 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAP: KV-Cache Compression via RoPE-Aligned Pruning
Feb 01, 2026Long-context inference in large language models is increasingly bottlenecked by the memory and compute cost of the KV-Cache. Low-rank factorization compresses KV projections by writing $W \approx A * B$, where A produces latent KV states and B can be absorbed into downstream weights. In modern RoPE-based LLMs, this absorption fails: RoPE forces latent KV states to be reconstructed to full dimension, reintroducing substantial memory and compute overhead. We propose RoPE-Aligned Pruning (RAP), which prunes entire RoPE-aligned column pairs to preserve RoPE's 2x2 rotation structure, restore B absorption, and eliminate reconstruction. Our evaluation on LLaMA-3-8B and Mistral-7B shows that RAP enables joint reduction of KV-Cache, attention parameters, and FLOPs by 20-30%, all at once, while maintaining strong accuracy. Notably, RAP reduces attention latency to 83% (prefill) and 77% (decode) of baseline.
FOCUS: DLLMs Know How to Tame Their Compute Bound
Jan 30, 2026Diffusion Large Language Models (DLLMs) offer a compelling alternative to Auto-Regressive models, but their deployment is constrained by high decoding cost. In this work, we identify a key inefficiency in DLLM decoding: while computation is parallelized over token blocks, only a small subset of tokens is decodable at each diffusion step, causing most compute to be wasted on non-decodable tokens. We further observe a strong correlation between attention-derived token importance and token-wise decoding probability. Based on this insight, we propose FOCUS -- an inference system designed for DLLMs. By dynamically focusing computation on decodable tokens and evicting non-decodable ones on-the-fly, FOCUS increases the effective batch size, alleviating compute limitations and enabling scalable throughput. Empirical evaluations demonstrate that FOCUS achieves up to 3.52$\times$ throughput improvement over the production-grade engine LMDeploy, while preserving or improving generation quality across multiple benchmarks. The FOCUS system is publicly available on GitHub: https://github.com/sands-lab/FOCUS.
MAESTRO: Multi-Agent Evaluation Suite for Testing, Reliability, and Observability
Jan 01, 2026We present MAESTRO, an evaluation suite for the testing, reliability, and observability of LLM-based MAS. MAESTRO standardizes MAS configuration and execution through a unified interface, supports integrating both native and third-party MAS via a repository of examples and lightweight adapters, and exports framework-agnostic execution traces together with system-level signals (e.g., latency, cost, and failures). We instantiate MAESTRO with 12 representative MAS spanning popular agentic frameworks and interaction patterns, and conduct controlled experiments across repeated runs, backend models, and tool configurations. Our case studies show that MAS executions can be structurally stable yet temporally variable, leading to substantial run-to-run variance in performance and reliability. We further find that MAS architecture is the dominant driver of resource profiles, reproducibility, and cost-latency-accuracy trade-off, often outweighing changes in backend models or tool settings. Overall, MAESTRO enables systematic evaluation and provides empirical guidance for designing and optimizing agentic systems.
Query-based Knowledge Transfer for Heterogeneous Learning Environments
Apr 12, 2025Decentralized collaborative learning under data heterogeneity and privacy constraints has rapidly advanced. However, existing solutions like federated learning, ensembles, and transfer learning, often fail to adequately serve the unique needs of clients, especially when local data representation is limited. To address this issue, we propose a novel framework called Query-based Knowledge Transfer (QKT) that enables tailored knowledge acquisition to fulfill specific client needs without direct data exchange. QKT employs a data-free masking strategy to facilitate communication-efficient query-focused knowledge transfer while refining task-specific parameters to mitigate knowledge interference and forgetting. Our experiments, conducted on both standard and clinical benchmarks, show that QKT significantly outperforms existing collaborative learning methods by an average of 20.91\% points in single-class query settings and an average of 14.32\% points in multi-class query scenarios. Further analysis and ablation studies reveal that QKT effectively balances the learning of new and existing knowledge, showing strong potential for its application in decentralized learning.
Protecting Confidentiality, Privacy and Integrity in Collaborative Learning
Dec 11, 2024



A collaboration between dataset owners and model owners is needed to facilitate effective machine learning (ML) training. During this collaboration, however, dataset owners and model owners want to protect the confidentiality of their respective assets (i.e., datasets, models and training code), with the dataset owners also caring about the privacy of individual users whose data is in their datasets. Existing solutions either provide limited confidentiality for models and training code, or suffer from privacy issues due to collusion. We present Citadel++, a scalable collaborative ML training system designed to simultaneously protect the confidentiality of datasets, models and training code, as well as the privacy of individual users. Citadel++ enhances differential privacy techniques to safeguard the privacy of individual user data while maintaining model utility. By employing Virtual Machine-level Trusted Execution Environments (TEEs) and improved integrity protection techniques through various OS-level mechanisms, Citadel++ effectively preserves the confidentiality of datasets, models and training code, and enforces our privacy mechanisms even when the models and training code have been maliciously designed. Our experiments show that Citadel++ provides privacy, model utility and performance while adhering to confidentiality and privacy requirements of dataset owners and model owners, outperforming the state-of-the-art privacy-preserving training systems by up to 543x on CPU and 113x on GPU TEEs.
ACING: Actor-Critic for Instruction Learning in Black-Box Large Language Models
Nov 19, 2024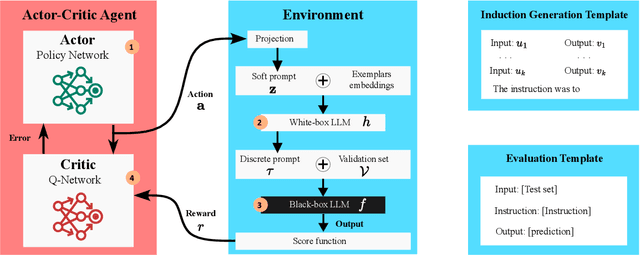

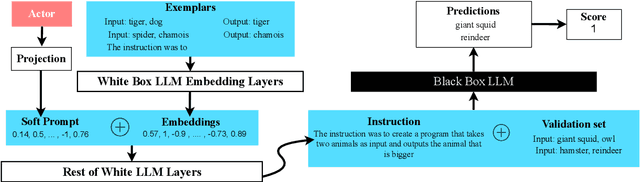
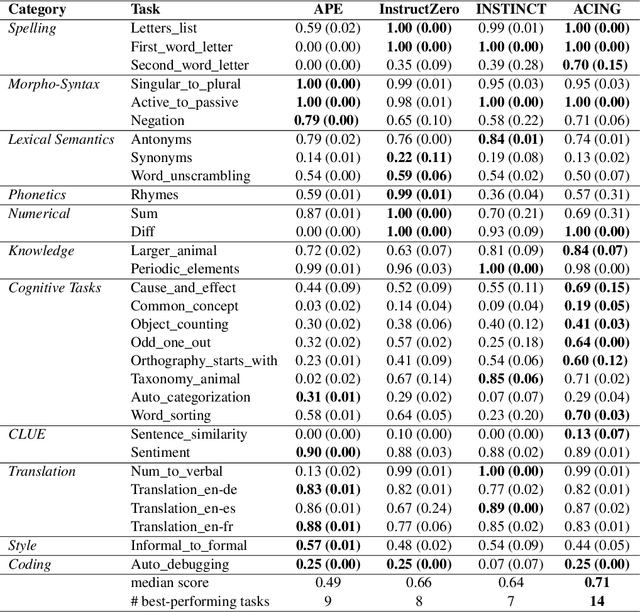
The effectiveness of Large Language Models (LLMs) in solving tasks vastly depends on the quality of the instructions, which often require fine-tuning through extensive human effort. This highlights the need for automated instruction optimization; however, this optimization is particularly challenging when dealing with black-box LLMs, where model parameters and gradients remain inaccessible. We propose ACING, a task-specific prompt optimization approach framed as a stateless continuous-action Reinforcement Learning (RL) problem, known as the continuum bandit setting. ACING leverages an actor-critic-based method to optimize prompts, learning from non-differentiable reward signals. We validate ACING by optimizing prompts for ChatGPT on 30 instruction-based tasks. ACING consistently outperforms baseline methods, achieving a median score improvement of 10 percentage points. Furthermore, ACING not only recovers but also surpasses human-crafted expert instructions, achieving up to a 39 percentage point improvement against human benchmarks.
Where is the Testbed for my Federated Learning Research?
Jul 19, 2024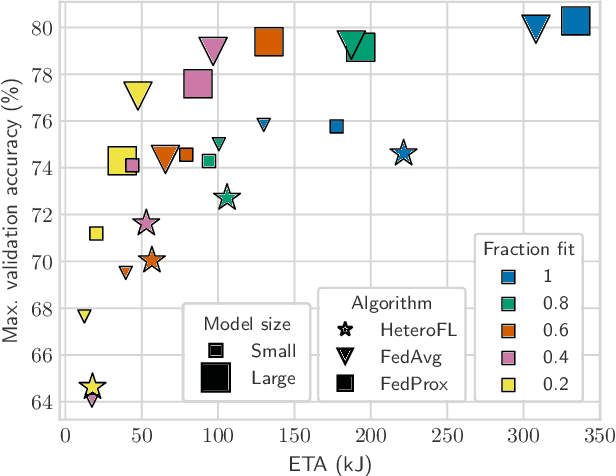
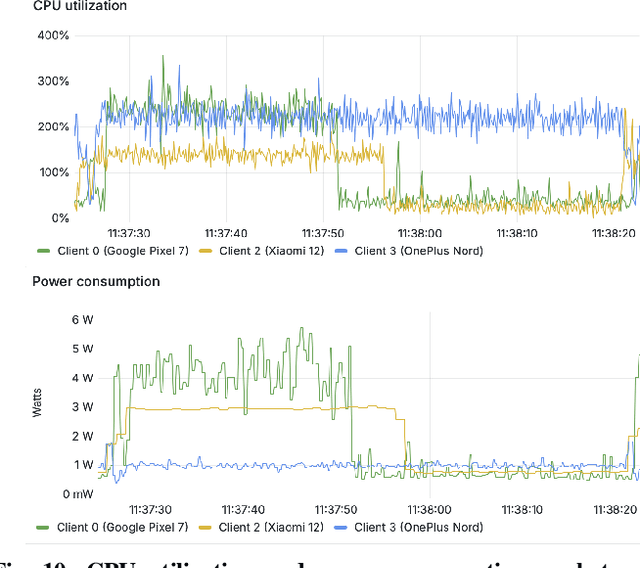
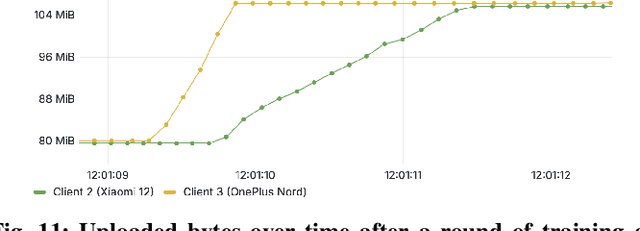
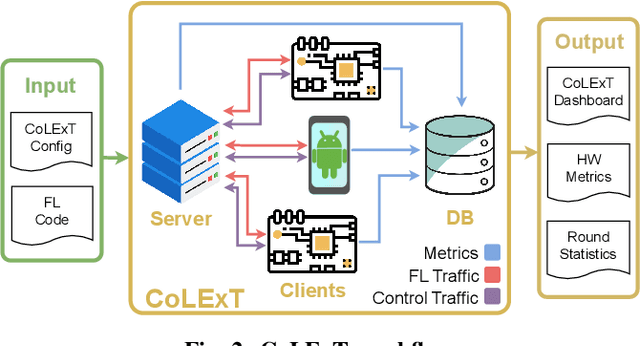
Progressing beyond centralized AI is of paramount importance, yet, distributed AI solutions, in particular various federated learning (FL) algorithms, are often not comprehensively assessed, which prevents the research community from identifying the most promising approaches and practitioners from being convinced that a certain solution is deployment-ready. The largest hurdle towards FL algorithm evaluation is the difficulty of conducting real-world experiments over a variety of FL client devices and different platforms, with different datasets and data distribution, all while assessing various dimensions of algorithm performance, such as inference accuracy, energy consumption, and time to convergence, to name a few. In this paper, we present CoLExT, a real-world testbed for FL research. CoLExT is designed to streamline experimentation with custom FL algorithms in a rich testbed configuration space, with a large number of heterogeneous edge devices, ranging from single-board computers to smartphones, and provides real-time collection and visualization of a variety of metrics through automatic instrumentation. According to our evaluation, porting FL algorithms to CoLExT requires minimal involvement from the developer, and the instrumentation introduces minimal resource usage overhead. Furthermore, through an initial investigation involving popular FL algorithms running on CoLExT, we reveal previously unknown trade-offs, inefficiencies, and programming bugs.
Towards a Flexible and High-Fidelity Approach to Distributed DNN Training Emulation
May 05, 2024



We propose NeuronaBox, a flexible, user-friendly, and high-fidelity approach to emulate DNN training workloads. We argue that to accurately observe performance, it is possible to execute the training workload on a subset of real nodes and emulate the networked execution environment along with the collective communication operations. Initial results from a proof-of-concept implementation show that NeuronaBox replicates the behavior of actual systems with high accuracy, with an error margin of less than 1% between the emulated measurements and the real system.
Practical Insights into Knowledge Distillation for Pre-Trained Models
Feb 22, 2024



This research investigates the enhancement of knowledge distillation (KD) processes in pre-trained models, an emerging field in knowledge transfer with significant implications for distributed training and federated learning environments. These environments benefit from reduced communication demands and accommodate various model architectures. Despite the adoption of numerous KD approaches for transferring knowledge among pre-trained models, a comprehensive understanding of KD's application in these scenarios is lacking. Our study conducts an extensive comparison of multiple KD techniques, including standard KD, tuned KD (via optimized temperature and weight parameters), deep mutual learning, and data partitioning KD. We assess these methods across various data distribution strategies to identify the most effective contexts for each. Through detailed examination of hyperparameter tuning, informed by extensive grid search evaluations, we pinpoint when adjustments are crucial to enhance model performance. This paper sheds light on optimal hyperparameter settings for distinct data partitioning scenarios and investigates KD's role in improving federated learning by minimizing communication rounds and expediting the training process. By filling a notable void in current research, our findings serve as a practical framework for leveraging KD in pre-trained models within collaborative and federated learning frameworks.
Flashback: Understanding and Mitigating Forgetting in Federated Learning
Feb 08, 2024In Federated Learning (FL), forgetting, or the loss of knowledge across rounds, hampers algorithm convergence, particularly in the presence of severe data heterogeneity among clients. This study explores the nuances of this issue, emphasizing the critical role of forgetting in FL's inefficient learning within heterogeneous data contexts. Knowledge loss occurs in both client-local updates and server-side aggregation steps; addressing one without the other fails to mitigate forgetting. We introduce a metric to measure forgetting granularly, ensuring distinct recognition amid new knowledge acquisition. Leveraging these insights, we propose Flashback, an FL algorithm with a dynamic distillation approach that is used to regularize the local models, and effectively aggregate their knowledge. Across different benchmarks, Flashback outperforms other methods, mitigates forgetting, and achieves faster round-to-target-accuracy, by converging in 6 to 16 rounds.