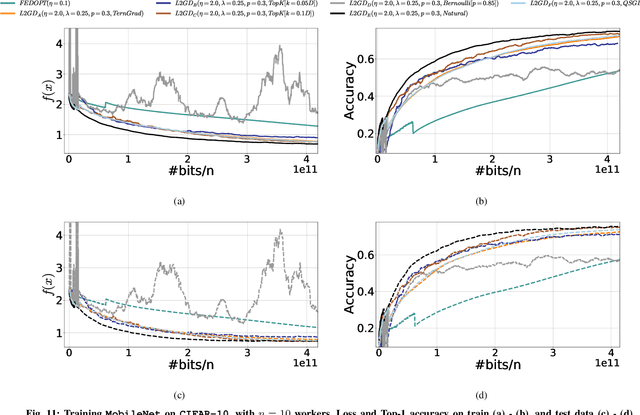
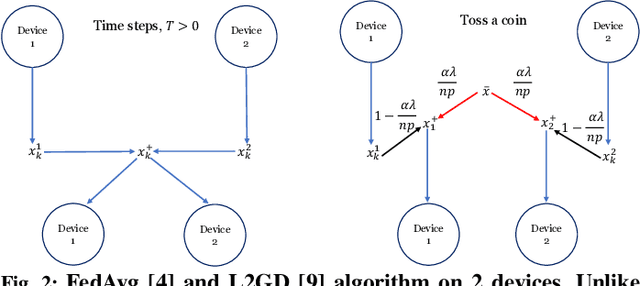
In contrast to training traditional machine learning (ML) models in data centers, federated learning (FL) trains ML models over local datasets contained on resource-constrained heterogeneous edge devices. Existing FL algorithms aim to learn a single global model for all participating devices, which may not be helpful to all devices participating in the training due to the heterogeneity of the data across the devices. Recently, Hanzely and Richt\'{a}rik (2020) proposed a new formulation for training personalized FL models aimed at balancing the trade-off between the traditional global model and the local models that could be trained by individual devices using their private data only. They derived a new algorithm, called Loopless Gradient Descent (L2GD), to solve it and showed that this algorithms leads to improved communication complexity guarantees in regimes when more personalization is required. In this paper, we equip their L2GD algorithm with a bidirectional compression mechanism to further reduce the communication bottleneck between the local devices and the server. Unlike other compression-based algorithms used in the FL-setting, our compressed L2GD algorithm operates on a probabilistic communication protocol, where communication does not happen on a fixed schedule. Moreover, our compressed L2GD algorithm maintains a similar convergence rate as vanilla SGD without compression. To empirically validate the efficiency of our algorithm, we perform diverse numerical experiments on both convex and non-convex problems and using various compression techniques.