 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere is the Testbed for my Federated Learning Research?
Jul 19, 2024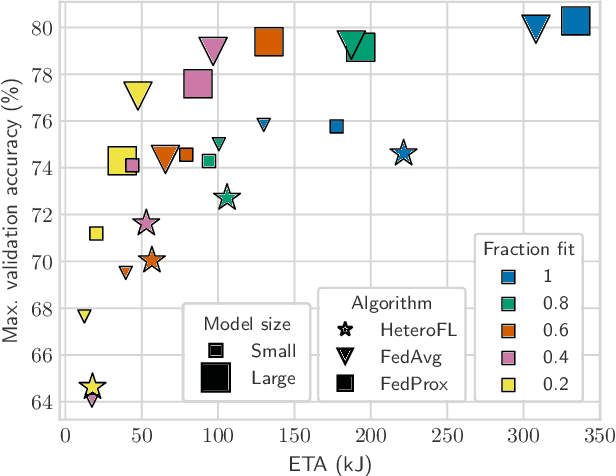
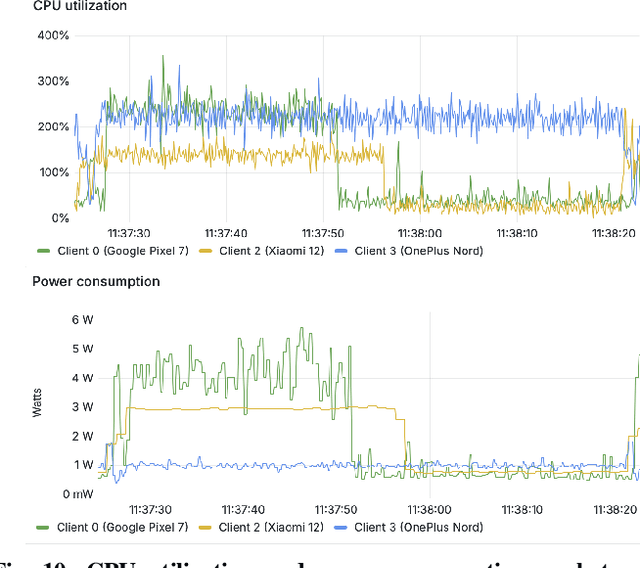
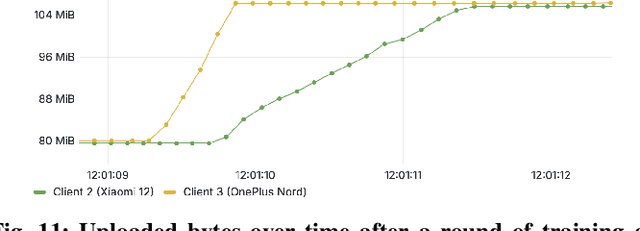
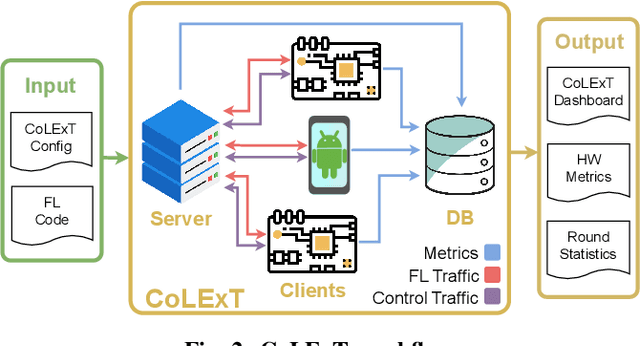
Progressing beyond centralized AI is of paramount importance, yet, distributed AI solutions, in particular various federated learning (FL) algorithms, are often not comprehensively assessed, which prevents the research community from identifying the most promising approaches and practitioners from being convinced that a certain solution is deployment-ready. The largest hurdle towards FL algorithm evaluation is the difficulty of conducting real-world experiments over a variety of FL client devices and different platforms, with different datasets and data distribution, all while assessing various dimensions of algorithm performance, such as inference accuracy, energy consumption, and time to convergence, to name a few. In this paper, we present CoLExT, a real-world testbed for FL research. CoLExT is designed to streamline experimentation with custom FL algorithms in a rich testbed configuration space, with a large number of heterogeneous edge devices, ranging from single-board computers to smartphones, and provides real-time collection and visualization of a variety of metrics through automatic instrumentation. According to our evaluation, porting FL algorithms to CoLExT requires minimal involvement from the developer, and the instrumentation introduces minimal resource usage overhead. Furthermore, through an initial investigation involving popular FL algorithms running on CoLExT, we reveal previously unknown trade-offs, inefficiencies, and programming bugs.
REPA: Client Clustering without Training and Data Labels for Improved Federated Learning in Non-IID Settings
Sep 25, 2023



Clustering clients into groups that exhibit relatively homogeneous data distributions represents one of the major means of improving the performance of federated learning (FL) in non-independent and identically distributed (non-IID) data settings. Yet, the applicability of current state-of-the-art approaches remains limited as these approaches cluster clients based on information, such as the evolution of local model parameters, that is only obtainable through actual on-client training. On the other hand, there is a need to make FL models available to clients who are not able to perform the training themselves, as they do not have the processing capabilities required for training, or simply want to use the model without participating in the training. Furthermore, the existing alternative approaches that avert the training still require that individual clients have a sufficient amount of labeled data upon which the clustering is based, essentially assuming that each client is a data annotator. In this paper, we present REPA, an approach to client clustering in non-IID FL settings that requires neither training nor labeled data collection. REPA uses a novel supervised autoencoder-based method to create embeddings that profile a client's underlying data-generating processes without exposing the data to the server and without requiring local training. Our experimental analysis over three different datasets demonstrates that REPA delivers state-of-the-art model performance while expanding the applicability of cluster-based FL to previously uncovered use cases.