 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsemble DNN for Age-of-Information Minimization in UAV-assisted Networks
Sep 06, 2023This paper addresses the problem of Age-of-Information (AoI) in UAV-assisted networks. Our objective is to minimize the expected AoI across devices by optimizing UAVs' stopping locations and device selection probabilities. To tackle this problem, we first derive a closed-form expression of the expected AoI that involves the probabilities of selection of devices. Then, we formulate the problem as a non-convex minimization subject to quality of service constraints. Since the problem is challenging to solve, we propose an Ensemble Deep Neural Network (EDNN) based approach which takes advantage of the dual formulation of the studied problem. Specifically, the Deep Neural Networks (DNNs) in the ensemble are trained in an unsupervised manner using the Lagrangian function of the studied problem. Our experiments show that the proposed EDNN method outperforms traditional DNNs in reducing the expected AoI, achieving a remarkable reduction of $29.5\%$.
Muti-Agent Proximal Policy Optimization For Data Freshness in UAV-assisted Networks
Mar 15, 2023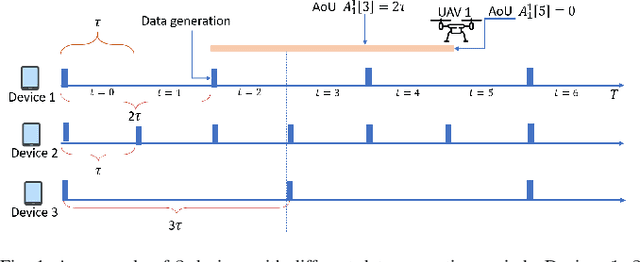
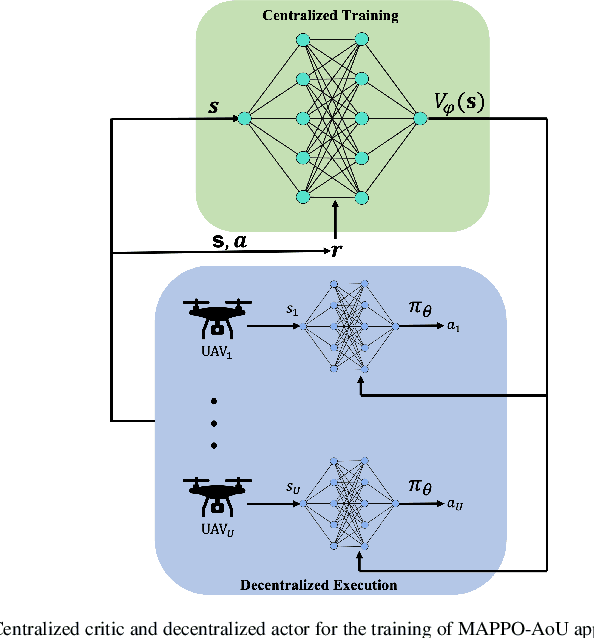
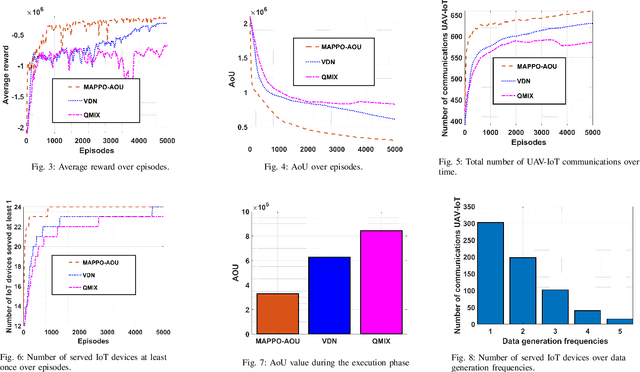
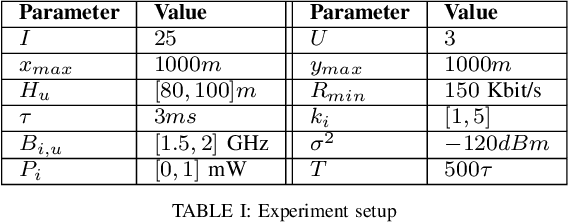
Unmanned aerial vehicles (UAVs) are seen as a promising technology to perform a wide range of tasks in wireless communication networks. In this work, we consider the deployment of a group of UAVs to collect the data generated by IoT devices. Specifically, we focus on the case where the collected data is time-sensitive, and it is critical to maintain its timeliness. Our objective is to optimally design the UAVs' trajectories and the subsets of visited IoT devices such as the global Age-of-Updates (AoU) is minimized. To this end, we formulate the studied problem as a mixed-integer nonlinear programming (MINLP) under time and quality of service constraints. To efficiently solve the resulting optimization problem, we investigate the cooperative Multi-Agent Reinforcement Learning (MARL) framework and propose an RL approach based on the popular on-policy Reinforcement Learning (RL) algorithm: Policy Proximal Optimization (PPO). Our approach leverages the centralized training decentralized execution (CTDE) framework where the UAVs learn their optimal policies while training a centralized value function. Our simulation results show that the proposed MAPPO approach reduces the global AoU by at least a factor of 1/2 compared to conventional off-policy reinforcement learning approaches.