 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMMAI Gym for Science: Training Liquid Foundation Models for Drug Discovery
Mar 03, 2026General-purpose large language models (LLMs) that rely on in-context learning do not reliably deliver the scientific understanding and performance required for drug discovery tasks. Simply increasing model size or introducing reasoning tokens does not yield significant performance gains. To address this gap, we introduce the MMAI Gym for Science, a one-stop shop molecular data formats and modalities as well as task-specific reasoning, training, and benchmarking recipes designed to teach foundation models the 'language of molecules' in order to solve practical drug discovery problems. We use MMAI Gym to train an efficient Liquid Foundation Model (LFM) for these applications, demonstrating that smaller, purpose-trained foundation models can outperform substantially larger general-purpose or specialist models on molecular benchmarks. Across essential drug discovery tasks - including molecular optimization, ADMET property prediction, retrosynthesis, drug-target activity prediction, and functional group reasoning - the resulting model achieves near specialist-level performance and, in the majority of settings, surpasses larger models, while remaining more efficient and broadly applicable in the domain.
When Single Answer Is Not Enough: Rethinking Single-Step Retrosynthesis Benchmarks for LLMs
Feb 03, 2026Recent progress has expanded the use of large language models (LLMs) in drug discovery, including synthesis planning. However, objective evaluation of retrosynthesis performance remains limited. Existing benchmarks and metrics typically rely on published synthetic procedures and Top-K accuracy based on single ground-truth, which does not capture the open-ended nature of real-world synthesis planning. We propose a new benchmarking framework for single-step retrosynthesis that evaluates both general-purpose and chemistry-specialized LLMs using ChemCensor, a novel metric for chemical plausibility. By emphasizing plausibility over exact match, this approach better aligns with human synthesis planning practices. We also introduce CREED, a novel dataset comprising millions of ChemCensor-validated reaction records for LLM training, and use it to train a model that improves over the LLM baselines under this benchmark.
Hessian of Perplexity for Large Language Models by PyTorch autograd (Open Source)
Apr 06, 2025Computing the full Hessian matrix -- the matrix of second-order derivatives for an entire Large Language Model (LLM) is infeasible due to its sheer size. In this technical report, we aim to provide a comprehensive guide on how to accurately compute at least a small portion of the Hessian for LLMs using PyTorch autograd library. We also demonstrate how to compute the full diagonal of the Hessian matrix using multiple samples of vector-Hessian Products (HVPs). We hope that both this guide and the accompanying GitHub code will be valuable resources for practitioners and researchers interested in better understanding the behavior and structure of the Hessian in LLMs.
Thanos: A Block-wise Pruning Algorithm for Efficient Large Language Model Compression
Apr 06, 2025


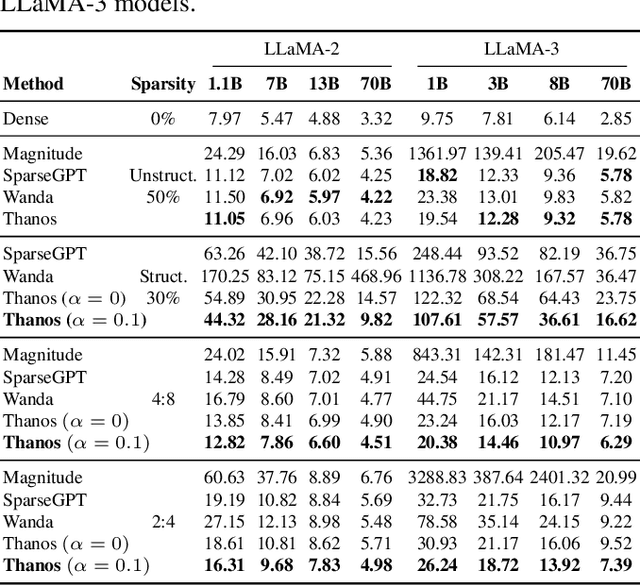
This paper presents Thanos, a novel weight-pruning algorithm designed to reduce the memory footprint and enhance the computational efficiency of large language models (LLMs) by removing redundant weights while maintaining accuracy. Thanos introduces a block-wise pruning strategy with adaptive masks that dynamically adjust to weight importance, enabling flexible sparsity patterns and structured formats, such as $n:m$ sparsity, optimized for hardware acceleration. Experimental evaluations demonstrate that Thanos achieves state-of-the-art performance in structured pruning and outperforms existing methods in unstructured pruning. By providing an efficient and adaptable approach to model compression, Thanos offers a practical solution for deploying large models in resource-constrained environments.
Pushing the Limits of Large Language Model Quantization via the Linearity Theorem
Nov 26, 2024



Quantizing large language models has become a standard way to reduce their memory and computational costs. Typically, existing methods focus on breaking down the problem into individual layer-wise sub-problems, and minimizing per-layer error, measured via various metrics. Yet, this approach currently lacks theoretical justification and the metrics employed may be sub-optimal. In this paper, we present a "linearity theorem" establishing a direct relationship between the layer-wise $\ell_2$ reconstruction error and the model perplexity increase due to quantization. This insight enables two novel applications: (1) a simple data-free LLM quantization method using Hadamard rotations and MSE-optimal grids, dubbed HIGGS, which outperforms all prior data-free approaches such as the extremely popular NF4 quantized format, and (2) an optimal solution to the problem of finding non-uniform per-layer quantization levels which match a given compression constraint in the medium-bitwidth regime, obtained by reduction to dynamic programming. On the practical side, we demonstrate improved accuracy-compression trade-offs on Llama-3.1 and 3.2-family models, as well as on Qwen-family models. Further, we show that our method can be efficiently supported in terms of GPU kernels at various batch sizes, advancing both data-free and non-uniform quantization for LLMs.
PV-Tuning: Beyond Straight-Through Estimation for Extreme LLM Compression
May 23, 2024



There has been significant interest in "extreme" compression of large language models (LLMs), i.e., to 1-2 bits per parameter, which allows such models to be executed efficiently on resource-constrained devices. Existing work focused on improved one-shot quantization techniques and weight representations; yet, purely post-training approaches are reaching diminishing returns in terms of the accuracy-vs-bit-width trade-off. State-of-the-art quantization methods such as QuIP# and AQLM include fine-tuning (part of) the compressed parameters over a limited amount of calibration data; however, such fine-tuning techniques over compressed weights often make exclusive use of straight-through estimators (STE), whose performance is not well-understood in this setting. In this work, we question the use of STE for extreme LLM compression, showing that it can be sub-optimal, and perform a systematic study of quantization-aware fine-tuning strategies for LLMs. We propose PV-Tuning - a representation-agnostic framework that generalizes and improves upon existing fine-tuning strategies, and provides convergence guarantees in restricted cases. On the practical side, when used for 1-2 bit vector quantization, PV-Tuning outperforms prior techniques for highly-performant models such as Llama and Mistral. Using PV-Tuning, we achieve the first Pareto-optimal quantization for Llama 2 family models at 2 bits per parameter.
Shadowheart SGD: Distributed Asynchronous SGD with Optimal Time Complexity Under Arbitrary Computation and Communication Heterogeneity
Feb 07, 2024



We consider nonconvex stochastic optimization problems in the asynchronous centralized distributed setup where the communication times from workers to a server can not be ignored, and the computation and communication times are potentially different for all workers. Using an unbiassed compression technique, we develop a new method-Shadowheart SGD-that provably improves the time complexities of all previous centralized methods. Moreover, we show that the time complexity of Shadowheart SGD is optimal in the family of centralized methods with compressed communication. We also consider the bidirectional setup, where broadcasting from the server to the workers is non-negligible, and develop a corresponding method.
Kimad: Adaptive Gradient Compression with Bandwidth Awareness
Dec 13, 2023



In distributed training, communication often emerges as a bottleneck. In response, we introduce Kimad, a solution that offers adaptive gradient compression. By consistently monitoring bandwidth, Kimad refines compression ratios to match specific neural network layer requirements. Our exhaustive tests and proofs confirm Kimad's outstanding performance, establishing it as a benchmark in adaptive compression for distributed deep learning.